LlamaIndex: la alternativa LangChain que escala LLMs

Introducción: ¿Qué es LlamaIndex?
LlamaIndex es una herramienta de indexación de alto rendimiento diseñada específicamente para ampliar las capacidades de los Modelos de Lenguaje Grande (LLMs). No es solo un optimizador de consultas; es un marco integral que ofrece características avanzadas como síntesis de respuestas, composabilidad y almacenamiento eficiente de datos. Si estás trabajando con consultas complejas y necesitas respuestas contextualmente relevantes de alta calidad, LlamaIndex es la solución ideal.
En este artículo, examinaremos en detalle LlamaIndex, explorando sus componentes principales, características avanzadas y cómo implementarlo de manera efectiva en tus proyectos. También lo compararemos con herramientas similares como LangChain para brindarte una comprensión completa de sus capacidades.
¿Quieres conocer las últimas noticias de LLM? ¡Echa un vistazo a la última clasificación LLM!
¿Qué es LlamaIndex, en realidad?
LlamaIndex es una herramienta especializada diseñada para ampliar las funcionalidades de los Modelos de Lenguaje Grande (LLMs). Sirve como una solución integral para interacciones específicas de LLM, destacando especialmente en escenarios que requieren consultas precisas y respuestas de alta calidad.
Consulta: Optimizado para la rápida recuperación de datos, lo que lo hace ideal para aplicaciones sensibles a la velocidad. Síntesis de respuestas: Simplificado para producir respuestas concisas y contextualmente relevantes. Composabilidad: Permite construir consultas y flujos de trabajo complejos utilizando componentes modulares y reutilizables.
Ahora, adentrémonos en los detalles sobre LlamaIndex, ¿de acuerdo?
¿Qué son los índices en LlamaIndex?
Los índices son el núcleo de LlamaIndex, ya que son las estructuras de datos que contienen la información a consultar. LlamaIndex ofrece varios tipos de índices, cada uno de los cuales está optimizado para tareas específicas.

Tipos de índices en LlamaIndex
- Índice de Vector Store: Utiliza algoritmos k-NN y está optimizado para datos de alta dimensión.
- Índice basado en palabras clave: Emplea TF-IDF para consultas basadas en texto.
- Índice híbrido: Una combinación de índices basados en vectores y palabras clave, que ofrece un enfoque equilibrado.
Índice de Vector Store en LlamaIndex
El Índice de Vector Store es tu opción principal para cualquier cosa relacionada con datos de alta dimensión. Es particularmente útil para aplicaciones de aprendizaje automático en las que se trabaja con puntos de datos complejos.
Para comenzar, necesitarás importar la clase VectorStoreIndex del paquete LlamaIndex. Una vez importado, inicialízalo especificando las dimensiones de tus vectores.
from llamaindex import VectorStoreIndex
vector_index = VectorStoreIndex(dimensions=300)Esto configura un Índice de Vector Store con 300 dimensiones, listo para manejar tus datos de alta dimensión. Ahora puedes agregar vectores al índice y realizar consultas para encontrar los vectores más similares.
# Agregar un vector
vector_index.add_vector(vector_id="vector_1", vector_data=[0.1, 0.2, 0.3, ...])
# Ejecutar una consulta
query_result = vector_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)Índice basado en palabras clave en LlamaIndex
Si prefieres las consultas basadas en texto, el Índice basado en palabras clave es tu aliado. Utiliza el algoritmo TF-IDF para analizar datos de texto, lo que lo hace ideal para consultas de lenguaje natural.
Comienza importando la clase KeywordBasedIndex del paquete LlamaIndex. Una vez hecho esto, inicialízalo.
from llamaindex import KeywordBasedIndex
text_index = KeywordBasedIndex()Ahora estás listo para agregar datos de texto a este índice y realizar consultas basadas en texto.
# Agregar datos de texto
text_index.add_text(text_id="document_1", text_data="Este es un documento de muestra.")
# Ejecutar una consulta
query_result = text_index.query(text="muestra", top_k=3)Inicio rápido con LlamaIndex: Guía paso a paso
Instalar e inicializar LlamaIndex es solo el comienzo. Para aprovechar verdaderamente su poder, debes aprender a utilizarlo de manera efectiva.
Instalando LlamaIndex
En primer lugar, vamos a instalarlo en tu máquina. Abre tu terminal y ejecuta:
pip install llamaindexO si estás utilizando conda:
conda install -c conda-forge llamaindexInicializando LlamaIndex
Después de completar la instalación, deberás inicializar LlamaIndex en tu entorno de Python. Aquí es donde preparas el escenario para toda la magia que viene después.
from llamaindex import LlamaIndex
index = LlamaIndex(index_type="vector_store", dimensions=300)Aquí, index_type especifica qué tipo de índice estás configurando y dimensions se utiliza para especificar el tamaño del Índice de Vector Store.
Cómo realizar consultas con el Índice de Vector Store de LlamaIndex
Después de configurar correctamente LlamaIndex, estás listo para explorar sus potentes capacidades de consulta. El Índice de Vector Store está diseñado para manejar datos complejos y de alta dimensión, por lo que es la herramienta ideal para el aprendizaje automático, el análisis de datos y otras tareas computacionales.
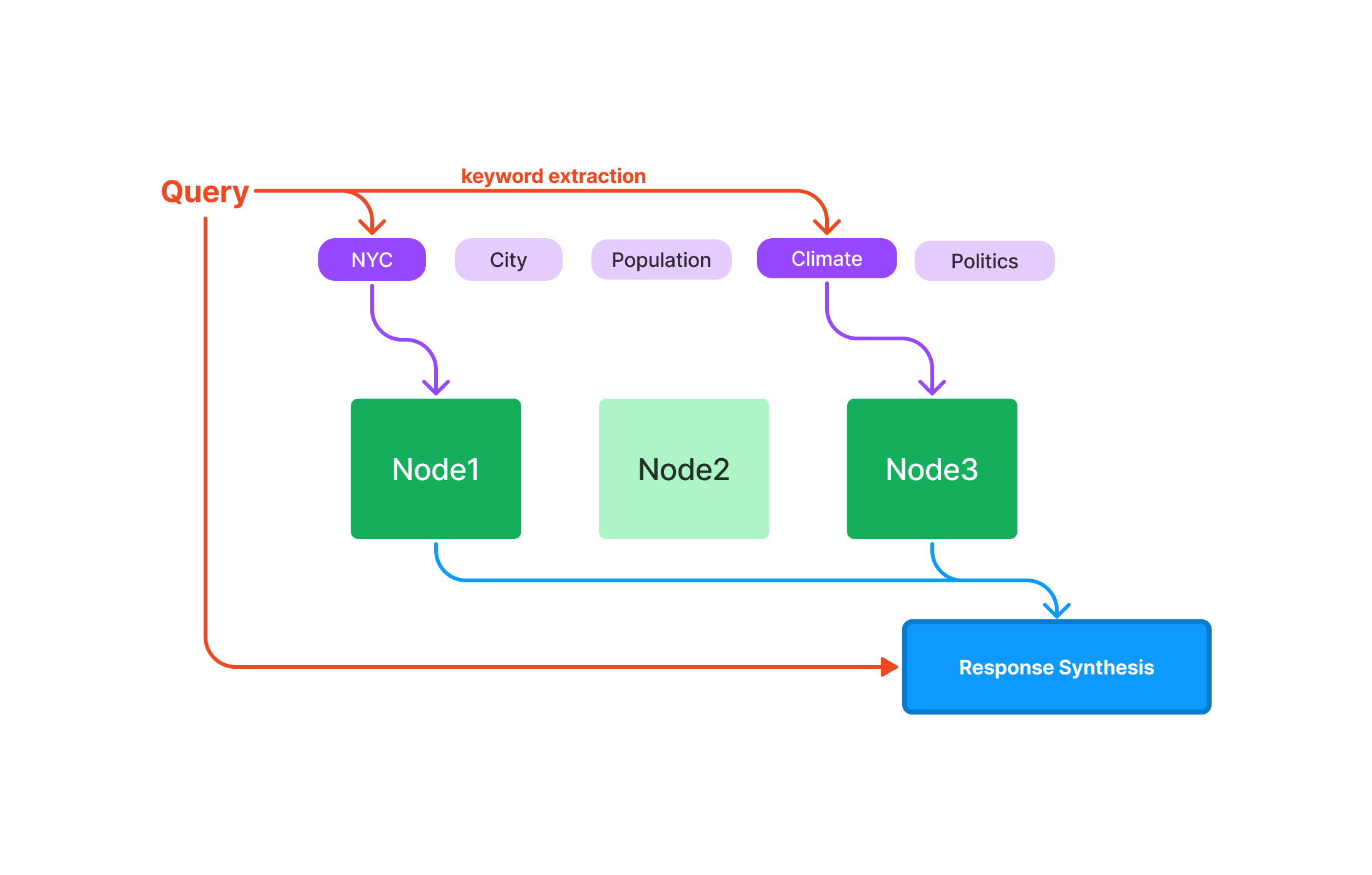
Realiza tu primera consulta en LlamaIndex
Antes de sumergirnos en el código, es crucial comprender los elementos básicos de una consulta en LlamaIndex:
-
Vector de consulta: Este es el vector que te interesa encontrar similitudes dentro de tu conjunto de datos. Debe estar en el mismo espacio dimensional que los vectores que has indexado.
-
Parámetro
top_k: Este parámetro especifica el número de vectores más cercanos a tu vector de consulta que deseas recuperar. La "k" entop_krepresenta el número de vecinos más cercanos que te interesan.
Aquí tienes un desglose de cómo hacer tu primera consulta:
-
Inicializa tu índice: Asegúrate de que tu índice esté cargado y listo para hacer consultas.
-
Especifica el vector de consulta: Crea una lista o matriz que contenga los elementos de tu vector de consulta.
-
Establece el parámetro
top_k: Decide cuántos de los vectores más cercanos quieres recuperar. -
Ejecuta la consulta: Usa el método
querypara realizar la búsqueda.
Aquí tienes un ejemplo de código en Python que ilustra estos pasos:
# Inicializa tu índice (asumiendo que se llama 'índice')
# ...
# Define el vector de consulta
query_vector = [0.2, 0.4, 0.1, ...]
# Establece el número de vectores más cercanos a recuperar
top_k = 5
# Ejecuta la consulta
query_result = index.query(vector=query_vector, top_k=top_k)Ajuste fino de tus consultas en LlamaIndex
¿Por qué importa el ajuste fino?
El ajuste fino de tus consultas te permite adaptar el proceso de búsqueda a los requisitos específicos de tu proyecto. Ya sea que estés trabajando con texto, imágenes u otro tipo de datos, el ajuste fino puede mejorar significativamente la precisión y eficiencia de tus consultas.
Parámetros clave para el ajuste fino:
-
Métrica de distancia: LlamaIndex te permite elegir entre diferentes métricas de distancia, como 'euclidiana' y 'coseno'.
-
Distancia euclidiana: Esta es la distancia "ordinaria" en línea recta entre dos puntos en el espacio euclidiano. Usa esta métrica cuando la magnitud de los vectores sea importante.
-
Similitud de coseno: Esta métrica mide el coseno del ángulo entre dos vectores. Úsala cuando te interese más la dirección de los vectores que su magnitud.
-
-
Tamaño de lote: Si estás trabajando con un conjunto de datos grande o necesitas hacer varias consultas, configurar un tamaño de lote puede acelerar el proceso al consultar múltiples vectores a la vez.
Guía paso a paso para el ajuste fino:
Así es como puedes ajustar finamente tu consulta:
-
Elige la métrica de distancia: Decide entre 'euclidiana' y 'coseno' según tus necesidades específicas.
-
Establece el tamaño de lote: Determina el número de vectores que quieres procesar en un solo lote.
-
Ejecuta la consulta ajustada finamente: Usa el método
querynuevamente, pero esta vez incluye los parámetros adicionales.
Aquí tienes un fragmento de código en Python que lo demuestra:
# Define el vector de consulta
query_vector = [0.2, 0.4, 0.1, ...]
# Establece el número de vectores más cercanos a recuperar
top_k = 5
# Elige la métrica de distancia
distance_metric = 'euclidiana'
# Establece el tamaño de lote para consultas múltiples
batch_size = 100
# Ejecuta la consulta ajustada finamente
query_result = index.query(vector=query_vector, top_k=top_k, metric=distance_metric, batch_size=batch_size)Dominando estas técnicas de ajuste fino, puedes hacer que tus consultas en LlamaIndex sean más precisas y eficientes, y así extraer el máximo valor de tus datos de alta dimensionalidad.
¿Qué se puede hacer con LlamaIndex?
Ya tienes los conceptos básicos, pero ¿qué se puede construir realmente con LlamaIndex? Las posibilidades son vastas, especialmente cuando se considera su compatibilidad con Modelos de Lenguaje de Gran Tamaño (LLMs).
LlamaIndex para motores de búsqueda avanzados
Uno de los usos más atractivos de LlamaIndex está en el ámbito de los motores de búsqueda avanzados. Imagina un motor de búsqueda que no solo recupera documentos relevantes, sino que también comprende el contexto de tu consulta. Con LlamaIndex, puedes construir exactamente eso.
Aquí tienes un ejemplo rápido para mostrar cómo podrías configurar un motor de búsqueda básico utilizando el Índice basado en palabras clave de LlamaIndex.
# Inicializa el Índice basado en palabras clave
from llamaindex import KeywordBasedIndex
search_index = KeywordBasedIndex()
# Agrega algunos documentos
search_index.add_text("doc1", "Las llamas son increíbles.")
search_index.add_text("doc2", "Amo la programación.")
# Ejecuta una consulta
results = search_index.query("Llamas", top_k=2)LlamaIndex para sistemas de recomendación
Otra aplicación fascinante está en la construcción de sistemas de recomendación. Ya sea que se trate de sugerir productos similares, artículos o incluso canciones, el Índice de Almacenamiento de Vectores de LlamaIndex puede ser un cambio de juego.
Así es como podrías configurar un sistema de recomendación básico:
# Inicializa el Índice de Almacenamiento de Vectores
from llamaindex import VectorStoreIndex
rec_index = VectorStoreIndex(dimensions=50)
# Agrega algunos vectores de productos
rec_index.add_vector("producto1", [0.1, 0.2, 0.3, ...])
rec_index.add_vector("producto2", [0.4, 0.5, 0.6, ...])
# Ejecuta una consulta para encontrar productos similares
productos_similares = rec_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)LlamaIndex vs. LangChain
Cuando se trata de desarrollar aplicaciones impulsadas por Modelos de Lenguaje de Gran Tamaño (LLMs), la elección del framework puede impactar significativamente el éxito del proyecto. Dos frameworks que han ganado atención en este espacio son LlamaIndex y LangChain. Ambos tienen características y ventajas únicas, pero satisfacen necesidades diferentes y están optimizados para tareas específicas. En esta sección, profundizaremos en los detalles técnicos y proporcionaremos código de ejemplo para ayudarte a comprender las diferencias clave entre estos dos frameworks, especialmente en el contexto de Generación con Recuperación Mejorada (RAG) para el desarrollo de chatbots.
Funciones principales y capacidades técnicas
LangChain
-
Framework de propósito general: LangChain está diseñado para ser una herramienta versátil para una amplia variedad de aplicaciones. No solo permite cargar, procesar e indexar datos, sino que también proporciona funcionalidades para interactuar con LLMs.
Código de ejemplo:
const res = await llm.call("Cuéntame un chiste"); -
Flexibilidad: Una de las características destacadas de LangChain es su flexibilidad. Permite a los usuarios personalizar el comportamiento de sus aplicaciones de manera extensiva.
-
APIs de alto nivel: LangChain abstrae la mayoría de las complejidades relacionadas con el trabajo con LLMs, ofreciendo APIs de alto nivel que son simples y fáciles de usar.
Código de ejemplo:
const chain = new SqlDatabaseChain({ llm: new OpenAI({ temperature: 0 }), database: db, sqlOutputKey: "sql", }); const res = await chain.call({ query: "¿Cuántas pistas hay?" }); -
Cadenas preconfiguradas: LangChain viene precargado con cadenas preconfiguradas como
SqlDatabaseChain, que se pueden personalizar o usar como base para construir nuevas aplicaciones.
LlamaIndex
-
Especializado en búsqueda y recuperación: LlamaIndex está diseñado para la construcción de aplicaciones de búsqueda y recuperación. Ofrece una interfaz sencilla para consultar LLMs y recuperar documentos relevantes.
Código de ejemplo:
query_engine = index.as_query_engine() response = query_engine.query("Stackoverflow es increíble.") -
Eficiencia: LlamaIndex está optimizado para un rendimiento óptimo, lo que lo convierte en una mejor opción para aplicaciones que necesitan procesar grandes volúmenes de datos rápidamente.
-
Conectores de datos: LlamaIndex puede ingestar datos de diversas fuentes, incluyendo APIs, archivos PDF, bases de datos SQL y más, lo que permite una integración perfecta en aplicaciones LLM.
-
Indexación optimizada: Una de las características clave de LlamaIndex es su capacidad para estructurar los datos ingestados en representaciones intermedias que están optimizadas para consultas rápidas y eficientes.
¿Cuándo usar cada framework?
-
Aplicaciones de propósito general: Si estás construyendo un chatbot que necesita ser flexible y versátil, LangChain es la opción ideal. Su naturaleza de propósito general y sus APIs de alto nivel lo hacen adecuado para una amplia gama de aplicaciones.
-
Enfoque en búsqueda y recuperación: Si la función principal de tu chatbot es buscar y recuperar información, LlamaIndex es la mejor opción. Sus capacidades especializadas de indexación y recuperación lo hacen altamente eficiente para tareas de este tipo.
-
Combinación de ambos: En algunos escenarios, puede ser beneficioso utilizar ambos frameworks. LangChain puede manejar funcionalidades generales e interacciones con LLMs, mientras que LlamaIndex puede gestionar tareas especializadas de búsqueda y recuperación. Esta combinación puede ofrecer un enfoque equilibrado, aprovechando la flexibilidad de LangChain y la eficiencia de LlamaIndex.
Código de ejemplo para uso combinado:
# LangChain para funcionalidades generales res = llm.call("Cuéntame un chiste") # LlamaIndex para búsqueda especializada query_engine = index.as_query_engine() response = query_engine.query("Cuéntame sobre el cambio climático.")
Entonces, ¿cuál debería elegir? ¿LangChain o LlamaIndex?
La elección entre LangChain y LlamaIndex, o la decisión de utilizar ambos, debe estar guiada por los requisitos y objetivos específicos de tu proyecto. LangChain ofrece un rango más amplio de capacidades y es ideal para aplicaciones de propósito general. En contraste, LlamaIndex se especializa en búsqueda y recuperación eficientes, lo que lo hace adecuado para tareas intensivas en datos. Al comprender los matices técnicos y las capacidades de cada framework, puedes tomar una decisión informada que se ajuste mejor a tus necesidades de desarrollo de chatbot.
Conclusión
En este momento, deberías tener un sólido entendimiento de lo que LlamaIndex representa. Desde sus índices especializados hasta su amplia gama de aplicaciones y su ventaja sobre otras herramientas como LangChain, LlamaIndex demuestra ser una herramienta indispensable para cualquier persona que trabaje con Modelos de Lenguaje Extensos. Ya sea que estés construyendo un motor de búsqueda, un sistema de recomendación o cualquier aplicación que requiera consultas eficientes y recuperación de datos, LlamaIndex tiene todo lo que necesitas.
Preguntas frecuentes sobre LlamaIndex
Vamos a responder algunas de las preguntas más comunes que las personas tienen sobre LlamaIndex.
¿Para qué se utiliza LlamaIndex?
LlamaIndex se utiliza principalmente como una capa intermedia entre los usuarios y los Modelos de Lenguaje Extensos. Sobresale en la ejecución de consultas, síntesis de respuestas e integración de datos, lo que lo hace ideal para una variedad de aplicaciones como motores de búsqueda y sistemas de recomendación.
¿LlamaIndex es gratuito?
Sí, LlamaIndex es una herramienta de código abierto, lo que significa que es gratis para usar. Puedes encontrar su código fuente en GitHub y contribuir a su desarrollo.
¿Qué es GPT Index y LlamaIndex?
GPT Index está diseñado para consultas basadas en texto y generalmente se utiliza con modelos GPT (Transformador Generativo Pre-entrenado). LlamaIndex, por otro lado, es más versátil y puede manejar tanto consultas basadas en texto como consultas basadas en vectores, lo que lo hace compatible con una gama más amplia de Modelos de Lenguaje Extensos.
¿Cuál es la arquitectura de LlamaIndex?
LlamaIndex se basa en una arquitectura modular que incluye diversos tipos de índices como el Índice de Almacenamiento de Vectores y el Índice basado en Palabras Clave. Está escrito principalmente en Python y soporta múltiples algoritmos como k-NN, TF-IDF e incrustamientos BERT.
¿Quieres conocer las últimas noticias sobre Modelos de Lenguaje Extensos? ¡Echa un vistazo a la última clasificación de LLM!
