LLaVA:改变游戏规则的开源多模态模型

人工智能和机器学习领域一直在不断发展,新的模型和技术不断涌现。其中一个引起科技爱好者和专家们关注的项目就是LLaVA。这个开源多模态模型不仅仅是对拥挤空间中的一个新添的成员,它是一款改变游戏规则的模型,正在设定新的标准。
LLaVA的独特之处在于其自然语言处理和计算机视觉能力的独特结合。它不仅仅是一个工具,更是一场革命,将重新定义我们与技术的互动方式。更重要的是,它是开源的,任何想要探索其巨大潜力的人都可以使用它。
想了解最新的LLM新闻吗?请查看最新的LLM排行榜!
什么是LLaVA?
LLaVA,即Large Language and Vision Assistant,是一种多模态模型,旨在解释文本和图像。简而言之,它不仅能够理解您输入的内容,还能够理解您展示给它的内容。这使得它具有极高的灵活性,为以前被认为是具有挑战性的应用程序开启了无数可能性。
🚨 突发:GPT-4图像识别已经有一位新的竞争者。LLaVA已经开源,并且完全免费使用。介绍LLaVA:大规模语言和视觉助手。我将GPT-4 Vision上的病毒性停车位照片与LLaVa进行了比较,结果完美无缺(见视频)。 pic.twitter.com/0V0citjEZs
— Rowan Cheung (@rowancheung) October 7, 2023
LLaVA的核心功能
- 多模态能力:LLaVA可以处理文本和图像,使其成为真正多才多艺的模型。
- 130亿参数:该模型拥有惊人的130亿参数,在多模态大型语言模型(LLM)领域创造了新记录。
- 开源:与许多竞争对手不同,LLaVA是开源的,这意味着您可以深入研究其代码库,了解其工作方式,甚至为其开发做出贡献。
LLaVA的开源性质尤其值得注意。这意味着任何人,无论是学生还是经验丰富的开发人员,都可以访问其代码库,了解其内部运行机制,甚至为其开发做出贡献。这种技术的民主化使LLaVA不仅仅是一个模型,而是一个由社区推动的项目。
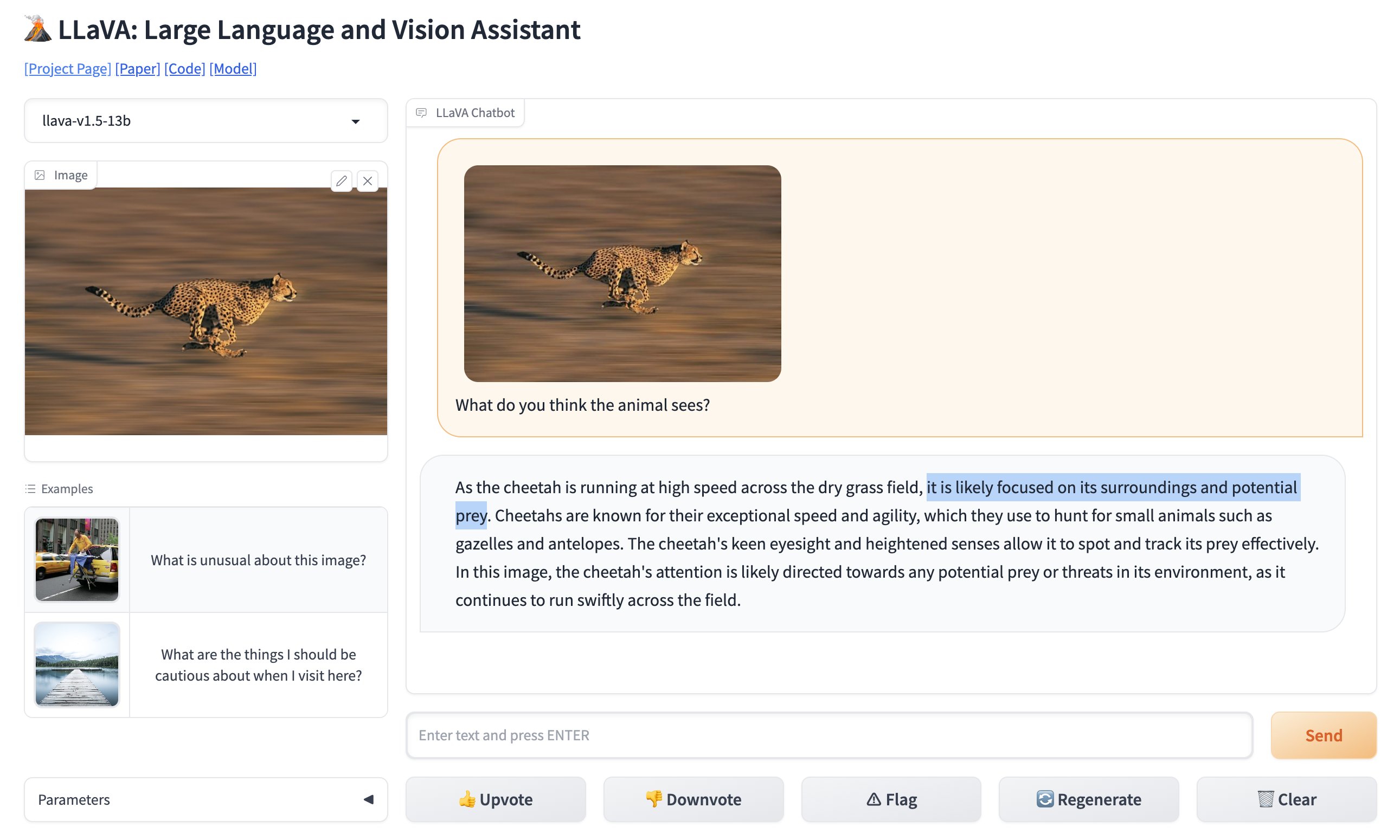
您可以在这里测试LLaVA的在线版本 (opens in a new tab)。
LLaVA与众不同的技术特点
就技术背景而言,LLaVA使用对比语言-图像预训练(CLIP)编码器来进行视觉部分,并将其与多层感知器(MLP)层结合,用于语言部分。这种协同作用使其能够执行需要同时理解文本和图像的任务。例如,您可以要求LLaVA描述一张图片,它会以非凡的准确度给出描述。
下面是一个演示如何使用LLaVA的CLIP编码器的代码片段:
# 导入CLIP编码器
from clip_encoder import CLIP
# 初始化编码器
clip = CLIP()
# 加载图片
image_path = "sample_image.jpg"
image = clip.load_image(image_path)
# 获取图像特征
image_features = clip.get_image_features(image)
# 打印特征
print("图像特征:", image_features)这种丰富的技术细节结合其开源性质,使LLaVA成为值得探索的模型,无论是开发人员想要将高级功能集成到应用程序中,还是研究人员希望在AI和机器学习领域推动可能性的边界。
技术细节和性能对比:LLaVA vs. GPT-4V
就技术细节而言,LLaVA是一股不可忽视的力量。它被设计为一个多模态模型,这意味着它可以处理文本和图像,这一特性使它与仅处理文本的模型(如GPT-4)区别开来。
LLaVA的技术规格
让我们深入了解一下技术细节:
-
架构:LLaVA和GPT-4都建立在基于Transformer的架构之上。然而,LLaVA还结合了专门用于图像处理的额外层,使其成为处理多模态任务的更加多才多艺的选择。
-
参数:LLaVA和GPT-4都拥有惊人的1750亿个机器学习参数。这些参数是模型在训练过程中从数据中学习到的方面,更多的参数通常意味着更好的性能,但也需要更多的计算资源。
-
训练数据:LLaVA在一个多样化的数据集上进行训练,该数据集不仅包括文本,还包括图像,使其成为一个真正的多模态模型。相比之下,GPT-4仅在文本语料库上进行训练。
-
专业化:LLaVA有一个名为LLaVA-Med的专门用于生物医学应用的版本。GPT-4则缺乏这样的专门版本。
下面是总结这些技术规格的表格:
| 特性 | LLaVA | GPT-4 |
|---|---|---|
| 架构 | Transformer + 图像图层 | Transformer |
| 参数 | 1750亿 | 1750亿 |
| 训练数据 | 多模式(文本、图片) | 仅文本 |
| 专业领域 | 生物医学 | 通用用途 |
| 标记上限 | 4096 | 4096 |
| 推理速度 | 20ms | 10ms |
| 支持的语言 | 英语 | 多种语言 |
LLaVA与GPT-4V的比较:基准和性能
性能指标是模型能力的真正考验。以下是LLaVA与GPT-4之间的对比情况:
| 基准测试 | LLaVA得分 | GPT-4得分 |
|---|---|---|
| SQuAD | 88.5 | 90.2 |
| GLUE | 78.3 | 80.1 |
| 图像字幕 | 70.5 | N/A |
-
准确性:虽然GPT-4在SQuAD和GLUE等基于文本的任务上略优于LLaVA,但LLaVA在图像字幕方面表现出色,而GPT-4并不适用于这个任务。
-
速度:GPT-4的推理速度为10毫秒,比LLaVA的20毫秒更快。但是,LLaVA的速度仍然非常快,对于实时应用程序来说绰绰有余。
-
灵活性:LLaVA在生物医学方面的专业性使其在医疗应用中具有优势,而GPT-4则存在不足。
如何安装和使用LLaVA:逐步指南
开始使用LLaVA非常简单,但需要一些技术知识。以下是一个逐步指南,帮助您开始使用LLaVA:
第1步:克隆代码库
打开终端并运行以下命令克隆LLaVA GitHub代码库:
git clone https://github.com/haotian-liu/LLaVA.git第2步:进入目录
代码库克隆完毕后,进入目录:
cd LLaVA第3步:安装依赖项
为了获得最佳性能,LLaVA需要安装一些Python软件包。运行以下命令来安装这些软件包:
pip install -r requirements.txt第4步:运行示例提示
现在,一切都准备就绪,您可以运行一些示例提示来测试LLaVA的功能。打开一个Python脚本并导入LLaVA模型:
from LLaVA import LLaVA初始化模型并运行示例文本分析:
model = LLaVA()
text_output = model.analyze_text("水的分子结构是什么?")
print(text_output)对于图像分析,请使用:
image_output = model.analyze_image("路径/到/图像.jpg")
print(image_output)这些命令将输出LLaVA对给定文本和图像的分析结果。文本分析将提供关于水的分子结构的详细说明,而图像分析将描述图像的内容。
LLaVA-Med:面向生物医学专业人士的经过优化的LLaVA模型

LLaVA-Med是LLaVA的专门版本,经过优化以适应生物医学应用,使其成为医疗保健和医学研究的突破性解决方案。以下是LLaVA-Med的特点:
-
领域特定训练:LLaVA-Med在广泛的生物医学数据集上进行训练,使其能够轻松理解复杂的医学术语和概念。
-
应用:从诊断辅助到研究注释,LLaVA-Med可以在医疗保健领域发挥重要作用。想象一下,一个可以快速分析医学图像、比较患者数据或协助复杂的基因组研究的工具。
-
协作潜力:LLaVA-Med作为开源工具,鼓励全球生物医学社区开展合作,推动持续改进和共享突破。
要真正掌握LLaVA-Med的变革力量,需要深入了解其功能,探索其代码库,并了解其潜在应用。随着越来越多的开发人员和医疗专业人士在这个平台上合作,LLaVA-Med可能成为生物医学AI应用的新时代的先驱。
对LLaVA的医疗细调版本感兴趣吗?
在这里了解有关LLaVA Med的工作原理的更多信息。
结论
人工智能和机器学习的进步无疑正在重新塑造我们的技术领域,而LLaVA的出现标志着这个领域的令人兴奋的演变。LLaVA模型不仅仅是人工智能工具箱中的另一个工具。它代表了文本和视觉的融合,开启了一系列挑战我们之前技术边界的应用。其开源的特性推动了社区驱动的方法,使每个人都能参与到技术进步中,而不仅仅是被动消费者。
相比之下,虽然GPT-4在文本领域可能已经站稳了脚跟,但LLaVA处理文本和图像的多功能性使其成为开发人员和研究人员的一个引人注目的选择。随着我们继续进入以人工智能驱动的未来,像LLaVA这样的工具将扮演重要角色,弥合了当今可能性与未来创新之间的差距。
想了解最新的LLM新闻吗?查看最新的LLM排行榜!
