如何在本地运行Mistral模型-完整指南

在不断变化的人工智能领域中,Mistral AI成为了创新的引领者,在大型语言模型(LLMs)领域开辟了新的领域。通过引入其开创性的模型,Mistral AI不仅推进了机器学习的前沿,而且使得接触尖端技术变得更加民主化。本指南旨在阐明Mistral AI的产品的复杂性,并为在本地使用它们的能力提供全面的指导。
这些Mistral AI模型是什么?
Mistral AI推出了一系列的语言模型,它们不仅是迭代,更是计算语言学的飞跃。这个系列的核心是Mistral 7B和Mixtral 8x7B,每个模型都设计用来满足各种需求和计算能力。
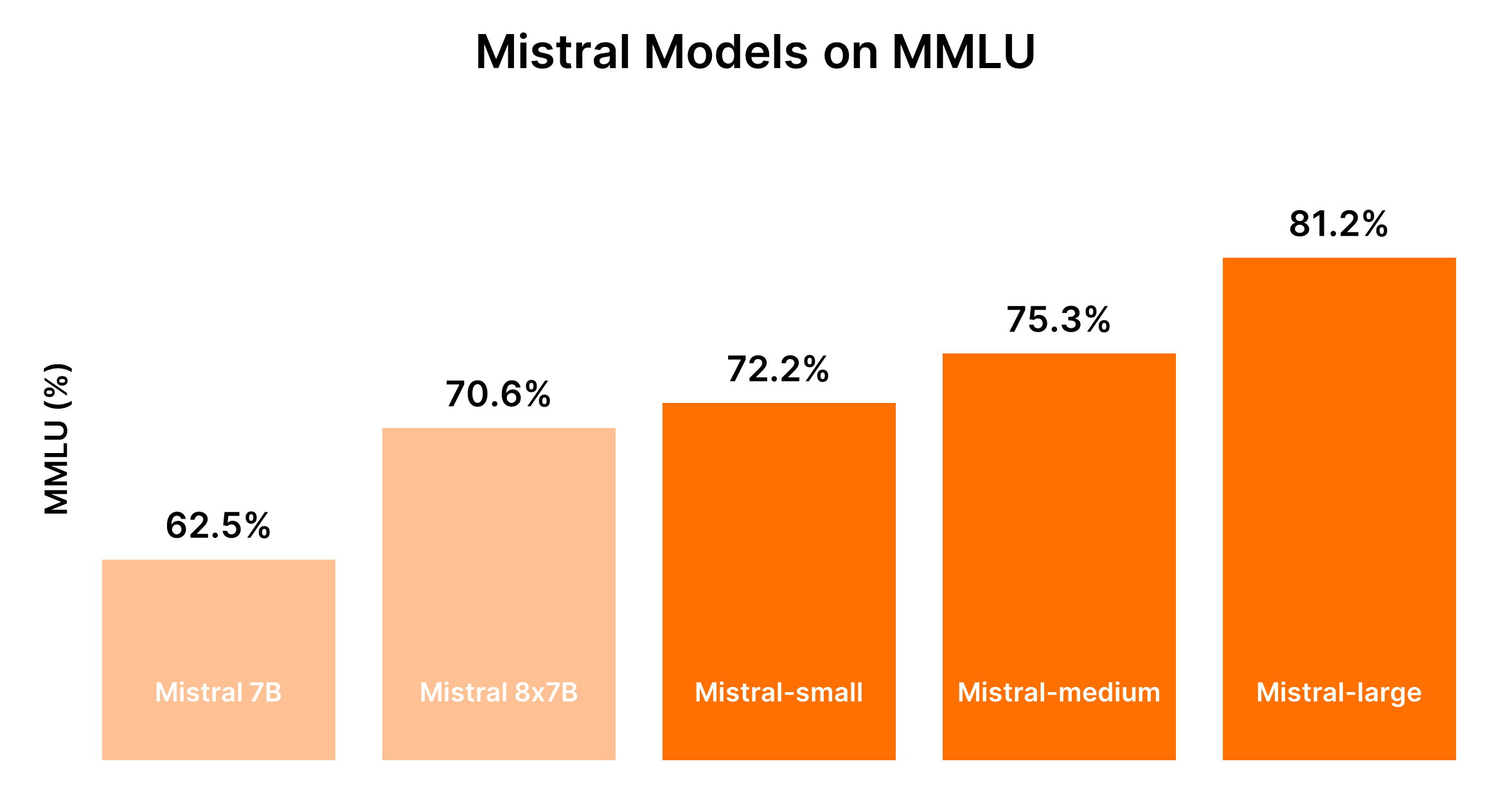
比较Mistral AI模型(Mistral 7B vs Mistral 8x7b vs Mistral Small vs Mistral Medium vs Mistral Large)
了解了。根据提供的输入,我们将专注于创建表格以进行直接比较,并为Mistral AI模型的比较分析提供结构。
Mistral AI模型的比较分析
Mistral AI提供了一系列的模型,每个模型都针对不同的用例,从简单的批量任务到复杂的推理能力。下面是用于清晰理解的以markdown格式呈现的比较分析和性能输出。
模型概述和用例
| 模型ID | 别名 | 用例 |
|---|---|---|
| open-mistral-7b | mistral-tiny-2312 | 简单的批量任务,如分类、客户支持或文本生成。 |
| open-mixtral-8x7b | mistral-small-2312 | 类似于open-mistral-7b,适合简单的批量任务。 |
| mistral-small-latest | mistral-small-2402 | 需要最少推理的略微复杂的任务。 |
| mistral-medium-latest | mistral-medium-2312 | 中级任务,例如数据提取、文档摘要、撰写电子邮件等。 |
| mistral-large-latest | mistral-large-2402 | 需要大规模推理能力的复杂任务,例如合成文本生成、代码生成。 |
性能和成本权衡
Mistral模型的性能通常与其大小成正比,较大的模型提供了更强大的功能,但成本也较高。以下表格总结了基于MMLU基准和一般成本考虑的性能排名。
| 模型 | 性能排名 | 成本考虑 |
|---|---|---|
| Mistral 7B (tiny-2312) | 第5名 | 最适合简单任务的最经济实惠型号 |
| Mixtral 8x7B (small-2312) | 第4名 | 适用于简单批量任务的成本效益最高型号 |
| Mistral Small (small-2402) | 第3名 | 中等成本,适用于需要最少推理的任务 |
| Mistral Medium (medium-2312) | 第2名 | 较高成本,适用于中级任务的平衡性能 |
| Mistral Large (large-2402) | 第1名 | 最高成本,适用于复杂任务的无与伦比性能 |
鉴于LLM性能和相关成本的动态特性,建议参考当前的基准和定价以进行最准确的比较。对于最新的基准和性能见解,Hugging Face的Chatbot Arena Leaderboard (opens in a new tab)和Artificial Analysis (opens in a new tab)等平台可以提供有价值的信息。
决策指南:您应该选择哪个Mistral AI模型?
选择合适的模型取决于平衡性能需求和成本约束,考虑您的应用程序意图处理的任务的复杂性。
- 对于简单任务: 从Mistral Small或Mistral 7B开始,以节约成本。
- 对于中级到复杂任务: 评估Mistral Medium或Mistral Large的改进性能是否能够根据您的特定应用需求合理地增加成本。
这种结构化的比较旨在在从Mistral AI的模型提供中进行明智的选择,确保所选模型符合项目的功能需求和预算限制。

第1部分. 如何使用Ollama在本地运行Mistral(简便方法)
在本地使用Ollama运行Mistral AI模型是一种使用这些先进的LLM强大功能的简便方法。这种方法非常适合开发人员、研究人员和爱好者,他们希望在自己的计算机上进行与AI驱动的文本分析、生成等方面的实验,而不依赖于云服务。以下是让你开始的简洁指南:
第1步:下载Ollama
- 访问Ollama的下载页面,选择适合您操作系统的版本。对于macOS用户,您需要下载一个
.dmg文件。 - 通过将下载的文件拖放到
/Applications目录中来安装Ollama。
第2步:探索Ollama命令
打开你的终端并输入 ollama 以查看可用命令的列表。你将看到像 serve、create、show、run、pull 等选项。
第 3 步:安装 Mistral AI
要安装 Mistral AI 模型,首先,你需要找到你想要安装的模型。如果你对 Mistral:instruct 版本感兴趣,你可以直接安装它,或者如果它尚未安装在你的设备上,你可以下载它。
- 直接运行(如果需要,会自动下载):
ollama run mistral:instruct - 预先下载模型:
ollama pull mistral:instruct
第 4 步:与 Mistral AI 交互
一旦安装了模型,你可以通过交互模式或直接传递输入与其进行交互。
-
交互模式:
ollama run mistral --verbose然后按照提示输入你的查询。
-
非交互模式(直接输入): 假设你有一篇你想要总结的文章保存在
bbc.txt中。你可以直接将文章内容传递给 Mistral 进行总结:ollama run mistral --verbose "请你能总结一下这篇文章吗:$(cat bbc.txt)"将
"请你能总结一下这篇文章吗:$(cat bbc.txt)"替换为与你的任务相关的任何提示。
样本输出分析
你的终端将显示模型的输出,包括摘要或对你的提示的响应。看到 Mistral 处理和理解复杂查询的方式,甚至在提示不准确时提供纠正是非常吸引人的。
使用 HTTP API 运行 Mistral AI
Ollama 还支持使用 HTTP API 来与模型进行编程交互。
- 示例
curl请求:curl -X POST http://localhost:11434/api/generate -d '{ "model": "mistral", "prompt": "这个句子的情感是什么:视频助理裁判的情况已经到了危机的地步。" }'
这种方法输出可以以 JSON 形式解析的响应,以灵活地将 Mistral AI 的能力整合到应用程序中。
在本地计算机上使用 Ollama 运行 Mistral AI 打开了利用人工智能在个人项目、开发和研究中的广泛可能性。安装和使用的简便性,以及 Mistral LLMs 的强大功能,使其成为对于任何对探索人工智能技术前沿感兴趣的人来说都是一个引人注目的选择。
第 2 部分。如何在 Windows 上本地运行 Mistral 7B
可以通过多个平台访问 Mistral 7B,包括 HuggingFace、Vertex AI、Replicate、Sagemaker Jumpstart 和 Baseten。Kaggle 的 "Models" 功能也提供了一种简化的方法,使你可以开始推理或在几分钟内进行微调,无需下载模型或数据集。
访问 Mistral 7B 的预备工作
在深入之前,请确保你的环境已经更新,以避免常见错误,如 KeyError: 'mistral':
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytes实施 4 位量化
为了加快模型加载速度并减少内存使用,使用了 4 位量化:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)在 Kaggle Notebooks 中加载 Mistral 7B
Kaggle Notebooks 通过简单的 UI 交互方式方便地添加了 Mistral 7B。在选择适当的模型变体和版本后,你可以轻松加载模型和分词器以供使用:
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)使用 pipeline 函数可以根据给定的提示简化响应生成过程。
示例推理
通过设置提示并调用 pipeline,Mistral 7B 生成连贯且在上下文中相关的响应,展示了它对机器学习中的正则化等复杂概念的理解:
prompt = "作为一名数据科学家,你能解释机器学习中正则化的概念吗?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])如何对 Mistral 7B 进行微调
微调过程涉及更新库、设置模块和使模型适应你的数据集。使用 Kaggle Notebooks,可以安全地存储和访问 Hugging Face 和 Weights & Biases 等服务的 API 密钥。本部分详细介绍了有效微调的基本步骤和配置,确保你在特定数据集上最大限度地发挥模型的潜力。
- 更新和安装必要的库:确保兼容性和访问最新特性来进行微调。
- 加载模块和设置 API 访问:方便与外部服务和模型仓库进行交互。
- 配置和训练模型:调整模型以适应你的数据集的细微差别,利用 PEFT(Parameter-efficient Fine-tuning)的强大训练功能。
- 评估和保存你的模型:评估模型的性能并保存微调后的模型。
详细的演示旨在为你提供工具和知识,以有效地利用 Mistral 7B 模型的能力。从访问模型到在特定数据集上对其进行微调,每个步骤都旨在增强你的项目的自然语言处理能力。
第 3 部分。如何使用 LlamaIndex 和 Ollama 在本地运行 Mixtral 8x7b

欧洲人工智能巨头Mistral AI最近推出了“专家混合模型”Mixtral 8x7b。该模型包含了八个专家,每个专家经过了70亿个参数的训练,引起了人们的极大兴趣,因为它在各种基准测试中达到或甚至超过了GPT-3.5和Llama2 70b的性能。
第一步:安装Ollama
Ollama是一个开源工具,适用于MacOS、Linux和Windows(通过Windows子系统Linux),可以简化本地模型的运行过程。使用Ollama,您可以通过一个命令启动Mixtral:
ollama run mixtral该命令会下载模型(可能需要一些时间)并需要大量的RAM(48GB)才能顺利运行。对于配置较低的系统,Mistral 7b是一个可行的替代方案。
第二步:安装依赖项
为了将Mixtral与LlamaIndex集成,您需要安装一些依赖项。使用pip安装它们:
pip install llama-index qdrant_client torch transformers第三步:烟雾测试
使用Ollama和LlamaIndex进行“烟雾测试”来验证设置是否正确:
from llama_index.llms import Ollama
llm = Ollama(model="mixtral")
response = llm.complete("Who is Laurie Voss?")
print(response)第四步:加载数据并建立索引
准备数据:
对于本示例,可以使用任何数据集;这里我们使用了一组推文。Qdrant是一个开源的向量数据库,用于存储数据。以下代码片段展示了使用Qdrant和LlamaIndex加载和建立索引数据的过程:
from pathlib import Path
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext, download_loader
from llama_index.llms import Ollama
from llama_index.storage.storage_context import StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
## 初始化Qdrant并加载推文
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
## 使用Mixtral和本地嵌入式模型设置Service Context
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## 建立索引并查询数据
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What does the author think about Star Trek? Give details.")
print(response)验证索引:
最后一步是使用预先建立的索引来回答查询。这个过程不需要重新加载数据,因为数据已经在Qdrant中进行了索引:
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import Ollama
from llama_index.vector_stores.qdrant import QdrantVectorStore
## 加载向量存储和Mixtral
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## 加载索引和查询
index = VectorStoreIndex.from_vector_store(vector_store=vector_store, service_context=service_context)
query_engine = index.as_query_engine(similarity_top_k=20)
response = query_engine.query("Does the author like SQL? Give details.")
print(response)Part 4. 使用llama.cpp本地运行Mistral 8x7B
由于llama.cpp和llm-llama-cpp插件等工具的出现,本地运行Mistral AI模型变得更加容易。Mixtral 8x7B模型是一种高质量的稀疏专家混合(SMoE)模型,在开源许可的人工智能领域取得了重大突破。以下是使用llama.cpp和相关工具本地运行Mixtral 8x7B的简要指南。
安装并本地运行Mixtral 8x7B
-
安装LLM工具:首先确保在计算机上安装了LLM。LLM充当在本地运行各种AI模型的桥梁。
pipx install llm -
安装
llm-llama-cpp插件:安装此插件以运行Mixtral和其他llama.cpp支持的模型。llm install llm-llama-cpp -
设置
llama-cpp-python:对于Apple Silicon Macs,设置可能包括启用对Metal的支持:CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 llm install llama-cpp-python具体的步骤可能因您的平台而异,请参考
llm-llama-cpp的自述文件以获取指导。 -
下载Mixtral模型:您需要Mixtral 8x7B的GGUF文件。根据您的需求选择一个合适的文件大小,例如对于该模型的Instruct版本,选择36GB的变体:
curl -LO 'https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf?download=true' -
运行模型:下载了模型之后,您可以使用
llm工具运行Mixtral 8x7B:llm -m gguf -o path mixtral-8x7b-instruct-v0.1.Q6_K.gguf '[INST] Write a Python function that downloads a file from a URL[/INST]'这个命令指定使用GGUF模型(使用
-m gguf选项),并通过-o path提供下载的GGUF文件的路径。
其他注意事项
-
交互模式:如果您希望以更具对话性的方式与模型交互,可以在交互模式下运行
llm。这种模式允许与AI模型进行一来一回的对话。 -
提示构造:上述命令示例中的
[INST]前缀表示提示的基于指令的性质,适用于指令版本的模型。根据模型期望的输入格式,调整提示以获得最佳结果。
第5部分 在iPhone上本地运行Mistral 7B

在iPhone上运行Mistral 7B模型需要一些技术步骤,因为iOS设备通常比桌面环境有更多的限制。以下是一个简化的逐步指南:
-
前提条件:
- 确保您的iPhone正在运行最新的iOS版本,以避免兼容性问题。
- 在您的Mac上安装一个iOS应用程序开发环境,如Xcode,以编译和运行将使用Mistral 7B的自定义应用程序。
-
选择执行选项:对于iPhone部署,可能
llm-llama-cpp是最合适的,因为它与C++环境兼容,并可集成到iOS项目中。 -
设置开发环境:
- 从官方存储库下载
llm-llama-cpp的GGUF文件。 - 打开Xcode并创建一个新的iOS项目。
- 将
llm-llama-cpp库集成到您的项目中。这可能需要附加的依赖性,请参考文档。
- 从官方存储库下载
-
编码:
- 编写Swift或Objective-C代码,与C++库进行接口。这可能涉及创建一个桥接头文件,以在Swift项目中使用C++代码。
- 在您的应用程序中初始化模型,处理任何必需的配置,如模型路径和参数。
-
测试和部署:
- 在您的iPhone上测试应用程序,确保模型运行顺畅并按预期执行。
- 通过Xcode部署应用程序,无论是用于个人使用还是根据苹果的指南提交到App Store。
第6部分 使用API在本地运行Mistral AI

要使用Mistral AI的API在本地运行Mistral AI,请按照以下步骤进行操作,确保您的环境能够进行HTTP请求,比如使用Postman进行测试或具有HTTP请求功能的编程语言(例如具备requests库的Python)。
前提条件:
- 获取API密钥 (opens in a new tab),通过注册Mistral API访问来获取。
- 确保您的本地环境可以访问互联网以与Mistral API服务器通信。
- 为您的本地环境安装
llm-mistral插件。这可能涉及将其添加到项目依赖项中(针对编程项目的情况)。 - 配置您的项目或工具以使用您的Mistral API密钥。通常,这涉及在配置文件中设置密钥或将其设置为环境变量。
创建聊天完成
此API端点允许您根据提示生成文本完成。请求需要指定模型、消息(提示)和各种参数来控制生成过程,例如温度、top_p和max_tokens。
聊天完成示例Python代码:
import requests
url = "https://api.mistral.ai/chat/completions"
payload = {
"model": "mistral-small-latest",
"messages": [{"role": "user", "content": "如何开始使用Mistral AI?"}],
"temperature": 0.7,
"top_p": 1,
"max_tokens": 512,
"stream": False,
"safe_prompt": False,
"random_seed": 1337
}
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("错误:", response.text)创建嵌入
嵌入API端点用于将文本转换为高维向量。这对于语义搜索、聚类或查找相似文本等任务很有用。
创建嵌入示例Python代码:
import requests
url = "https://api.mistral.ai/embeddings"
payload = {
"model": "mistral-embed",
"input": ["你好", "世界"],
"encoding_format": "float"
}
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("错误:", response.text)列出可用模型
这个API调用非常简单,可以让您检索所有可访问的模型列表。这可以帮助根据模型的能力或您的需求动态选择各种任务的模型。
列出可用模型示例Python代码:
import requests
url = "https://api.mistral.ai/models"
headers = {
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("错误:", response.text)这些示例为与Mistral AI的API交互提供了基础,可以创建复杂的AI驱动应用程序。记得将"YOUR_API_KEY"替换为您实际的API密钥。
这些步骤提供了一个基本的大纲,用于在iPhone上本地集成和使用Mistral 7B AI模型以及通过其API。根据具体项目要求或平台更新,可能需要进行一些调整。