介绍 Jamba:开创性的 SSM-Transformer 模型

AI21 Labs 自豪地推出 Jamba,这是世界上第一个基于革命性 Mamba 架构的生产级模型。通过将 Mamba 结构化状态空间 (SSM) 技术与传统 Transformer 架构的元素无缝整合,Jamba 克服了纯粹的 SSM 模型的限制,提供了卓越的性能和效率。
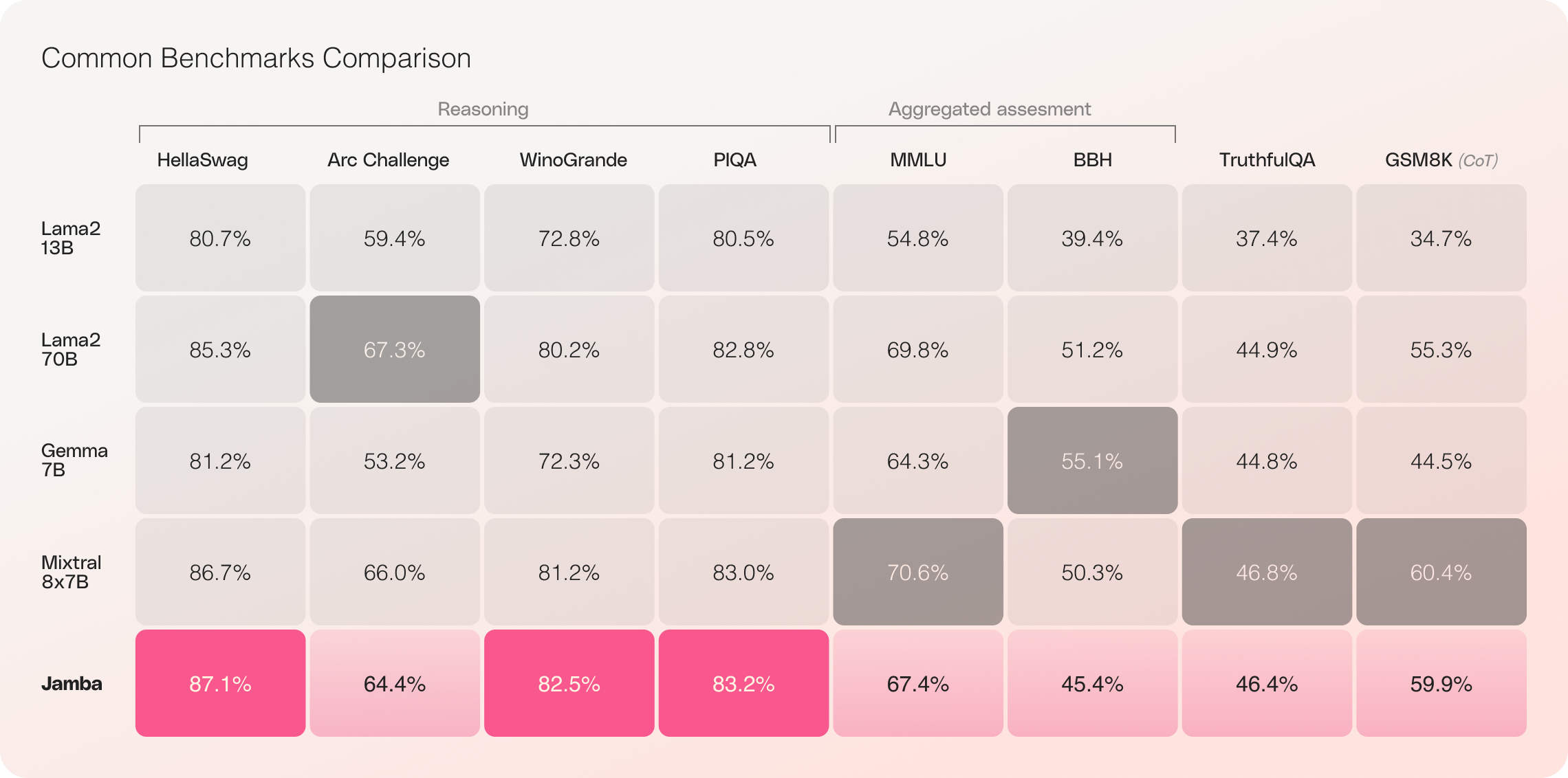
凭借其令人印象深刻的 256K 上下文窗口和显著的吞吐量提升,Jamba 将重塑 AI 领域,为研究人员、开发人员和企业开启了新的可能性。Jamba 在各种基准测试中已经展现出杰出的成绩,与同等规模的其他最先进模型相匹敌甚至超越。
TLDR:Jamba 没有安全限制机制和保护措施,并使用 Apache-2.0 开源许可证。

Jamba 的关键特点
- 第一个基于 Mamba 的生产级模型:Jamba 开创性地在生产级规模和质量上使用了 SSM-Transformer 混合架构。
- 无与伦比的吞吐量:与 Mixtral 8x7B 相比,Jamba 在长上下文上实现了 3 倍的吞吐量,为效率设定了新的标准。
- 巨大的上下文窗口:具有 256K 上下文窗口,Jamba 实现了对广泛上下文处理能力的民主化访问。
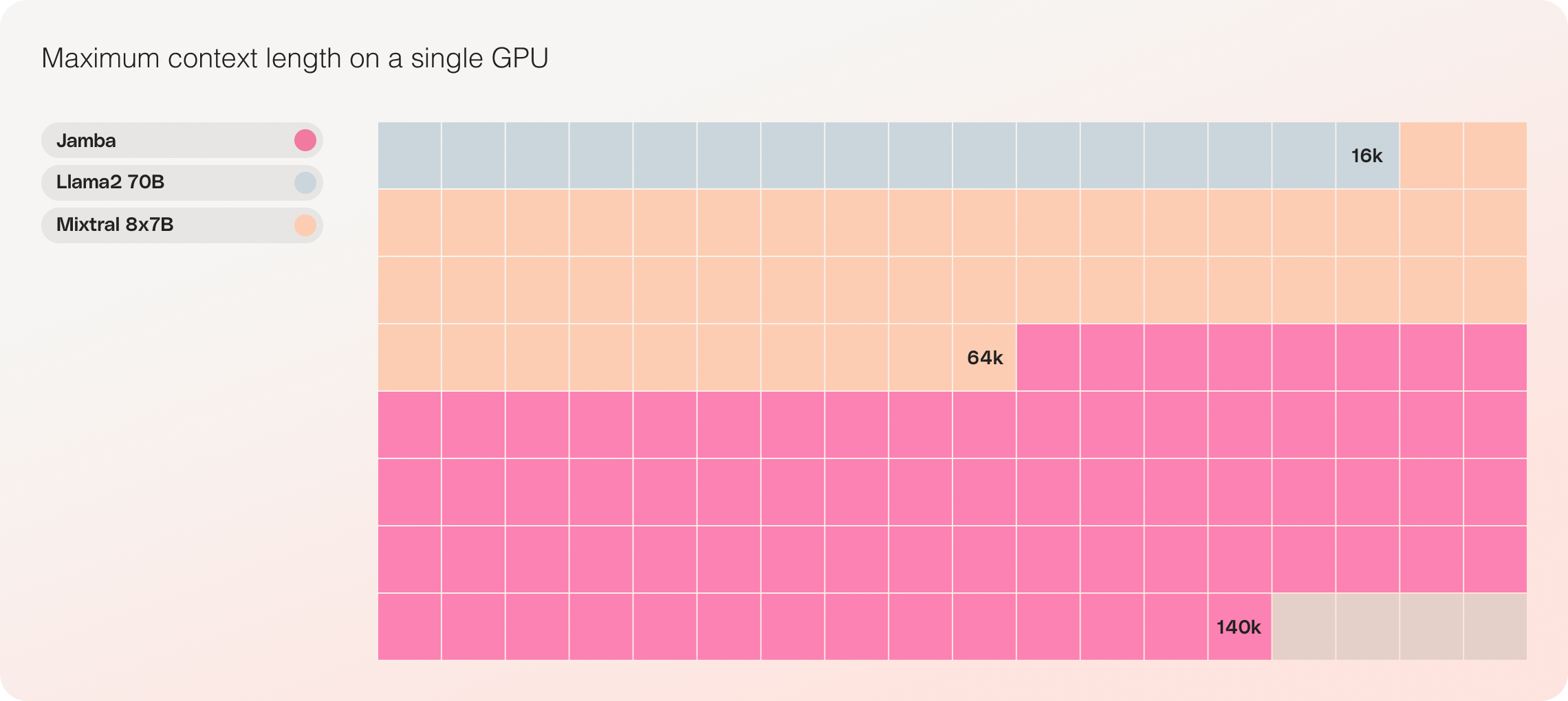
- 兼容单 GPU:Jamba 是其规模类别中唯一能够适应单 GPU 上多达 140K 上下文的模型,使其更容易用于部署和实验。
- 开源可用性:以 Apache 2.0 许可证的开放权重发布,Jamba 邀请 AI 社区进行进一步优化和发现。
- 即将推出 NVIDIA API 目录集成:Jamba 将很快作为 NVIDIA NIM 推理微服务从 NVIDIA API 目录访问,使企业应用开发人员能够使用 NVIDIA AI Enterprise 软件平台进行部署。
Jamba:结合 Mamba 和 Transformer 架构的优势
Jamba 在 LLM 创新方面取得了重要的里程碑,成功将 Mamba 和 Transformer 架构结合起来,并将混合 SSM-Transformer 模型扩展到生产级质量。
传统基于 Transformer 的 LLM 面临两个主要挑战:
- 大内存占用:Transformer 的内存占用随着上下文长度增加而增加,使得在没有大量硬件资源的情况下难以运行长上下文窗口或大量并行批处理。
- 长上下文推理速度慢:Transformer 中的注意力机制与序列长度呈二次关系,使得每个标记依赖于整个前面的序列,从而降低吞吐量。
由卡耐基梅隆大学和普林斯顿大学的研究人员提出的 Mamba 解决了这些缺点。然而,没有对整个上下文进行注意力,Mamba 在输出质量上与最佳现有模型相比较上有困难,特别是在与回溯相关的任务上。

Jamba vs Mamba vs Transfomer
Jamba 的混合架构由 Transformer、Mamba 和专家混合 (MoE) 层组成,同时针对内存、吞吐量和性能进行优化。MoE 层使 Jamba 在推理过程中仅利用其 52B 参数中的 12B,使得这些活跃参数比等效大小的仅使用 Transformer 的模型更高效。
扩展 Jamba 的混合架构
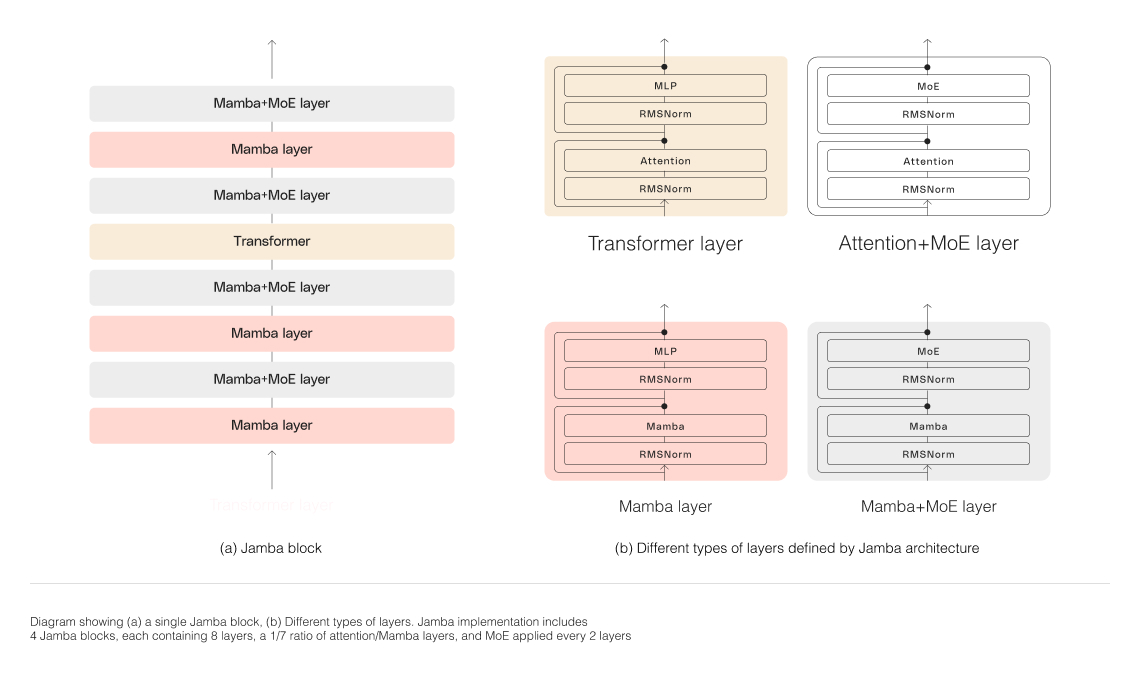
为了成功扩展 Jamba 的混合结构,AI21 Labs 实施了几项核心架构创新:
-
块和层方法:Jamba 的架构采用了块和层的方法,允许无缝集成 Transformer 和 Mamba 架构。每个 Jamba 块包含一个注意力层或一个 Mamba 层,后面跟着一个多层感知机 (MLP),从而在总体上每八层中包含一个 Transformer 层。
-
利用专家混合 (MoE):通过使用专家混合层,Jamba 增加了模型参数的总数,同时简化了推理过程中使用的活跃参数数目。这导致模型容量增加,而计算要求不增加。优化了 MoE 层数和专家数,以在单个 80GB GPU 上最大化模型的质量和吞吐量,并为常见推理工作负载留出足够的内存。
Jamba 令人印象深刻的性能和效率
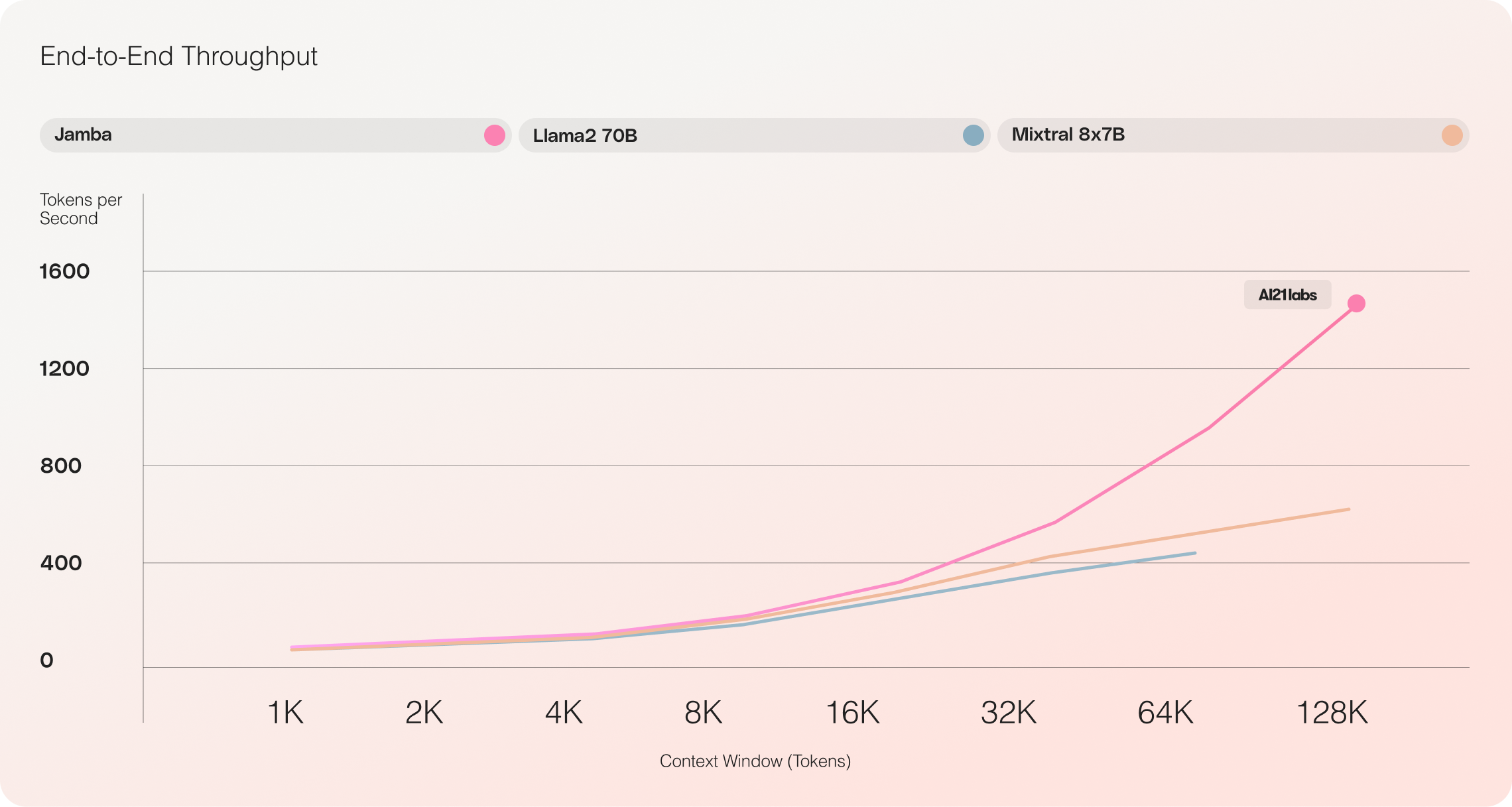
Jamba vs Llama 70B vs Mixtral 8x7B
对 Jamba 的初步评估在吞吐量和效率等关键指标上取得了令人印象深刻的结果。随着社区继续对这一开创性技术进行实验和优化,这些基准测试预计将进一步提高。
- 效率: Jamba 在处理长上下文时提供了3倍的吞吐能力,相较于类似Mixtral 8x7B这样的基于变压器的模型,更加高效。
- 成本效益: Jamba 能够将14万个上下文适应于单个GPU,相较于其他类似大小的开源模型,Jamba 提供了更易于部署和实验的机会。
未来的优化,例如增强的MoE并行性和更快的Mamba实现,预计将进一步提高这些已经引人注目的收益。
使用Jamba开始构建
Jamba 现在可在 Hugging Face 上使用,并在 Apache 2.0 许可下发布了开放权重。作为一个基础模型,Jamba 旨在作为微调、训练和开发定制解决方案的基础。为了负责任和安全地使用,添加适当的安全措施是必要的。
通过 AI21 平台,即将推出 Jamba 的指导版本。要分享您的项目、提供反馈或提问,请加入 Discord 上的讨论。
结论
Jamba 的引入标志着人工智能技术的重大飞跃,展示了混合SSM-Transformer架构的巨大潜力。通过结合 Mamba 和 Transformer 的优势,同时以效率和性能为最佳化目标,Jamba 在其规模类别中树立了新的人工智能模型标准。
凭借其卓越的上下文处理能力、吞吐量和成本效益,Jamba 已经准备革新人工智能领域,使研究人员、开发人员和企业能够推动界限。随着社区不断探索和构建基于 Jamba 的创新,我们可以预见到一波新的人工智能应用,将塑造人工智能的未来。