1 位大型语言模型时代的到来:微软推出 BitNet b1.58
- Name
- Lynn Mikami
Published on
简介
微软的研究人员推出了一种具有突破性的 1 位大型语言模型(LLM)变体,名为 BitNet b1.58,该模型的每个参数都是三值的,取值范围为1。这种 1.58 位 LLM 与具有相同模型大小和训练标记的全精度(FP16 或 BF16)变压器 LLM 在性能上相匹配,而在延迟、内存使用、吞吐量和能耗方面显著更具成本效益。BitNet b1.58 是在提高 LLM 的性能和高效性方面迈出的重要一步。

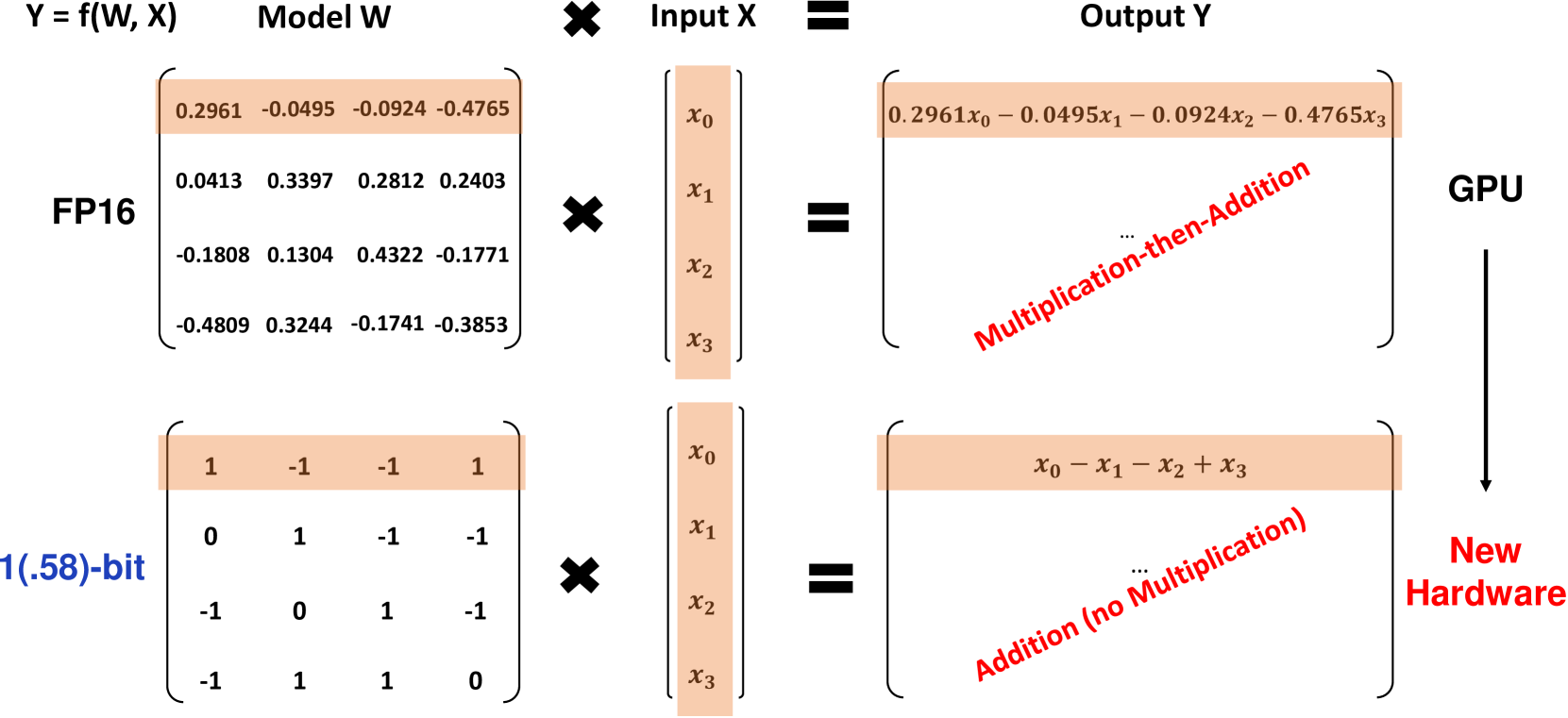
BitNet b1.58 是什么?
BitNet b1.58 基于原始的 BitNet 架构,这是一个将标准 nn.Linear 层替换为 BitLinear 层的变压器模型。它使用1.58位权重和8位激活进行从头训练。与原始的1位 BitNet 相比,b1.58 引入了几个关键修改:
-
它使用 absmean 量化函数将权重限制在 1 范围内。这将每个权重值按照平均绝对值的比例四舍五入为最接近的整数值。
-
对于激活函数,它将其缩放到每个标记的范围 [-sa, sa],相比原始 BitNet,这简化了实现过程。
-
它采用了流行的开源 LLaMA 架构的一些组件,包括 RMSNorm、SwiGLU 激活函数、旋转嵌入和去掉偏置项。这使得它能够轻松集成到现有的 LLM 软件中。
权重中添加了值 0 可以实现特征过滤,提升了建模能力,相比纯粹的 1 位模型。实验结果显示,BitNet b1.58 在困惑度和终端任务性能上与 FP16 基线相匹配,起始模型参数大小为 3B。
性能结果
研究人员将 BitNet b1.58 与复现的 FP16 LLaMA LLM 基线进行了比较,模型大小从 700M 到 70B 参数不等。两者均在相同的 RedPajama 数据集上进行了 100B 标记的预训练,并评估了困惑度和一系列零样本语言任务。
关键发现包括:
-
BitNet b1.58 在 3B 大小上与 FP16 LLaMA 基线的困惑度相匹配,同时速度提高了 2.71 倍,使用的 GPU 内存减少了 3.55 倍。
-
3.9B 的 BitNet b1.58 在困惑度和终端任务方面优于 3B LLaMA,且具有更低的延迟和内存成本。
-
在零样本语言任务上,BitNet b1.58 和 LLaMA 之间的性能差距随着模型大小的增加而缩小,BitNet 在 3B 大小时与 LLaMA 相匹配。
-
在扩展到 70B 的情况下,BitNet b1.58 达到了相对于 FP16 基线的 4.1 倍加速。随着规模的增大,内存节约也在增加。
-
BitNet b1.58 在矩阵乘法中使用的能量比 FP16 低 71.4 倍。随着模型大小的增加,端到端的能量效率也增加。
-
在两个 80GB 的 A100 GPU 上,70B 的 BitNet b1.58 支持的批处理大小比 LLaMA 要大 11 倍,实现的吞吐量提高了 8.9 倍。
结果表明,BitNet b1.58 在性能方面相比最先进的 FP16 LLM 提供了帕累托改进 - 在延迟、内存和能量方面更加高效,同时在足够的规模上与困惑度和终端任务性能相匹配。例如,13B 的 BitNet b1.58 比 3B 的 FP16 LLM 更加高效,30B 的 BitNet 比 7B 的 FP16 更高效,70B 的 BitNet 比 13B 的 FP16 模型更高效。
在按照 StableLM-3B 配方训练了 2T 标记后,BitNet b1.58 在所有评估任务上的零样本性能均优于 StableLM-3B,表现出了良好的泛化性能。
下表提供了 BitNet b1.58 与 FP16 LLaMA 基线之间性能比较的更详细数据:
| 模型 | 大小 | 内存(GB) | 延迟(ms) | PPL |
|---|---|---|---|---|
| LLaMA LLM | 700M | 2.08 (1.00x) | 1.18 (1.00x) | 12.33 |
| BitNet b1.58 | 700M | 0.80 (2.60x) | 0.96 (1.23x) | 12.87 |
| LLaMA LLM | 1.3B | 3.34 (1.00x) | 1.62 (1.00x) | 11.25 |
| BitNet b1.58 | 1.3B | 1.14 (2.93x) | 0.97 (1.67x) | 11.29 |
| LLaMA LLM | 3B | 7.89 (1.00x) | 5.07 (1.00x) | 10.04 |
| BitNet b1.58 | 3B | 2.22 (3.55x) | 1.87 (2.71x) | 9.91 |
| BitNet b1.58 | 3.9B | 2.38 (3.32x) | 2.11 (2.40x) | 9.62 |
表1:BitNet b1.58 和 LLaMA LLM 的困惑度和成本比较。
| 模型 | 大小 | ARCe | ARCc | HS | BQ | OQ | PQ | WGe | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA LLM | 700M | 54.7 | 23.0 | 37.0 | 60.0 | 20.2 | 68.9 | 54.8 | 45.5 |
| BitNet b1.58 | 700M | 51.8 | 21.4 | 35.1 | 58.2 | 20.0 | 68.1 | 55.2 | 44.3 |
| LLaMA LLM | 1.3B | 56.9 | 23.5 | 38.5 | 59.1 | 21.6 | 70.0 | 53.9 | 46.2 |
| BitNet b1.58 | 1.3B | 54.9 | 24.2 | 37.7 | 56.7 | 19.6 | 68.8 | 55.8 | 45.4 |
| LLaMA LLM | 3B | 62.1 | 25.6 | 43.3 | 61.8 | 24.6 | 72.1 | 58.2 | 49.7 |
| BitNet b1.58 | 3B | 61.4 | 28.3 | 42.9 | 61.5 | 26.6 | 71.5 | 59.3 | 50.2 |
| BitNet b1.58 | 3.9B | 64.2 | 28.7 | 44.2 | 63.5 | 24.2 | 73.2 | 60.5 | 51.2 |
表2:BitNet b1.58 和 LLaMA LLM 在终端任务上的零样本准确率。
图中显示了 BitNet b1.58 在不同模型大小下的解码延迟和内存消耗。速度随着模型大小的增加而提高,在 70B 参数下相对于 FP16 基线提高了 4.1 倍。内存节约也随着规模的扩大而增加。
参考说明 参考说明 图1:BitNet b1.58 在不同模型大小下的解码延迟(左)和内存消耗(右)。 在能源效率方面,BitNet b1.58在矩阵乘法方面使用了71.4倍的能量,相比FP16 LLMs要少得多。模型大小的端到端能量成本如图2所示,显示出在较大规模下,BitNet b1.58变得越来越高效。
参见图片说明 参见图片说明 图2:BitNet b1.58与LLaMA LLM的能耗比较。左:算术运算能量的组成。右:模型大小的端到端能量成本。
吞吐量是BitNet b1.58的另一个关键优势。在两个80GB的A100 GPU上,70B的BitNet b1.58支持的批处理大小比70B的LLaMA LLM大11倍,导致吞吐量高出8.9倍,如表3所示。
| 模型 | 大小 | 最大批处理大小 | 吞吐量(标记/秒) |
|---|---|---|---|
| LLaMA LLM | 70B | 16 (1.0x) | 333 (1.0x) |
| BitNet b1.58 | 70B | 176 (11.0x) | 2977 (8.9x) |
表3:70B的BitNet b1.58与LLaMA LLM的吞吐量比较。
影响和未来方向
BitNet b1.58的架构和结果对LLMs的未来具有重大影响:
-
它提供了一种新的Pareto边界和缩放规律,即在性能和高效性方面都具有高水平。1.58比特的LLMs在显著降低推理成本的情况下可以与FP16基线相匹配。
-
大幅减少的存储器需求使得在给定硬件上运行更大的LLMs成为可能。这对于内存密集型架构(如专家混合)尤为重要。
-
8位激活可以使得在给定内存预算下可能加倍上下文长度,相比16位。将来还可以进一步压缩到4位或更低。
-
1.58比特LLMs在CPU设备上的卓越效率为在边缘/移动设备上部署强大的LLMs开辟了新的可能性,其中CPU是主要处理器。
-
BitNet b1.58的新型低比特计算范式为设计专门针对1比特LLMs的定制AI加速器和系统提供了动力,以充分利用其潜力。
Microsoft将1比特LLMs视为使LLMs在成本上大幅提高而保留其功能的高度有前途的途径。他们设想了一个新时代,在这个时代中,1比特模型将为从数据中心到边缘的应用提供动力。然而,要实现这个未来,需要协同设计模型架构、硬件和软件系统,充分发挥这些模型的独特特性。BitNet b1.58为这个新时代的LLMs奠定了一个令人激动的起点。
结论
BitNet b1.58代表了在保持性能的同时将大型语言模型推到量化极限的重大突破。通过利用三值(1)权重和8位激活值,它在内存使用、延迟和能量消耗大幅降低的同时,与FP16 LLMs在困惑度和终端任务性能方面相匹配。
1.58比特架构为LLMs建立了一个新的Pareto边界,可以以较低的成本运行更大的模型。它开辟了新的可能性,如本地支持更长的上下文、在边缘设备上部署强大的LLMs,并推动了为低比特人工智能设计定制硬件的动力。
Microsoft的工作表明,高度量化的LLMs不仅是可行的,而且实际上建立了与FP16模型相比的优越的缩放规律。通过进一步协同设计架构、硬件和软件,1比特LLMs有潜力将云端到边缘的成本效益高的人工智能能力推向下一个重大飞跃。BitNet b1.58为这个令人兴奋的超高效大型语言模型的新时代提供了一个令人印象深刻的起点。