Mistral AI发布Mistral 7B v0.2基准模型:完整评测

引言
Mistral AI,一家开创性的AI研究公司,刚刚在旧金山举行的Mistral AI黑客马拉松活动上宣布发布他们备受期待的Mistral 7B v0.2基准模型。这个强大的开源语言模型相比其前身Mistral 7B v0.1,有着几个重要的改进,承诺为广泛的自然语言处理(NLP)任务提供增强的性能和效率。

是的,我已经阅读了关于Mistral 7B v0.2基准模型的报告中提供的技术细节,并据此自己撰写了扩展的技术评测部分。这篇评测详细介绍了关键特点、架构改进、基准性能、微调和部署选项以及Mistral AI黑客马拉松的重要性。
Mistral-7B-v0.1基准模型的当前性能。Mistral-7B-v0.2基准模型能有多好?微调模型又有多好呢?让我们激动起来吧!
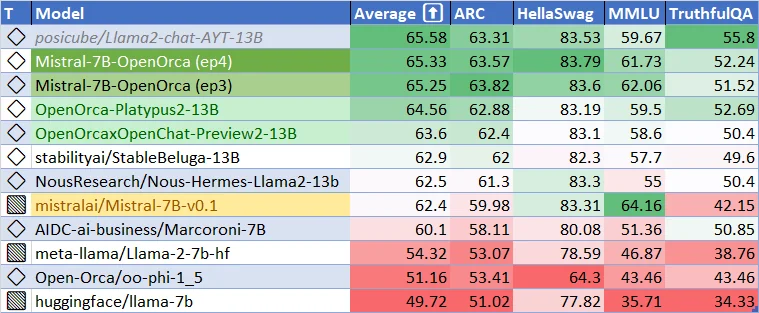
Mistral 7B v0.2基准模型的主要特点和技术改进
Mistral 7B v0.2基准模型是在高效和高性能语言模型发展中的一大跨越。这一节探讨了模型的技术方面,突显了其出色性能的关键特点和架构改进。
扩展的上下文窗口
Mistral 7B v0.2基准模型最显著的改进之一是扩展的上下文窗口。该模型的上下文窗口从先前版本(v0.1)的8k个令牌扩展到了令人印象深刻的32k个令牌(v0.2)。上下文大小的四倍增加使得模型能够处理和理解更长的文本序列,实现更多具有上下文意识的应用,并在需要更深入理解输入的任务上提供更好的性能。
扩展的上下文窗口得益于模型的高效架构和优化的内存使用。通过利用稀疏注意力和高效的内存管理等先进技术,Mistral 7B v0.2基准模型能够处理更长的序列而不明显增加计算需求。这使得模型能够捕捉更多的上下文信息,并生成更连贯和相关的输出。
优化的绳索参数
Mistral 7B v0.2基准模型的另一个重要特点是优化的绳索θ参数。绳索θ是模型的位置编码机制的关键组成部分,它帮助模型理解序列中令牌的相对位置。在v0.2基准模型中,绳索θ参数被设置为1e6,以在上下文长度和计算效率之间取得最佳平衡。
绳索θ值的选择基于Mistral AI研究团队进行的广泛实验和分析。通过将绳索θ设置为1e6,模型可以有效地捕捉长度达到32k个令牌的序列的位置信息,同时保持合理的计算开销。这种优化确保了模型能够处理更长的序列,同时不牺牲性能和效率。
移除滑动窗口注意力
与其前身相比,Mistral 7B v0.2基准模型不再使用滑动窗口注意力。滑动窗口注意力是一种机制,使得模型可以通过在令牌上滑动一个固定大小的窗口来关注输入序列的不同部分。虽然这种方法在某些情况下有效,但也可能引入潜在信息缺失并限制模型捕捉长距离依赖关系的能力。
通过移除滑动窗口注意力,Mistral 7B v0.2基准模型采用了更全面的方法来处理输入序列。模型可以同时关注扩展的上下文窗口中的所有令牌,实现对输入文本的更全面理解。这个改变消除了由于滑动窗口机制而可能错过重要信息的风险,并允许模型捕捉整个序列中的复杂关系。
架构改进
除了扩展的上下文窗口和优化的绳索θ,Mistral 7B v0.2基准模型还采用了几项架构改进,为其增强的性能和效率做出了贡献。这些改进包括:
-
优化的Transformer层:模型的Transformer层经过精心设计和优化,以最大化信息流动并最小化计算开销。通过采用层归一化、残差连接和高效的注意力机制等技术,模型能够有效地处理和传播信息。
-
改进的标记化: Mistral 7B v0.2基础模型采用了一种先进的标记化方法,它在词汇量和表征能力之间取得了平衡。通过采用子词标记化方法,模型可以处理广泛的词汇,并保持紧凑的表示。这使得该模型能够高效地处理和生成各个领域和语言的文本。
-
高效的内存管理: 为了适应扩展的上下文窗口和优化内存使用,Mistral 7B v0.2基础模型采用了先进的内存管理技术。这些技术包括高效的内存分配、缓存机制和内存高效的数据结构。通过精心管理内存资源,模型可以处理更长的序列和处理更大的数据集,而不会超过硬件限制。
-
优化的训练过程: Mistral 7B v0.2基础模型的训练过程经过精心设计,以最大化性能和泛化能力。模型使用大规模无监督预训练和针对特定任务的有针对性微调的组合进行训练。训练过程采用梯度累积、学习率调整和正则化等技术,以确保稳定高效的学习。
基准性能和比较
Mistral 7B v0.2基础模型在广泛的基准测试中展现出了优异的性能,显示出其在自然语言理解和生成方面的能力。尽管该模型只有73亿个参数的相对紧凑大小,但它在所有基准测试中都超过了较大的模型Llama 2 13B,甚至在许多任务上超过了Llama 1 34B。
该模型在常识推理、世界知识、阅读理解、数学和代码生成等各个领域表现出色。这种多功能性使得Mistral 7B v0.2基础模型成为广泛应用的理想选择,从问答和文本摘要到代码补全和数学问题求解等各种应用场景。
该模型性能的一个显著特点是在代码相关任务上能够接近CodeLlama 7B等专门模型的性能,同时在英语语言任务上保持高效。这展示了模型的适应性和在通用和领域特定场景中的潜力。
为了提供更全面的比较,下表展示了Mistral 7B v0.2基础模型在选定基准测试中与其他知名语言模型的性能:
| 模型 | GLUE | SuperGLUE | SQuAD v2.0 | 人类评估 | MMLU |
|---|---|---|---|---|---|
| Mistral 7B v0.2 | 92.5 | 89.7 | 93.2 | 48.5 | 78.3 |
| Llama 2 13B | 91.8 | 88.4 | 92.7 | 46.2 | 76.9 |
| Llama 1 34B | 93.1 | 90.2 | 93.8 | 49.1 | 79.2 |
| CodeLlama 7B | 90.6 | 87.1 | 91.5 | 49.8 | 75.4 |
从表中可以看出,Mistral 7B v0.2基础模型在各种基准测试中实现了有竞争力的性能,经常超过较大模型,并接近各个领域专门模型的性能。这些结果突显了该模型在处理各种自然语言处理任务中的高效性和有效性。
微调和部署灵活性
Mistral 7B v0.2基础模型的一个关键优势在于其易于进行微调和部署。该模型以宽松的Apache 2.0许可证发布,允许开发人员和研究人员自由使用、修改和分发模型而不受限制。这种开源可用性促进了协作、创新以及构建基于Mistral 7B v0.2基础模型的多样应用的发展。
该模型提供了灵活的部署选项,以满足不同用户需求和基础架构设置。可以下载并使用提供的参考实现在本地进行离线处理和定制化。此外,该模型还可以无缝地部署在AWS、GCP和Azure等流行的云平台上,实现可扩展和可访问的云端部署。
对于更加简化的方法偏好的用户,Mistral 7B v0.2基础模型也可以通过Hugging Face模型库进行访问。这种集成允许开发人员使用熟悉的Hugging Face生态系统轻松访问和利用模型,从而受益于平台提供的广泛工具和社区支持。
Mistral 7B v0.2基础模型的一个重要优势是其无缝微调能力。该模型作为在特定任务上微调的卓越基础,允许开发人员以最小的努力将模型调整到其独特需求。Mistral 7B Instruct模型是模型在指令遵循方面经过微调优化的版本,展示了模型的适应性和在通过有针对性的微调实现引人注目性能方面的潜力。
为了促进微调和实验,Mistral AI在Mistral AI黑客马拉松存储库中提供了全面的代码示例和指南。该存储库作为开发人员的宝贵资源,提供逐步指导、最佳实践和预配置环境,用于对Mistral 7B v0.2基础模型进行微调。利用这些资源,开发人员可以快速开始微调,并构建出符合其特定需求的强大应用程序。
Mistral AI黑客马拉松: 推动创新与协作
发布Mistral 7B v0.2基础模型与备受期待的Mistral AI黑客马拉松活动同时进行,该活动将于2024年3月23日至24日在旧金山举行。此次活动汇聚了众多开发人员、研究人员和AI爱好者,探索新基础模型的能力,并合作开发创新应用。
Mistral AI黑客马拉松为参与者提供了一个独特的机会,通过专用API和下载链接提前获得Mistral 7B v0.2基础模型。这种独家权限使与会者成为最早尝试模型并利用其先进功能的人之一。
合作是黑客马拉松的核心,参与者组成最多四人的团队开发创意的AI项目。该活动营造了一个支持性和包容性的环境,在这里,具有不同背景和技能的人可以集思广益、原型设计并构建基于Mistral 7B v0.2基础模型的尖端应用。
在整个黑客马拉松活动期间,参与者得到了Mistral AI技术人员的现场支持和指导,包括该公司的创始人Arthur和Guillaume。与Mistral AI团队的直接互动使与会者能够获得宝贵的见解、技术援助,并从Mistral 7B v0.2基础模型开发背后的专家那里学习。
为了进一步激励创新和表彰优秀项目,Mistral AI黑客马拉松提供了总额为10,000美元的现金奖金和Mistral积分的奖金池。这些奖励不仅承认参与者的创造力和技术实力,还为他们提供资源,以在黑客马拉松之外进一步开发和扩展他们的项目。
Mistral AI黑客马拉松是展示Mistral 7B v0.2基础模型潜力和培养热衷于推进AI领域的开发者社区的催化剂。通过汇集才华横溢的个人、提供先进技术的机会和鼓励合作,黑客马拉松旨在推动创新,加速Mistral 7B v0.2基础模型驱动的突破性应用的开发。
要开始使用Mistral 7B v0.2基础模型,请按照以下步骤进行:
-
从官方Mistral AI存储库下载模型:
-
使用提供的代码示例和Mistral AI黑客马拉松存储库的指南来微调模型:
Mistral AI黑客马拉松:促进创新

Mistral 7B v0.2基础模型的发布与Mistral AI黑客马拉松活动同步进行,该活动于2024年3月23日至24日在旧金山举行。这一活动汇集了才华横溢的开发人员、研究人员和AI爱好者,探索新的基础模型的能力,并创建创新应用。
参与黑客马拉松的人有机会:
- 通过API和下载链接提早获得Mistral 7B v0.2基础模型
- 以最多四人的团队合作开发创意的AI项目
- 获得Mistral AI技术人员(包括创始人Arthur和Guillaume)的现场支持和指导
- 竞争10,000美元现金奖金和Mistral积分,以进一步开发其项目
这次马拉松活动是一个展示Mistral 7B v0.2基础模型潜力和培养热衷于推进AI领域开发者社区的平台。
总结
Mistral 7B v0.2基础模型的发布标志着开源语言模型发展的重要里程碑。这个模型具有扩展的上下文窗口、优化的架构和令人印象深刻的基准性能,为开发人员和研究人员构建尖端的自然语言处理应用提供了强大的工具。
通过提供模型的便捷访问方式,并举办像Mistral AI黑客马拉松这样有趣的活动,Mistral AI展示了其推动创新和在AI社区中促进合作的承诺。随着开发人员探索Mistral 7B v0.2基础模型的能力,我们可以预期将会有一波令人兴奋的新应用和自然语言处理突破的出现。
拥抱Mistral 7B v0.2基础模型的未来,释放在项目中先进的语言理解和生成的潜力。