OpenVoice: Sofortige Sprachklonierung für lokale und Cloud-Bereitstellung
- Name
- Jennie Rose
Published on
In der sich rasch entwickelnden Landschaft der Sprachsynthesetechnologie hat sich OpenVoice als bahnbrechend erwiesen. Es bietet vielseitige Fähigkeiten zur sofortigen Sprachklonierung, die eine breite Palette von Anwendungen abdecken. Entwickelt vom Team bei MyShell ist OpenVoice eine Open-Source-Lösung, mit der Benutzer eine Sprechervoice aus nur einem kurzen Audioclip reproduzieren und realistische und anpassbare Sprache in mehreren Sprachen generieren können.
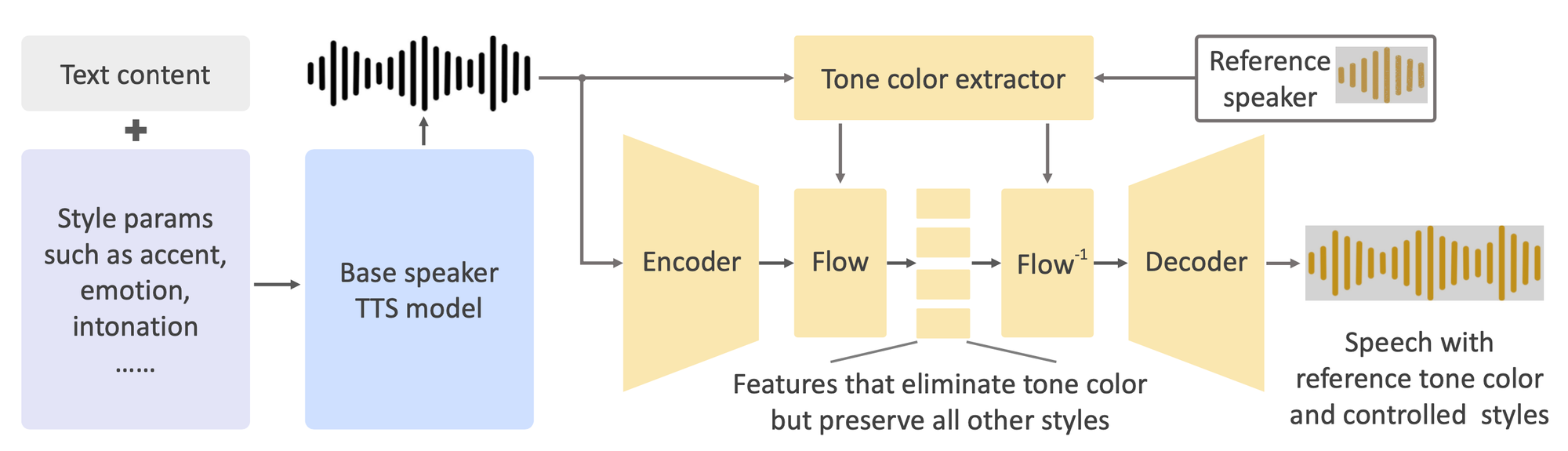
Schlüsselmerkmale von OpenVoice
OpenVoice bietet eine beeindruckende Reihe von Funktionen, die es von anderen Sprachklonierungslösungen unterscheiden:
-
Genaue Klonierung der Klangfarbe: OpenVoice kann die Klangfarbe des Referenzsprechers genau klonieren und somit eine Sprache generieren, die der Originalstimme ähnelt. Diese Funktion ist besonders nützlich für Anwendungen, die ein hohes Maß an Authentizität erfordern, wie z.B. Hörbuchnarration oder personalisierte virtuelle Assistenten.
-
Flexible Steuerung des Sprachstils: Eine der herausragenden Funktionen von OpenVoice ist die Möglichkeit, eine granulare Kontrolle über verschiedene Sprachstilparameter zu bieten. Benutzer können Attribute wie Emotion, Akzent, Rhythmus, Pausen und Intonation anpassen, was eine Vielzahl von Ausdrucksmöglichkeiten ermöglicht. Diese Flexibilität ermöglicht es Benutzern, die generierte Sprache an bestimmte Kontexte oder Vorlieben anzupassen.
-
Sprachübergreifende Klonierung ohne Vorbereitung: OpenVoice ermöglicht bemerkenswerte sprachübergreifende Klonierung ohne Vorbereitung, d.h. es kann Sprache in Sprachen generieren, die nicht in den Trainingsdaten enthalten waren. Diese Fähigkeit eröffnet spannende Möglichkeiten zur Erstellung lokalisierter Inhalte oder zur Erreichung eines globalen Publikums ohne umfangreiche sprachspezifische Trainingsdaten.
Leistungsbewertungen
Um die Leistung von OpenVoice zu bewerten, hat das MyShell-Team umfangreiche Tests mit verschiedenen GPU-Konfigurationen durchgeführt. Die Ergebnisse zeigen die beeindruckende Effizienz und Kosteneffizienz von OpenVoice im Vergleich zu anderen Text-to-Speech-APIs.
| GPU | Wörter pro Sekunde | Wörter pro Dollar |
|---|---|---|
| RTX 2070 | 132,7 | 6,6 Millionen |
| RTX 3080 Ti | 230,4 | 4,53 Millionen |
Die Tests zeigen, dass die RTX 2070 GPU erstaunliche 6,6 Millionen Wörter pro Dollar verarbeiten kann, was sie zu einer außergewöhnlich kosteneffektiven Option für Sprachklonierungsprojekte im großen Maßstab macht. Die RTX 3080 Ti hingegen bietet die höchste Rohverarbeitungsgeschwindigkeit und erreicht rund 230,4 Wörter pro Sekunde, was sie für Anwendungen geeignet macht, bei denen schnelle Bearbeitungszeiten oberste Priorität haben.
Es ist erwähnenswert, dass sich diese Leistungsbewertungen auf Einzelgewindeoperationen konzentrierten und dass das Potenzial für Mehrfachgewindeverarbeitung auf leistungsstärkeren GPUs wie der RTX 3080 Ti die Leistung weiter verbessern und die Kosteneffizienzlücke verringern könnte.
Lokale Ausführung von OpenVoice
Ein großer Vorteil von OpenVoice ist die Möglichkeit, es lokal auszuführen. Dadurch haben Benutzer eine größere Kontrolle, mehr Datenschutz und Kosteneinsparungen im Vergleich zur ausschließlichen Nutzung von Cloud-basierten APIs. Hier finden Sie eine Schritt-für-Schritt-Anleitung zur Einrichtung und Ausführung von OpenVoice auf Ihrem lokalen Gerät:
-
Voraussetzungen: Stellen Sie sicher, dass Sie eine kompatible GPU (NVIDIA GPU mit CUDA-Unterstützung) und die erforderlichen Abhängigkeiten installiert haben, einschließlich Python, PyTorch und CUDA-Toolkit.
-
Repository klonen: Klonen Sie das OpenVoice-Repository von der offiziellen GitHub-Seite mit dem folgenden Befehl:
git clone https://github.com/myshell-ai/OpenVoice.git -
Abhängigkeiten installieren: Navigieren Sie zum geklonten Repository-Verzeichnis und installieren Sie die erforderlichen Python-Pakete mit pip:
cd OpenVoice pip install -r requirements.txt -
Modell vorbereiten: Laden Sie die vortrainierten Modellprüfpunkte herunter und platzieren Sie sie im zugewiesenen Verzeichnis innerhalb des Repositories. Die spezifischen Anweisungen zum Erhalten der Prüfpunkte finden Sie in der OpenVoice-Dokumentation.
-
Einstellungen konfigurieren: Passen Sie die Konfigurationsdateien (
config.jsonoderconfig.yaml) an, um die gewünschten Einstellungen festzulegen, wie z.B. das Eingabeaudioformat, das Ausgabeverzeichnis und die Sprachstilparameter. -
Sprachklonierung ausführen: Führen Sie das Hauptskript aus, um die Sprachklonierung auf Ihrem lokalen Gerät durchzuführen. Geben Sie den Pfad zum Referenzaudioclip und den Zieltext als Argumente an:
python main.py --reference_audio path/to/reference.wav --text "Hallo, dies ist ein Test." -
Ergebnisse bewerten: Die generierte Sprache wird im angegebenen Ausgabeverzeichnis gespeichert. Hören Sie sich die synthetisierte Audio an und bewerten Sie ihre Qualität, Natürlichkeit und Ähnlichkeit zur Referenzstimme. Feinabstimmen Sie die Einstellungen und experimentieren Sie mit verschiedenen Sprachstilparametern, um die gewünschten Ergebnisse zu erzielen.
Durch die lokale Ausführung von OpenVoice können Sie die Vorteile der sofortigen Sprachklonierung nutzen, ohne auf externe APIs angewiesen zu sein. Dadurch wird die Latenz reduziert und die Datensicherheit gewährleistet. Diese lokale Bereitstellungsoption ist besonders vorteilhaft für Anwendungen mit strengen Sicherheitsanforderungen oder für Benutzer, die die volle Kontrolle über ihre Sprachsynthesepipeline behalten möchten.
Fazit
OpenVoice repräsentiert einen bedeutenden Meilenstein in der Sprachsynthese und bietet eine vielseitige und zugängliche Lösung für sofortige Sprachklonierung. Mit seiner präzisen Klonierung des Tonfarbtons, flexibler Sprachstilsteuerung und zero-shot-übersprachigen Fähigkeiten ermöglicht OpenVoice Benutzern, realistische und ausdrucksstarke Sprache in mehreren Sprachen zu erzeugen.
Die beeindruckenden Leistungsbenchmarks demonstrieren die Kosteneffizienz und Effizienz von OpenVoice und machen es zu einer überzeugenden Wahl für eine Vielzahl von Anwendungen, von Hörbüchern und personalisierten virtuellen Assistenten bis hin zur Erstellung von lokalisiertem Inhalt und darüber hinaus.
Darüber hinaus ermöglicht die Möglichkeit, OpenVoice lokal auszuführen, Benutzern eine größere Kontrolle, Privatsphäre und Kosteneinsparungen und ermöglicht es ihnen, die Leistungsfähigkeit der Sprachklonierung zu nutzen, ohne sich ausschließlich auf cloudbasierte APIs verlassen zu müssen.
Während die Open-Source-Community weiterhin zur Entwicklung und Verbesserung von OpenVoice beiträgt, können wir weitere Fortschritte und Innovationen auf dem Gebiet der Sprachsynthese erwarten. Mit seiner Vielseitigkeit, Zugänglichkeit und beeindruckenden Leistungsfähigkeit steht OpenVoice kurz davor, die Art und Weise, wie wir mit Sprachinhalten interagieren und sie erstellen, zu revolutionieren und aufregende Möglichkeiten für Kreative, Entwickler und Unternehmen gleichermaßen zu eröffnen.
