Beste 10 Vektor-Datenbanken 2023: Eine umfassende Überprüfung

Vektor-Datenbanken sind kein Nischenthema mehr, das nur unter Datenwissenschaftlern und Datenbankadministratoren diskutiert wird. Wenn wir in das Jahr 2023 eintreten, sind sie zum Mittelpunkt für alle geworden, die mit komplexen Datentypen wie Bildern, Audio und Text umgehen. Aber was genau sind Vektor-Datenbanken und warum erhalten sie so viel Aufmerksamkeit?
In diesem Artikel werden wir Vektor-Datenbanken entmystifizieren, ihre Vor- und Nachteile auseinandernehmen und den Hype um sie enthüllen. Wir werden Ihnen auch einen exklusiven Blick auf die Top 9 Vektor-Datenbanken von 2023 mit einem besonderen Fokus auf Open-Source-Optionen geben. Tauchen wir also ein!
Möchten Sie die neuesten LLM-Nachrichten erfahren? Schauen Sie sich das neueste LLM-Ranking an!
Was ist eine Vektor-Datenbank?
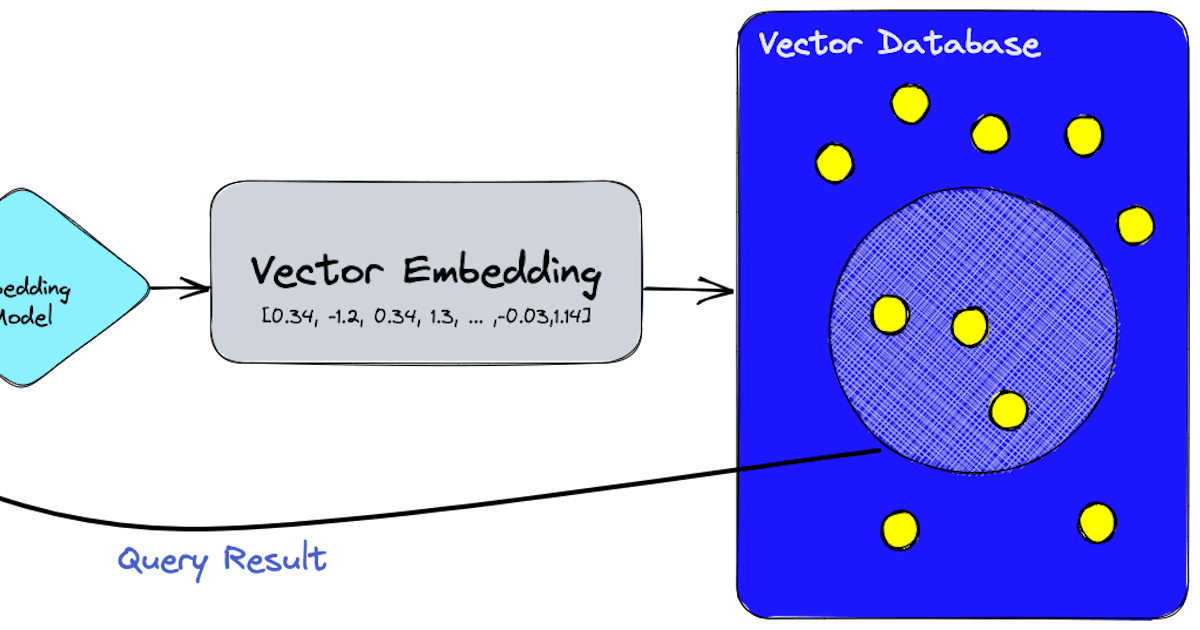
Eine Vektor-Datenbank ist ein spezialisiertes Datenbanktyp, der darauf ausgelegt ist, komplexe Datentypen zu handhaben, mit denen herkömmliche Datenbanken Schwierigkeiten haben. Im Gegensatz zu herkömmlichen relationale Datenbanken, die Daten in Tabellen speichern, verwenden Vektor-Datenbanken mathematische Vektoren, um Daten darzustellen. Dadurch können sie effizient mit hochdimensionalen Daten wie Bildern, Audio-Dateien und Textinhalten umgehen und nach ihnen suchen.
Vektor-Datenbanken verwenden Algorithmen wie k-NN (k-Nächster-Nachbar) für die Suche in den hochdimensionalen Daten. Sie nutzen auch Techniken wie Quantisierung und Partitionierung, um die Suchleistung zu optimieren. Hier ist ein Beispielprompt zur Suche nach ähnlichen Bildern in einer Vektor-Datenbank:
SELECT * FROM images WHERE VECTOR_SEARCH(image_vector, target_vector) < 0.2;In diesem Beispielprompt ist VECTOR_SEARCH eine Funktion, die die Ähnlichkeit zwischen image_vector und target_vector berechnet. Das < 0.2 gibt den Ähnlichkeitsschwellenwert an.
Warum Vektor-Datenbanken anders sind?
-
Handhabung hochdimensionaler Daten: Herkömmliche Datenbanken sind nicht darauf ausgelegt, hochdimensionale Daten zu handhaben. Vektor-Datenbanken füllen diese Lücke, indem sie mathematische Vektoren zur Repräsentation verwenden und es somit einfacher machen, mit komplexen Datentypen umzugehen.
-
Schnelle Suchmöglichkeiten: Eine der herausragenden Funktionen von Vektor-Datenbanken ist ihre Fähigkeit, schnelle Ähnlichkeitssuchen durchzuführen. Wenn Sie beispielsweise ein Bild haben, kann eine Vektor-Datenbank schnell ähnliche Bilder in der Datenbank finden, ohne jeden Eintrag scannen zu müssen.
-
Skalierbarkeit: Mit zunehmenden Datenmengen wird die Notwendigkeit von Datenbanken, die ohne Leistungsabfall skalieren können, immer wichtiger. Vektor-Datenbanken sind mit Skalierbarkeit im Hinterkopf entwickelt, sodass sie große Datenmengen effizient handhaben können.
Überprüfung der Vektor-Datenbanken: Erfüllen sie den Hype?
Wie bei jeder aufkommenden Technologie waren Vektor-Datenbanken von einer beträchtlichen Menge an Hype umgeben. Viele behaupten, sie seien das nächste große Ding in der Datenbanktechnologie und ziehen Parallelen zur NoSQL-Bewegung, die vor einem Jahrzehnt die Datenbanklandschaft durcheinander brachte. Aber wie viel davon ist wahr, und worauf sollten Sie achten?
Die harte Wahrheit über Vektor-Datenbanken: Sollten Sie sich anpassen?
Der Hype ist nicht völlig unbegründet. Vektor-Datenbanken bieten tatsächlich einzigartige Möglichkeiten, die herkömmliche Datenbanken nicht haben, insbesondere wenn es um den Umgang mit komplexen, hochdimensionalen Daten geht. Es ist jedoch wichtig, die Spreu vom Weizen zu trennen. Nicht alle Vektor-Datenbanken erfüllen den Hype, und einige legen mehr Wert auf Marketing als auf eine robuste Funktionalität.
Worauf Sie achten sollten, wenn Sie Vektor-Datenbanken auswählen:
-
Übertriebene Versprechen: Einige Vektor-Datenbanken versprechen viel, liefern jedoch nicht wesentliche Funktionen wie hohe Verfügbarkeit, Sicherungssysteme und fortgeschrittene Datentypen wie Geodaten und Datumsangaben.
-
Komplexität: Obwohl Vektor-Datenbanken leistungsstark sind, können sie auch komplex sein, wenn es darum geht, sie einzurichten und zu verwalten. Stellen Sie sicher, dass Sie über das technische Know-how verfügen, um sie zu handhaben, oder seien Sie bereit, in Schulungen zu investieren.
-
Kosten: Achten Sie auf versteckte Kosten, insbesondere bei proprietären Datenbanken. Lizenzgebühren können sich summieren, und Sie müssen möglicherweise auch in spezielle Hardware investieren.
Indem Sie sich dieser Punkte bewusst sind, können Sie dem Hype entgegentreten und eine informiertere Entscheidung treffen. Denken Sie immer daran, über die Marketing-Buzzwords hinauszusehen und sich eingehend mit den tatsächlichen Funktionen und Einschränkungen der Datenbank auseinanderzusetzen.
Vorteile vs Nachteile von Vektor-Datenbanken
Vektor-Datenbanken gewinnen an Bedeutung wegen ihrer Fähigkeit, komplexe Datentypen wie Bilder, Audio und Text zu handhaben. Es ist jedoch wichtig, sowohl ihre Vorteile als auch ihre Einschränkungen zu verstehen.
Vorteile von Vektor-Datenbanken:
-
Effiziente Ähnlichkeitssuche: Vektor-Datenbanken sind hervorragend darin, die nächsten Nachbarn in hochdimensionalen Räumen zu finden, was für Empfehlungssysteme, Bilderkennung und natürliche Sprachverarbeitung entscheidend ist.
-
Skalierbarkeit: Viele Vektor-Datenbanken sind darauf ausgelegt, große Datenmengen zu handhaben, einige bieten sogar verteilte Architekturen für horizontale Skalierung.
-
Flexibilität: Mit Unterstützung für verschiedene Distanzmetriken und Indexierungsalgorithmen können sich Vektor-Datenbanken sehr gut an spezifische Anwendungsfälle anpassen.
-
Ressourcenintensiv: Schnelle Suche geht oft mit dem Verbrauch von Rechenressourcen einher. Einige Datenbanken erfordern spezielle Hardware für optimale Leistung.
Nachteile von Vektor-Datenbanken:
- Komplexität: Die Vielzahl an algorithmischen Optionen und Konfigurationen kann Vektor-Datenbanken herausfordernd machen, einzurichten und zu pflegen.
- Kosten: Während es Open-Source-Optionen gibt, können kommerzielle Vektordatenbanken teuer sein, insbesondere für groß angelegte Bereitstellungen.
Top 10 Vektordatenbanken, die 2023 in Betracht gezogen werden sollten
Top Open-Source-Vektordatenbanken im Jahr 2023
1. Faiss
- Startpreis: Kostenlos (Open-Source)
- Bewertung: 4,7/5
- Vorteile:
- Außergewöhnliche GPU-Beschleunigung über CUDA
- Unterstützt Milliarden von Vektoren
- Umfangreiche algorithmische Optionen wie IVFADC, PQ und HNSW
- Nachteile:
- Erfordert Fachkenntnisse in der Vektorquantisierung
- Beschränkt auf Single-Node-Bereitstellungen
Technische Details: Faiss (opens in a new tab) verwendet verschiedene Indexierungstechniken, einschließlich Inverted File Segmenter (IVF) und Scalar Quantizer (SQ), für effiziente Ähnlichkeitssuchen. Es unterstützt auch die Stapelanfrageverarbeitung und Parallelisierung über mehrere GPUs hinweg. Die Bibliothek ist für die L2-Distanz und die Ähnlichkeit des inneren Produkts optimiert und daher vielseitig für verschiedene Anwendungsfälle geeignet.
Faiss Vector Database GitHub: https://github.com/facebookresearch/faiss (opens in a new tab)

2. Annoy (Approximate Nearest Neighbors Oh Yeah)
- Startpreis: Kostenlos (Open-Source)
- Bewertung: 4,5/5
- Vorteile:
- Verwendet Wald-von-Bäumen zur Partitionierung des Vektorraums
- Unterstützt speicherabbildungsdateibasierte Unterstützung für Daten im großen Maßstab
- Asymptotische Komplexität von Abfragen ist (O(\log N))
- Nachteile:
- Beschränkt auf die Abstandsmetriken Angular, Euklidisch, Manhattan und Hamming
- Keine native Unterstützung für verteiltes Rechnen
Technische Details: Annoy Vector Database (opens in a new tab) erstellt für jeden Vektor einen binären Baum, der den Raum in Halbräume partitioniert. Die Bäume werden dann für die effiziente Suche nach dem nächsten Nachbarn verwendet. Es unterstützt auch mehrfädige Build-Zeiten und ermöglicht das Speichern von Indizes auf der Festplatte, die später für Ähnlichkeitssuchen im großen Maßstab mithilfe von Speicherabbildungen verwendet werden können.
Annoy Vector Database GitHub: https://github.com/spotify/annoy (opens in a new tab)
3. NMSLIB (Non-Metric Space Library)
- Startpreis: Kostenlos (Open-Source)
- Bewertung: 4,6/5
- Vorteile:
- Unterstützt eine Vielzahl von Abstandsmetriken wie Cosinus, Jaccard und Levenshtein
- Verwendet hierarchische navigierbare Small-World-(HNSW)-Graphen für effiziente Suche
- Optimal für dichte und spärliche Datenvektoren
- Nachteile:
- Hohe Lernkurve aufgrund umfangreicher algorithmischer Optionen
- Begrenzte Unterstützung und Dokumentation durch die Community
Technische Details: NMSLIB Vector Database (opens in a new tab) verwendet fortschrittliche Algorithmen wie VP-Trees, SW-Graph und HNSW für die Indexierung. Es unterstützt auch Approximate Nearest Neighbor (ANN) Search, sodass ein Gleichgewicht zwischen Abfrageleistung und Genauigkeit hergestellt werden kann. Die Bibliothek ist für latenzarme, durchsatzstarke Leistung optimiert und eignet sich daher für Echtzeit-Anwendungen.
NMSLIB Vector Database GitHub: https://github.com/nmslib/nmslib (opens in a new tab)
Kommerzielle Vektordatenbanken: Lohnt sich der Hype?
4. Milvus
- Startpreis: Kostenlos (Open-Source)
- Bewertung: 4,2/5
- Vorteile:
- Skalierbarkeit: Verarbeitung von bis zu 100 Milliarden Vektoren mit einer Latenz von unter einer Sekunde.
- Distanzmetriken: Unterstützt euklidische, kosinale und Jaccard-Metriken. Unterstützt Indextypen wie IVF_FLAT, IVF_PQ und HNSW.
- Nachteile:
- Datentypen: Keine Unterstützung für geografische und Datumsdatentypen.
- Backup: Kein integriertes Backup-System.
- Authentifizierung: Inkonsistente Sicherheitsfunktionen.
- Erfordert zusätzliche Komponenten wie MySQL oder SQLite für die Speicherung von Metadaten.
- Begrenzte transaktionale Unterstützung, nicht geeignet für ACID-konforme Anwendungen
Vorteile von Milvus: Milvus ist für Cloud-native Umgebungen konzipiert und unterstützt horizontales Skalieren. Es verwendet ein Hybrid-Indexsystem, das baumbasierte und hashbasierte Indexierungsverfahren für effiziente Datenabfrage kombiniert. Das System unterstützt auch Vektorbeschneidung und Abfragefilterung für komplexere Suchbedingungen.
Nachteile von Milvus: Milvus mag zwar Open-Source und skalierbar sein, aber es hat auch seine Grenzen. Es unterstützt keine fortgeschrittenen Datentypen wie geografische und datumsbezogene Informationen. Dies ist eine bedeutende Lücke für Anwendungen in GIS und Zeitreihenanalyse. Es gibt auch kein integriertes Backup-System, was ein kritischer Mangel ist. Die inkonsistente Implementierung von Sicherheitsfunktionen wie OAuth und LDAP ist eine weitere Bedenken.

5. Pinecone
- Startpreis: Beginnt bei $30/Monat
- Bewertung: 3,9/5
- Vorteile:
- Vollständig verwalteter Service
- Eingebaute Datenversionierung und Rollback-Funktionen
- Unterstützt Mandantenfähigkeit
- Nachteile:
- Kosten: Die Kosten können bei größeren Bereitstellungen schnell ansteigen, insbesondere mit steigender Datengröße.
- Begrenzte Funktionen: Keine Joins, Transaktionen oder erweiterte Indizierung.
- Dokumentation: Sparse technische Dokumentation.
- Begrenzte Anpassungsmöglichkeiten aufgrund der verwalteten Natur
Vorteile von Pinecone: Pinecone verwendet einen proprietären Vektorindexierungsalgorithmus, der für dichte und spärliche Vektoren optimiert ist. Es verwendet eine verteilte, geschärfte Architektur für Skalierbarkeit und bietet RESTful APIs für eine einfache Integration. Die fehlende Zugriffsmöglichkeit auf den Quellcode kann jedoch für diejenigen, die die Funktionalität erweitern oder anpassen möchten, eine Einschränkung darstellen.
Nachteile von Pinecone: Die kommerzielle Natur von Pinecone geht mit hohen Kosten einher, insbesondere für große Datensätze. Es bietet keine Unterstützung für Joins und Transaktionen, die für komplexe Datenoperationen unerlässlich sind. Die spärliche technische Dokumentation ist ein Warnsignal, das darauf hinweist, dass das Produkt möglicherweise nicht den Marketinghype erfüllt.

6. Zilliz
- Startpreis: Individuelle Preisgestaltung
- Bewertung: 3,7/5
- Vorteile:
- REST-API: Einfache Integration in bestehende Anwendungen.
- Attributsuche: Grundlegende Attributsuchoperationen werden unterstützt.
- Cloud-basiert: Skalierbarkeit ohne betrieblichen Overhead.
- Nachteile:
- Kosten: Exponentielle Preise mit der Datenmenge.
- Eingeschränkte Funktionen: Keine Joins, Transaktionen oder erweiterte Indizierung.
- Dokumentation: Spärliche technische Dokumentation.
- Fehlen fortgeschrittener Datentypen wie geografischer und zeitlicher Daten.
Vorteile von Zilliz: Zilliz verwendet verschiedene Indexierungs-Algorithmen, einschließlich IVF_SQ8 und NSG, und unterstützt GPU-Beschleunigung für schnellere Abfrageverarbeitung. Es bietet auch eine SQL-ähnliche Abfragesprache, die komplexere Suchbedingungen ermöglicht. Die fehlende Transparenz in Bezug auf die hochverfügbaren Funktionen wirft jedoch Fragen hinsichtlich der Eignung für geschäftskritische Anwendungen auf.
Nachteile von Zilliz: Zilliz fehlen wesentliche Funktionen wie Joins und Transaktionen, wodurch es für ernsthafte Anwendungen unzuverlässig ist. Das Fehlen von Hochverfügbarkeitsfunktionen wie Datenreplikation und automatischem Failover birgt ein Risiko. Das Backup-System ist unzureichend und erfordert zusätzliche Ressourcen für die Datenwiederherstellung.

Wie man Vektor-Datenbanken bewertet
Bei der Bewertung von Vektordatenbanken sollten Sie folgende technische Aspekte berücksichtigen:
- Funktionsumfang: Unterstützt sie Joins, Transaktionen und fortgeschrittene Datentypen?
- Skalierbarkeit: Kann sie große Datenmengen effizient verarbeiten?
- Kosten: Wie skaliert die Preisgestaltung mit den angebotenen Funktionen?
- Community-Support: Gibt es aktiven Community-Support und umfangreiche Dokumentation?
- Benchmarking: Verwenden Sie Leistungsbenchmarks wie Anfragen pro Sekunde (QPS), Latenz und Durchsatz für den Vergleich.
Für weitere Details können Sie die von diesem GitHub Repository (opens in a new tab) bereitgestellten Tools als Benchmark für Vektordatenbanken ausführen.
Die besten Open-Source-Alternativen für Vektordatenbanken im Jahr 2023
7. Qdrant: Die Wahl der Community
- Startpreis: Kostenlos (Open Source)
- Bewertung: 4,5/5
Vorteile:
- Lokal und Cloud-basiert: Bietet beide Bereitstellungsoptionen und flexiblen Einsatz.
- In-Memory-Modus: Ermöglicht Tests ohne das Starten eines Containers.
- Migration-freundlich: Erfahrung mit vielen Migrationen von anderen Tools.
Nachteile:
- Dokumentation: Könnte von umfassenderen Anleitungen profitieren.
- Community-Größe: Kleinere Community im Vergleich zu anderen Open-Source-Optionen.
- Funktionsumfang: Wächst immer noch und es fehlen möglicherweise einige fortgeschrittene Funktionen.
Technische Details: Qdrant (opens in a new tab) bietet sowohl lokale als auch cloud-basierte Optionen, was es zu einer flexiblen Wahl macht. Es verfügt jedoch über eine kleinere Community und könnte von umfassenderer Dokumentation profitieren. Obwohl es an Popularität gewinnt, wächst der Funktionsumfang immer noch und es fehlen möglicherweise einige fortgeschrittene Optionen.
Qdrant Link: https://qdrant.tech/ (opens in a new tab)

8. Cassandra/AstraDB: Der König der Skalierbarkeit
Startpreis: Kostenlose Stufe verfügbar Bewertung: 4,3/5
Vorteile:
- Skalierbarkeit: Bekannt für die Bewältigung großer Durchsatzmengen ohne Absturz.
- Lokal und Cloud-basiert: Beide Bereitstellungsoptionen sind verfügbar.
- Branchenanerkennung: Hält seit Jahren seine Position in der Branche.
Nachteile:
- Komplexität: Steilere Lernkurve für neue Benutzer.
- Kosten: Kostenlose Stufe hat Einschränkungen und die Preise können steigen.
- Vektoren-Unterstützung: Nicht ursprünglich für Vektordaten konzipiert, daher fehlen möglicherweise einige Funktionen.
Technische Details: Apache Cassandra (opens in a new tab)/DataStax AstraDB (opens in a new tab) eignet sich hervorragend für die Skalierbarkeit, erfordert jedoch eine steilere Lernkurve. obwohl es eine kostenlose Stufe anbietet, können die Einschränkungen schnell erreicht werden, was zu steigenden Kosten führt. Es wurde auch nicht ursprünglich für Vektordaten konzipiert, daher fehlen möglicherweise einige spezialisierte Funktionen.
Apache Cassandra: https://cassandra.apache.org (opens in a new tab) DataStax AstraDB: https://www.datastax.com/products/datastax-astra (opens in a new tab)

9. MyScale DB: Der SQL-Allrounder als Pinecone-Alternative
Startpreis: Großzügige kostenlose Stufe Bewertung: 4,1/5
Vorteile:
- SQL-Unterstützung: Vollständige und erweiterte SQL-Unterstützung für alle Datenoperationen.
- Geschwindigkeit: Cloud-native OLAP-Datenbankarchitektur für schnelle Operationen.
- Strukturierte und vektorisierte Daten: Verwaltet beides in einer einzigen Datenbank.
Nachteile:
- Neu: Relativ neu und möglicherweise fehlt es an Community-Support.
- Dokumentation: Könnte von mehr technischen Anleitungen profitieren.
- Komplexität: SQL-Kenntnisse sind erforderlich, was nicht für alle Benutzer geeignet sein könnte.
Technische Details: MyScale DB (opens in a new tab)s bietet eine großzügige kostenlose Stufe und vollständige SQL-Unterstützung, was es zu einer starken Wahl für Benutzer macht, die mit SQL vertraut sind. Als relativ neues Produkt könnte es jedoch an umfangreichem Community-Support fehlen und von einer umfangreicheren technischen Dokumentation profitieren.
MyScale DB: https://myscale.com (opens in a new tab)
10. SPTAG (Space Partition Tree and Graph)
- Startpreis: Kostenlos (Open-Source)
- Bewertung: 4,3/5
- Vorteile:
- Von Microsoft entwickelt, für eine gewisse Zuverlässigkeit.
- K-NN-Suchfunktion mit hoher Geschwindigkeit.
- Optimiert für große Datenbanken mit Milliarden von Vektoren.
- Nachteile:
- Begrenzter Community-Support.
- Die Dokumentation ist nicht so umfangreich wie bei anderen Open-Source-Optionen. Technische Details: SPTAG (opens in a new tab) verwendet KD-Bäume und Ballbäume zur Indizierung und ermöglicht schnelle k-NN-Suchen. Es ist für große Datenbanken optimiert und kann effizient mit Milliarden von Vektoren umgehen. Der Algorithmus unterstützt auch die mehrfädige Suche und die Stapelanfragen-Verarbeitung.
SPTAG GitHub: https://github.com/microsoft/SPTAG (opens in a new tab)
FAQs
Was sind die Haupt-Vektordatenbanken?
Die Haupt-Vektordatenbanken im Jahr 2023 umfassen Faiss, Annoy, NMSLIB, Milvus, Pinecone, Zilliz, Elasticsearch, Weaviate, Jina und SPTAG.
Gibt es eine kostenlose Vektordatenbank?
Ja, es gibt mehrere kostenlose Open-Source-Vektordatenbanken wie Faiss, Annoy, NMSLIB, Milvus, Weaviate, Jina und SPTAG.
Ist Pinecone die beste Vektordatenbank?
Obwohl Pinecone einen vollständig verwalteten Service bietet und einfach zu bedienen ist, hängt es davon ab, ob es "die beste" ist, von Ihren spezifischen Bedürfnissen ab. Es ist nicht Open Source und kann für größere Implementierungen kostspielig sein.
Wie wähle ich eine Vektordatenbank aus?
Die Auswahl einer Vektordatenbank hängt von verschiedenen Faktoren ab, wie zum Beispiel der Art der Daten, mit denen Sie arbeiten, dem Umfang Ihres Projekts und Ihrem Budget. Open-Source-Optionen wie Faiss und Annoy sind hervorragend für diejenigen geeignet, die mehr Kontrolle und Anpassungsmöglichkeiten wünschen, während verwaltete Dienste wie Pinecone möglicherweise besser für diejenigen geeignet sind, die eine einfache Bedienung suchen.
Schlussfolgerung
Vektordatenbanken sind ein wesentliches Werkzeug für die Bearbeitung komplexer, hochdimensionaler Daten. Obwohl sie zahlreiche Vorteile wie effiziente Ähnlichkeitssuche und Skalierbarkeit bieten, haben sie auch ihre eigenen Einschränkungen. Open-Source-Optionen wie Faiss und Annoy bieten eine hervorragende Leistung und Flexibilität, erfordern jedoch möglicherweise eine steile Lernkurve. Auf der anderen Seite bieten kommerzielle Optionen wie Pinecone eine einfache Bedienung, können jedoch teuer sein. Daher ist es wichtig, die Vor- und Nachteile sorgfältig abzuwägen, um die Vektordatenbank auszuwählen, die am besten zu Ihren Bedürfnissen passt.
Möchten Sie die neuesten LLM-News erfahren? Schauen Sie sich das neueste LLM Leaderboard an!
