LlamaIndex vs LangChain: Vergleich von leistungsstarken LLM-Anwendungsfunktionen
- Name
- Lynn Mikami
Published on
Einführung
In der Welt der natürlichen Sprachverarbeitung (NLP) und der großen Sprachmodelle (LLMs) suchen Entwickler ständig nach leistungsstarken Werkzeugen, um modernste Anwendungen zu entwickeln. In diesem Bereich haben sich zwei prominente Frameworks als Spitzenreiter etabliert: LlamaIndex und LangChain. Obwohl beide darauf abzielen, die Integration von LLMs in benutzerdefinierte Anwendungen zu vereinfachen, unterscheiden sie sich in ihrem Ansatz und Fokus. In diesem Artikel werden wir uns ausführlich mit den wichtigsten Unterschieden zwischen LlamaIndex und LangChain befassen und Ihnen helfen, eine fundierte Entscheidung bei der Auswahl eines Frameworks für Ihre Projekte zu treffen.

Teil 1. Was ist LlamaIndex?
LlamaIndex ist ein leistungsstarkes Datenframework, mit dem Sie Ihre eigenen Daten einfach mit LLMs verbinden können. Es bietet flexible Datenanschlüsse zum Einlesen von Daten aus verschiedenen Quellen wie APIs, Datenbanken, PDFs und mehr. Diese privaten Daten werden dann in optimierte Darstellungen indiziert, auf die LLMs im großen Maßstab zugreifen und interpretieren können, ohne das zugrunde liegende Modell neu trainieren zu müssen.
LlamaIndex befähigt LLMs mit einem "Gedächtnis" Ihrer privaten Daten, das sie nutzen können, um fundierte, kontextbezogene Antworten zu geben. Egal, ob Sie einen Chatbot über die Dokumentation Ihres Unternehmens, ein personalisiertes Lebenslaufanalysetool oder einen KI-Assistenten erstellen möchten, der Fragen zu einem bestimmten Wissensbereich beantworten kann - mit LlamaIndex ist dies mit nur wenigen Zeilen Code möglich.
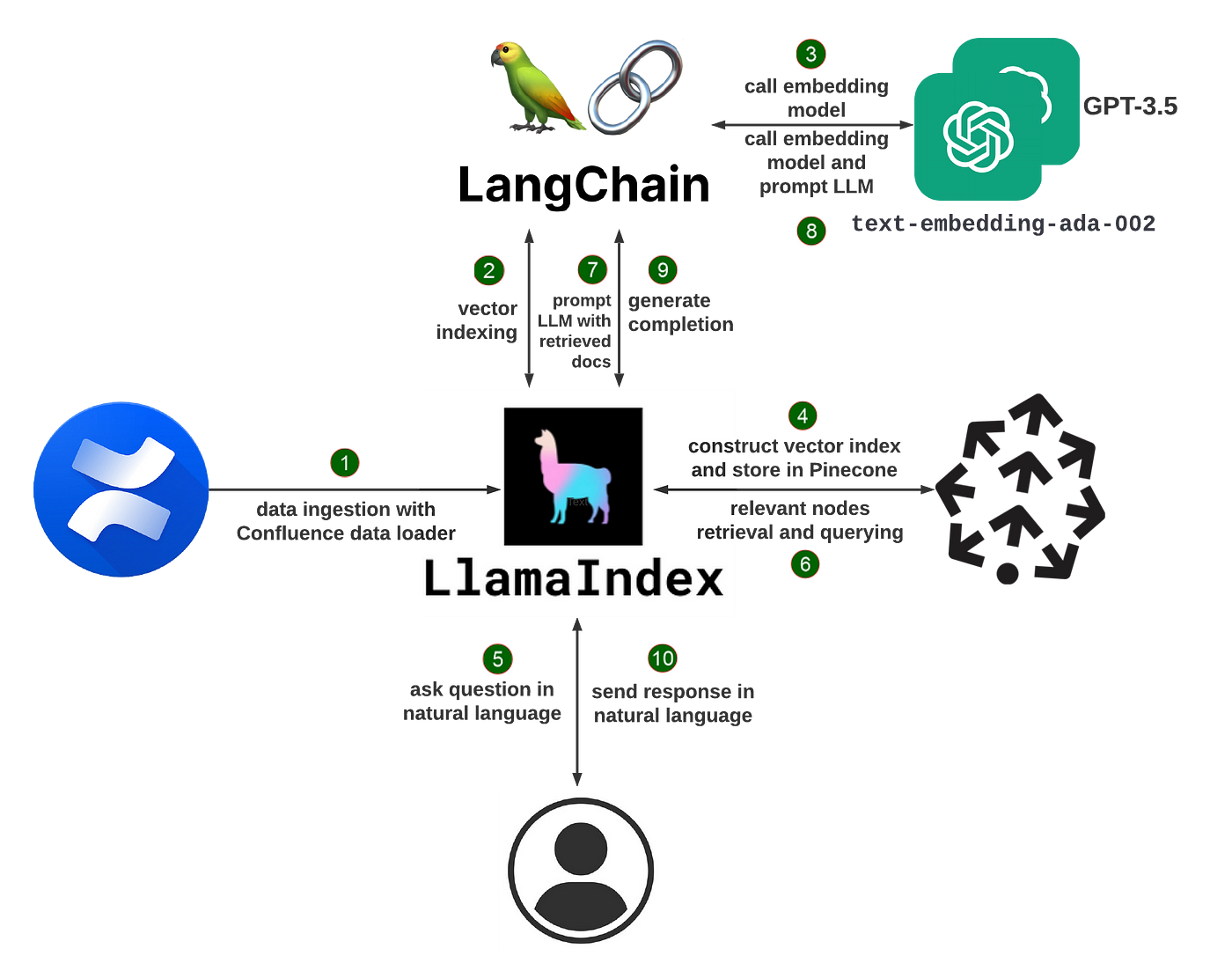
Wie LlamaIndex funktioniert
Im Kern verwendet LlamaIndex eine Technik namens "retrieval augmented generation" (RAG). Ein typisches RAG-System besteht aus zwei Hauptphasen:
-
Indizierungsphase: Während der Indizierung wird Ihre private Daten effizient in einen durchsuchbaren Vektorindex umgewandelt. LlamaIndex kann unstrukturierte Textdokumente, strukturierte Datenbankeinträge, Wissensgraphen und mehr verarbeiten. Die Daten werden in numerische Einbettungen transformiert, die ihre semantische Bedeutung erfassen und später schnelle Ähnlichkeitssuchen ermöglichen.
-
Abfragephase: Wenn ein Benutzer das System abfragt, werden die relevantesten Informationsfragmente aus dem Vektorindex basierend auf der semantischen Ähnlichkeit der Abfrage abgerufen. Zusammen mit der ursprünglichen Abfrage werden diese Fragmente an das LLM übergeben, das eine endgültige Antwort generiert. Durch die dynamische Integration relevanter Informationen kann das LLM qualitativ hochwertigere und sachlichere Antworten generieren als allein auf Basis seines Grundwissens.
LlamaIndex vereinfacht einen Großteil der Komplexität beim Aufbau eines RAG-Systems. Es bietet sowohl hochrangige APIs, mit denen Sie mit nur wenigen Zeilen Code starten können, als auch Tools auf niedrigerer Ebene zur feingliedrigen Anpassung der Datentransformation.
Erstellen eines Chatbots mit Lebenslaufanalyse mithilfe von LlamaIndex
Um die Möglichkeiten von LlamaIndex zu veranschaulichen, gehen wir den Aufbau eines Chatbots durch, der Fragen zu Ihrem Lebenslauf beantworten kann.
Installieren Sie zunächst die erforderlichen Pakete:
pip install llama-index openai pypdfLaden Sie dann Ihr Lebenslauf-PDF und erstellen Sie einen Index:
from llama_index import TreeIndex, SimpleDirectoryReader
resume = SimpleDirectoryReader("Pfad/zum/Lebenslauf").load_data()
index = TreeIndex.from_documents(resume)Nun können Sie den Index mit natürlich formulierten Sprachabfragen durchsuchen:
query_engine = index.as_query_engine()
response = query_engine.query("Wie lautet die Jobbezeichnung?")
print(response)Der Query-Engine durchsucht den Lebenslaufindex und gibt das relevanteste Fragment als Antwort aus, z. B. "Die Jobbezeichnung lautet Software Engineer".
Sie können auch Gespräche in einem Frage-Antwort-Format führen:
chat_engine = index.as_chat_engine()
response = chat_engine.chat("Was hat diese Person in ihrer letzten Position gemacht?")
print(response)
follow_up = chat_engine.chat("Welche Programmiersprachen hat sie verwendet?")
print(follow_up)Der Chat-Engine behält den Gesprächskontext bei, sodass Sie Folgefragen stellen können, ohne das Thema explizit wiederholen zu müssen.
Um den Index nicht jedes Mal neu aufzubauen, können Sie ihn auf der Festplatte speichern:
index.storage_context.persist()Und später wieder laden:
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)Über Chatbots hinaus: Anwendungsfälle für LlamaIndex
Chatbots sind nur eine der vielen Anwendungen, die Sie mit LlamaIndex erstellen können. Hier sind einige weitere Beispiele:
- Fragen und Antworten zu langen Dokumenten: Einlesen von Dokumenten wie Handbüchern, rechtlichen Verträgen oder Forschungsarbeiten und Fragen zu deren Inhalt stellen
- Personalisierte Empfehlungen: Erstellen Sie Indizes für Produktkataloge oder Inhaltssammlungen und geben Sie Empfehlungen basierend auf Benutzeranfragen
- Datengetriebene Agenten: Erstellen Sie KI-Assistenten, die auf Datenbanken, APIs und anderen Tools zugreifen und komplexe Aufgaben erledigen können
- Aufbau einer Wissensdatenbank: Automatisches Extrahieren strukturierter Daten wie Entitäten und Beziehungen aus unstrukturiertem Text zum Aufbau von Wissensgraphen
LlamaIndex bietet Ihnen eine flexible Toolset, um alle Arten von LLM-gesteuerten Apps zu erstellen. Sie können Datenbeladungen, Indizes, Abfrage-Engines, Agenten und mehr kombinieren, um benutzerdefinierte Pipelines für Ihren Anwendungsfall zu erstellen.
Erste Schritte mit LlamaIndex
Um mit LlamaIndex loszulegen, installieren Sie zuerst das Paket:
pip install llama-indexSie benötigen außerdem einen OpenAI API-Schlüssel, um auf die standardmäßig verwendeten Modelle zugreifen zu können. Setzen Sie dies als Umgebungsvariable:
import osos.environ["OPENAI_API_KEY"] = "dein_api_schluss"
Von dort aus kannst du anfangen, Daten zu verarbeiten und Indizes aufzubauen! Die LlamaIndex-Dokumentation bietet detaillierte Anleitungen und Beispiele für häufige Anwendungsfälle.
Wenn du tiefer eintauchst, kannst du den Llama Hub erkunden - eine Sammlung von Community-beigesteuerten Datenladern, Indizes, Abfrage-Engines und mehr. Du kannst diese Plugins sofort verwenden oder als Ausgangspunkt für deine eigenen benutzerdefinierten Komponenten nutzen.
### Was ist LangChain?
LangChain ist ein leistungsstarkes Framework zur Entwicklung von Anwendungen, die von Sprachmodellen betrieben werden. Es ermöglicht dir, deine eigenen Daten einfach mit LLMs zu verbinden und datenbewusste Sprachmodellanwendungen zu erstellen. LangChain bietet eine standardisierte Schnittstelle für Chains, viele Integrationen mit anderen Tools und end-to-end Chains für gängige Anwendungen.
Mit LangChain kannst du Daten aus verschiedenen Quellen wie Dokumenten, Datenbanken, APIs und Wissensdatenbanken laden. Diese privaten Daten werden während der Inferenzzeit LLMs zugänglich gemacht, so dass sie diesen Kontext nutzen können, um fundierte und relevante Antworten zu geben. Egal, ob du einen Chatbot über die Dokumentation deines Unternehmens, ein Datenanalysetool oder einen KI-Assistenten erstellen möchtest, der mit deinen Datenbanken und APIs interagiert, mit LangChain ist das möglich.
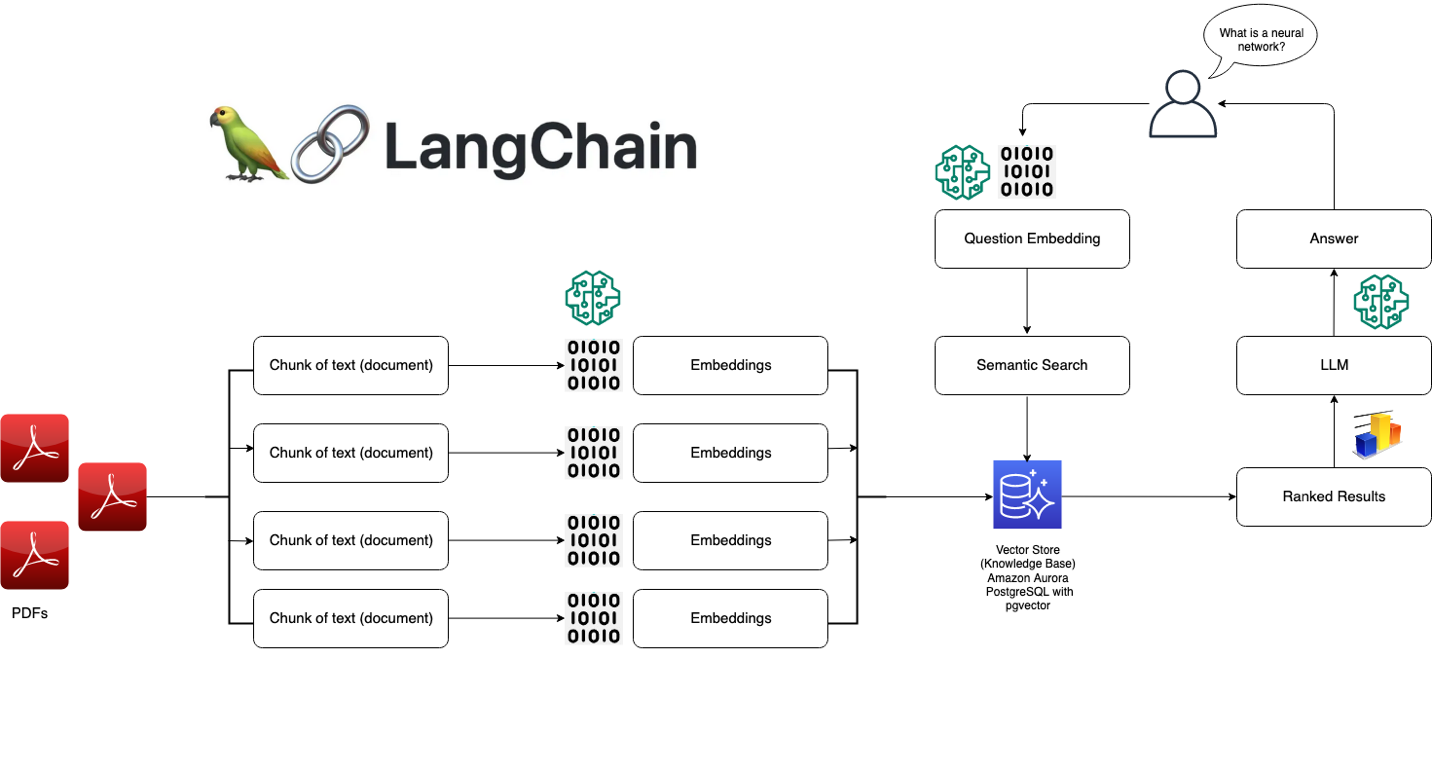
### Wie LangChain funktioniert
Im Kern ist LangChain um einige Schlüsselkonzepte herum aufgebaut:
1. Prompts: Prompts sind die Anweisungen, die du dem Sprachmodell gibst, um seine Ausgabe zu steuern. LangChain bietet eine standardisierte Schnittstelle zum Erstellen und Arbeiten mit Prompts.
2. Modelle: LangChain bietet eine standardisierte Schnittstelle zum Arbeiten mit verschiedenen LLMs und eine einfache Möglichkeit zum Wechseln zwischen ihnen. Es unterstützt Modelle wie OpenAI's GPT-3, Anthropic's Claude, Cohere's Modelle und mehr.
3. Indizes: Indizes beziehen sich auf die Art und Weise, wie Textdaten gespeichert und dem Sprachmodell zugänglich gemacht werden. LangChain bietet mehrere Indextechniken, die für LLMs optimiert sind, wie z.B. In-Memory-Vectorstores und Embeddings.
4. Chains: Chains sind Sequenzen von Aufrufen von LLMs und anderen Tools, wobei die Ausgabe eines Schritts als Eingabe für den nächsten Schritt dient. LangChain bietet eine standardisierte Schnittstelle für Chains und viele wiederverwendbare Komponenten.
5. Agents: Agents verwenden ein LLM, um zu bestimmen, welche Aktionen in welcher Reihenfolge durchgeführt werden sollen. LangChain bietet eine Auswahl an Agents, die Tools nutzen können, um Aufgaben zu erledigen.
Mit diesen Bausteinen kannst du verschiedene leistungsstarke Sprachmodellanwendungen erstellen. LangChain abstrahiert viele der Komplexitäten, so dass du dich auf die hochrangige Logik deiner Anwendung konzentrieren kannst.
### Aufbau eines Frage-Antwort-Systems mit LangChain
Um die Fähigkeiten von LangChain zu veranschaulichen, wollen wir den Aufbau eines einfachen Frage-Antwort-Systems über eine Sammlung von Dokumenten durchgehen.
Zuerst installiere die erforderlichen Pakete:
pip install langchain openai faiss-cpu
Lade nun deine Daten und erstelle einen Index:
```python
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
loader = TextLoader('pfad/zur/dokument.txt')
index = VectorstoreIndexCreator().from_loaders([loader])Jetzt kannst du den Index mit natürlicher Sprache abfragen:
abfrage = "Worum geht es in diesem Dokument?"
ergebnis = index.query(abfrage)
print(ergebnis)Die Abfrage durchsucht das Dokument und gibt das relevanteste Schnipsel als Antwort zurück.
Du kannst auch eine Unterhaltung mit den Daten führen, indem du eine ConversationalRetrievalChain verwendest:
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
modell = ChatOpenAI(temperature=0)
qa = ConversationalRetrievalChain.from_llm(modell,retriever=index.vectorstore.as_retriever())
chat_verlauf = []
while True:
abfrage = input("Mensch: ")
ergebnis = qa({"frage": abfrage, "chat_verlauf": chat_verlauf})
chat_verlauf.append((abfrage, ergebnis['antwort']))
print(f"Assistent: {ergebnis['antwort']}")Das ermöglicht eine Hin- und Her-Unterhaltung, bei der das Modell Zugriff auf den relevanten Kontext aus den Dokumenten hat.
Über Q&A hinaus: Anwendungsfälle von LangChain
Frage-Antwort ist nur eine von vielen Anwendungen, die du mit LangChain erstellen kannst. Weitere Beispiele sind:
- Chatbots: Erstelle Unterhaltungsagenten, die in einem freien Dialog privat Daten nutzen können
- Datenanalyse: Verbinde LLMs mit SQL-Datenbanken, Pandas Dataframes und Datenvisualisierungsbibliotheken für interaktive Datenexploration
- Agents: Entwicklung von KI-Agenten, die Webbrowser, APIs und Taschenrechner verwenden können, um offene Aufgaben zu erfüllen
- App-Generierung: Automatisches Generieren von kompletten Anwendungen aus natürlichsprachlichen Spezifikationen
LangChain bietet eine flexible Reihe von Komponenten, die auf unzählige Arten kombiniert werden können, um leistungsstarke Sprachmodellanwendungen zu erstellen. Du kannst die integrierten Chains und Agents verwenden oder deine eigenen benutzerdefinierten Pipelines erstellen.
Erste Schritte mit LangChain
Um mit LangChain loszulegen, installiere zuerst das Paket:
pip install langchainDu musst auch die erforderlichen API-Schlüssel für die Modelle und Tools einrichten, die du verwenden möchtest. Zum Beispiel, um OpenAI-Modelle zu verwenden:
import os
os.environ["OPENAI_API_KEY"] = "dein_api_schluss"Von dort aus kannst du anfangen, Daten zu laden, Chains zu erstellen und deine Anwendung aufzubauen! Die LangChain-Dokumentation bietet detaillierte Anleitungen und Beispiele für verschiedene Anwendungsfälle.
Wenn du tiefer eintauchst, kannst du das wachsende Ökosystem von LangChain-Integrationen und -Erweiterungen erkunden. Die Community hat Konnektoren zu unzähligen Datenquellen, Tools und Frameworks entwickelt, um die Integration von LLMs in jeden Workflow zu erleichtern.
Beste Anwendungsfälle von LlamaIndex vs LangChain
LlamaIndex:
- Aufbau von Suchmaschinen und Information Retrieval Systemen
- Erstellen von Knowledge Bases und FAQ-Bots
- Analyse und Zusammenfassung großer Dokumentsammlungen
- Ermöglichen von konversationsbasierten Suchanfragen und Frage-Antwort-Systemen
LangChain:
- Entwicklung von Chatbots und konversationellen Agenten
- Aufbau von maßgeschneiderten NLP-Pipelines und Workflows
- Integration von LLMs mit externen Datenquellen und APIs
- Experimentieren mit verschiedenen Anregungen, Gedächtnis und Agentenkonfigurationen
LlamaIndex vs LangChain: Die richtige Framework-Auswahl treffen
Bei der Entscheidung zwischen LlamaIndex und LangChain sollten Sie die folgenden Faktoren berücksichtigen:
-
Projektanforderungen: Wenn Ihre Anwendung sich hauptsächlich auf Suche und Retrieval konzentriert, könnte LlamaIndex besser geeignet sein. Für vielfältigere NLP-Aufgaben und benutzerdefinierte Workflows bietet LangChain jedoch eine größere Flexibilität.
-
Benutzerfreundlichkeit: LlamaIndex bietet eine straffere und anfängerfreundlichere Benutzeroberfläche, während LangChain ein tieferes Verständnis von NLP-Konzepten und -Komponenten erfordert.
-
Anpassungsmöglichkeiten: Die modulare Architektur von LangChain ermöglicht umfangreiche Anpassungen und Feinabstimmungen, während LlamaIndex einen eher voreingenommenen Ansatz bietet, der auf Suche und Recovery optimiert ist.
-
Ökosystem und Community: Beide Frameworks haben aktive Communities und wachsende Ökosysteme. Erkunden Sie ihre Dokumentation, Beispiele und Community-Ressourcen, um das Maß an Support und verfügbaren Ressourcen abzuschätzen.
Fazit
LlamaIndex und LangChain sind leistungsstarke Frameworks zur Erstellung von LLM-gesteuerten Anwendungen, die jeweils eigene Stärken und Schwerpunktbereiche haben. LlamaIndex glänzt in Such- und Retrievalaufgaben und bietet eine optimierte Datenindizierung und Abfragemöglichkeiten. Andererseits verfolgt LangChain einen modularen Ansatz und bietet ein flexibles Set an Werkzeugen und Komponenten zur Erstellung vielfältiger NLP-Anwendungen.
Bei der Auswahl zwischen beiden sollten Sie Ihre Projektanforderungen, Benutzerfreundlichkeit, Anpassungsbedarf und den gebotenen Support ihrer jeweiligen Communities berücksichtigen. Unabhängig von Ihrer Wahl ermöglichen sowohl LlamaIndex als auch LangChain Entwicklern, das Potenzial großer Sprachmodelle zu nutzen und innovative NLP-Anwendungen zu erstellen.
Auf Ihrer Reise zur Entwicklung von LLM-Anwendungen sollten Sie nicht zögern, beide Frameworks zu erkunden, mit ihren Funktionen zu experimentieren und ihre Stärken zu nutzen, um leistungsstarke und ansprechende natürlichsprachliche Erlebnisse zu schaffen.