Wie Groq KI LLM-Abfragen um den Faktor x10 schneller macht

Groq, ein Unternehmen für generative KI-Lösungen, definiert mit seinem bahnbrechenden Inferenz-Engine für Language Processing Unit (LPU) die Landschaft des Inferenzmodells großer Sprachmodelle (LLM) neu. Dieser speziell entwickelte Beschleuniger ist darauf ausgelegt, die Begrenzungen herkömmlicher CPU- und GPU-Architekturen zu überwinden und eine beispiellose Geschwindigkeit und Effizienz bei der LLM-Verarbeitung zu bieten.
Möchten Sie die neuesten Nachrichten zu LLM sehen? Werfen Sie einen Blick auf die neueste LLM Rangliste!

Die LPU-Architektur: Ein genauerer Blick
Im Kern von Groqs LPU-Architektur liegt ein Single-Core-Design, das die sequentielle Leistung priorisiert. Dieser Ansatz ermöglicht es der LPU, eine außergewöhnliche Rechendichte zu erreichen, mit einer Spitzenleistung von 1 PetaFLOP/s in einem einzigen Chip. Die einzigartige Architektur der LPU beseitigt auch Engpässe im externen Speicher, indem sie 220 MB On-Chip-SRAM enthält und eine beeindruckende Speicherbandbreite von 1,5 TB/s bietet.
Die synchrone Netzwerkfähigkeit der LPU ermöglicht eine nahtlose Skalierbarkeit bei Großbereitstellungen. Mit einer bidirektionalen Bandbreite von 1,6 TB/s pro LPU kann Groqs Technologie die massiven Datenübertragungen effizient bewältigen, die für die LLM-Inferenz erforderlich sind. Darüber hinaus unterstützt die LPU eine Vielzahl von Genauigkeitsstufen, von FP32 bis INT4, was auch bei niedrigeren Präzisionseinstellungen eine hohe Genauigkeit ermöglicht.
Benchmarking der Leistung von Groq
Groqs LPU-Inferenz-Engine hat in verschiedenen Benchmarks kontinuierlich Branchengrößen übertroffen. In internen Tests mit dem Modell Llama-2 70B von Meta AI erreichte Groq beeindruckende 300 Tokens pro Sekunde pro Benutzer. Dies stellt einen signifikanten Fortschritt in der Geschwindigkeit der LLM-Inferenz dar und übertrifft die Leistung herkömmlicher auf GPU basierender Systeme.
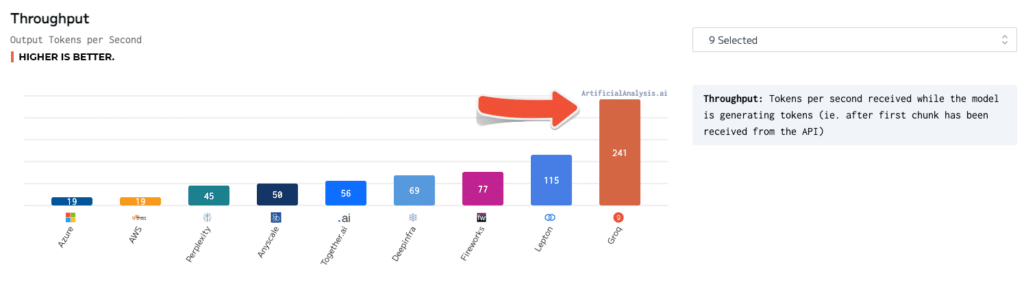
Unabhängige Benchmarks haben Groqs Überlegenheit weiter bestätigt. In Tests von ArtificialAnalysis.ai erreichte die Llama 2 Chat (70B) API von Groq eine Durchsatzrate von 241 Tokens pro Sekunde, mehr als doppelt so schnell wie andere Hosting-Anbieter. Groq zeichnete sich auch in anderen wichtigen Leistungskennzahlen aus, wie z.B. Latenz vs. Durchsatz, Gesamtreaktionszeit und Durchsatzvarianz.
Um diese Zahlen in Perspektive zu setzen, betrachten Sie einen Fall, in dem ein Benutzer mit einem KI-gesteuerten Chatbot interagiert. Mit Groqs LPU-Inferenz-Engine kann der Chatbot Antworten mit einer Rate von 300 Tokens pro Sekunde generieren und somit nahezu sofortige Konversationen ermöglichen. Im Vergleich dazu könnte ein auf GPU basierendes System nur 50-100 Tokens pro Sekunde erreichen, was zu bemerkbaren Verzögerungen und einem weniger ansprechenden Benutzererlebnis führen würde.
Groq vs. Andere KI-Technologien

Im Vergleich zu NVIDIAs GPUs zeigt Groqs LPU einen klaren Vorteil in der INT8-Leistung, was für eine schnelle Inferenz großer Sprachmodelle entscheidend ist. In einem Benchmark-Vergleich der LPU mit NVIDIAs A100 GPU erreichte die LPU eine 3,5-fache Beschleunigung beim Llama-2 70B-Modell und verarbeitete 300 Tokens pro Sekunde im Vergleich zu den 85 Tokens pro Sekunde des A100.
Groqs Technologie sticht auch bei anderen KI-Modellen wie ChatGPT und Googles Gemini hervor. Obwohl spezifische Leistungszahlen für diese Modelle nicht öffentlich verfügbar sind, lassen die gezeigte Geschwindigkeit und Effizienz von Groq darauf schließen, dass es das Potential hat, sie in realen Anwendungen zu übertreffen.
Die Verwendung von Groq KI
Groq bietet eine umfassende Palette von Tools und Dienstleistungen, um die Bereitstellung und Nutzung seiner LPU-Technologie zu erleichtern. Die GroqWare-Suite, zu der auch der Groq Compiler gehört, bietet eine einfache Möglichkeit, Modelle schnell in Betrieb zu nehmen. Hier ist ein Beispiel, wie man ein Modell mit dem Groq Compiler kompiliert und ausführt:
# Kompiliere das Modell
groq compile model.onnx -o model.groq
# Führe das Modell auf der LPU aus
groq run model.groq -i input.bin -o output.binFür diejenigen, die mehr Anpassungsmöglichkeiten suchen, ermöglicht Groq auch das Handcodieren für die Groq-Architektur, was die Entwicklung maßgeschneiderter Anwendungen und maximale Leistungsoptimierung ermöglicht. Hier ein Beispiel für handkodierten Groq-Assembler für eine einfache Matrixmultiplikation:
; Matrixmultiplikation auf der Groq LPU
; Geht davon aus, dass Matrizen A und B im Speicher geladen sind
; Lade Matrixdimensionen
ld r0, [n]
ld r1, [m]
ld r2, [k]
; Initialisiere Ergebnismatrix C
mov r3, 0
; Äußere Schleife über Zeilen von A
mov r4, 0
loop_i:
; Innere Schleife über Spalten von B
mov r5, 0
loop_j:
; Akkumuliere das Skalarprodukt
mov r6, 0
mov r7, 0
loop_k:
ld r8, [A + r4 * m + r7]
ld r9, [B + r7 * k + r5]
mul r10, r8, r9
add r6, r6, r10
add r7, r7, 1
cmp r7, r2
jlt loop_k
; Speichere das Ergebnis in C
st [C + r4 * k + r5], r6
add r5, r5, 1
cmp r5, r2
jlt loop_j
add r4, r4, 1
cmp r4, r0
jlt loop_iEntwickler und Forscher können auch Groqs leistungsstarke Technologie über die Groq API nutzen, die Zugriff auf Echtzeit-Inferenzfunktionen bietet. Hier ist ein Beispiel, wie man die Groq API verwendet, um Text mit dem Modell Llama-2 70B zu generieren:
import groq
# Initialisiere den Groq-Client
client = groq.Client(api_key="Ihr_API-Schlüssel")
# Richte das Modell und die Parameter ein
model = "llama-2-70b"
prompt = "Es war einmal in einem weit, weit entfernten Land..."
max_tokens = 100
# Generiere Text
response = client.generate(model=model, prompt=prompt, max_tokens=max_tokens)
# Gib den generierten Text aus
print(response.text)Mögliche Anwendungen und Auswirkungen
Die nahezu sofortigen Reaktionszeiten, die durch Groqs LPU-Inferenzengine ermöglicht werden, eröffnen neue Möglichkeiten in verschiedenen Branchen. Im Finanzbereich kann Groqs Technologie für Echtzeit-Betrugserkennung und Risikobewertung genutzt werden. Durch die Verarbeitung großer Mengen an Transaktionsdaten und die Identifizierung von Anomalien in Millisekunden können Finanzinstitute betrügerische Aktivitäten verhindern und die Vermögenswerte ihrer Kunden schützen.
Im Gesundheitswesen kann Groqs LPU die Patientenversorgung revolutionieren, indem es eine Echtzeitanalyse von medizinischen Daten ermöglicht. Von der Verarbeitung medizinischer Bilder bis zur Analyse elektronischer Patientenakten kann Groqs Technologie dazu beitragen, dass Gesundheitsfachkräfte schnelle und präzise Diagnosen stellen und letztendlich die Patientenergebnisse verbessern können.
Auch autonome Fahrzeuge können von Groqs Hochgeschwindigkeits-Inferenzfähigkeiten erheblich profitieren. Durch die Verarbeitung von Sensordaten und die Treffen von Sekundenbruchteilentscheidungen können von Groq betriebene KI-Systeme die Sicherheit und Zuverlässigkeit von selbstfahrenden Autos verbessern und so den Weg für eine Zukunft des intelligenten Transports ebnen.
Fazit
Groqs LPU-Inferenzengine repräsentiert einen bedeutenden Fortschritt im Bereich der AI-Beschleunigung. Mit ihrer innovativen Architektur, beeindruckenden Benchmarks und umfassenden Suite von Werkzeugen und Dienstleistungen ermöglicht Groq Entwicklern und Organisationen, die Grenzen dessen, was mit großen Sprachmodellen möglich ist, zu erweitern.
Mit der wachsenden Nachfrage nach Echtzeit-KI-Inferenz ist Groq gut aufgestellt, um die Führung bei der Ermöglichung der nächsten Generation KI-gesteuerter Lösungen zu übernehmen. Vom Chatbot und virtuellen Assistenten bis hin zu autonomen Systemen und darüber hinaus sind die potenziellen Anwendungen von Groqs Technologie umfangreich und transformative.
Mit ihrem Engagement für die Demokratisierung des Zugangs zur KI und die Förderung von Innovationen revolutioniert Groq nicht nur die technische Landschaft, sondern gestaltet auch die Zukunft unserer Interaktion mit und den Nutzen von künstlicher Intelligenz. Während wir an der Schwelle zu einer AI-getriebenen Ära stehen, ist Groqs bahnbrechende Technologie bereit, ein Katalysator für beispiellose Fortschritte und Entdeckungen in den kommenden Jahren zu sein.
Möchten Sie die neuesten LLM-Nachrichten erfahren? Schauen Sie sich die aktuelle LLM-Rangliste an!