Wie man Mistral-Modelle lokal ausführt - Ein umfassender Leitfaden

In der sich schnell entwickelnden Welt der künstlichen Intelligenz hat Mistral AI sich als Innovationsführer erwiesen, der neue Gebiete im Bereich der Large Language Models (LLMs) erschließt. Mit der Einführung seiner bahnbrechenden Modelle treibt Mistral AI nicht nur die Grenzen des maschinellen Lernens voran, sondern demokratisiert auch den Zugang zu modernster Technologie. Dieser Leitfaden zielt darauf ab, die Feinheiten des Angebots von Mistral AI zu erläutern und eine umfassende Roadmap zur Nutzung ihrer Fähigkeiten vor Ort zu liefern.
Was sind diese Mistral AI Modelle?
Mistral AI hat eine Reihe von Sprachmodellen enthüllt, die nicht nur Iterationen, sondern große Sprünge in der Berechnungslinguistik darstellen. Im Herzen dieser Reihe stehen Mistral 7B und Mistral 8x7B, die jeweils auf verschiedene Anforderungen und Berechnungsmöglichkeiten zugeschnitten sind.
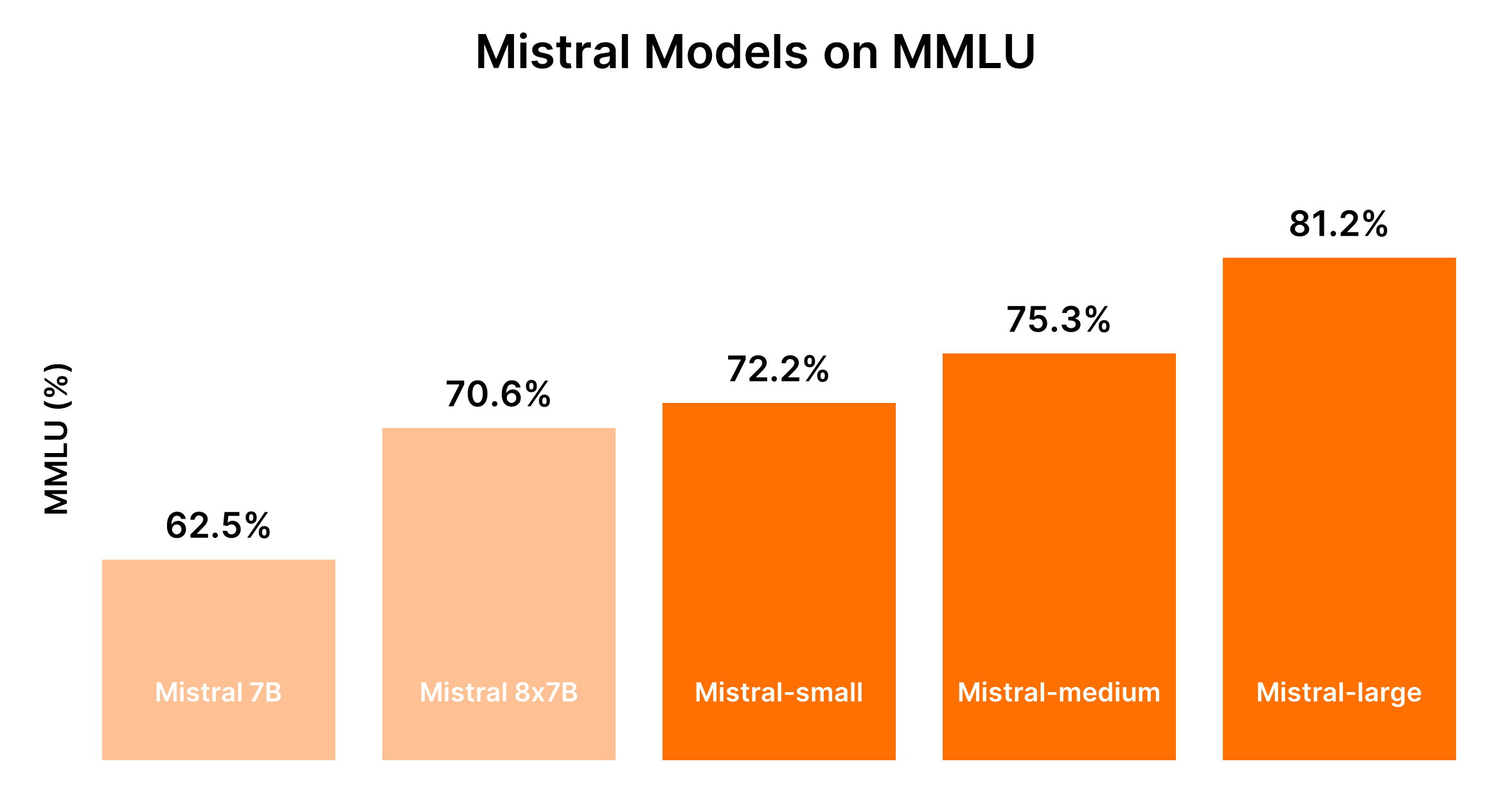
Vergleich der Mistral AI Modelle (Mistral 7B vs Mistral 8x7b vs Mistral Small vs Mistral Medium vs Mistral Large)
Verstanden. Basierend auf den gegebenen Eingaben und mit dem Ziel, Tabellen im markdown-Format für einen direkten Vergleich zu erstellen, strukturieren wir die Vergleichsanalyse der Mistral AI Modelle.
Vergleichsanalyse der Mistral AI Modelle
Mistral AI bietet eine Reihe von Modellen, die jeweils auf verschiedene Anwendungsfälle zugeschnitten sind, von einfachen Stapelaufgaben bis hin zu komplexen Denkfähigkeiten. Nachfolgend finden Sie vergleichende Analysen und Leistungsergebnisse im markdown-Format für ein klares Verständnis.
Modellübersicht und Anwendungsfälle
| Modell-ID | Alias | Anwendungsfälle |
|---|---|---|
| open-mistral-7b | mistral-tiny-2312 | Einfache Stapelaufgaben wie Klassifizierung, Kundensupport oder Textgenerierung |
| open-mistral-8x7b | mistral-small-2312 | Ähnlich wie open-mistral-7b, geeignet für einfache Stapelaufgaben |
| mistral-small-latest | mistral-small-2402 | Etwas fortgeschrittenere Aufgaben, die minimalen Verstand erfordern |
| mistral-medium-latest | mistral-medium-2312 | Aufgaben mittleren Schwierigkeitsgrades wie Datenextraktion, Zusammenfassung von Dokumenten, Verfassen von E-Mails |
| mistral-large-latest | mistral-large-2402 | Komplexe Aufgaben, die große Denkfähigkeiten erfordern, wie die Generierung synthetischer Texte, Codegenerierung |
Leistung und Kostenabwägungen
Die Leistung der Mistral-Modelle steht im Allgemeinen in proportionaler Beziehung zu ihrer Größe, wobei größere Modelle verbesserte Fähigkeiten bieten, jedoch zu höheren Kosten. Die folgende Tabelle fasst die Leistungsrangliste basierend auf dem MMLU-Benchmark und den allgemeinen Kostenüberlegungen zusammen.
| Modell | Leistungsrang | Kostenüberlegungen |
|---|---|---|
| Mistral 7B (tiny-2312) | 5. | Am kosteneffektivsten für einfache Aufgaben |
| Mistral 8x7B (small-2312) | 4. | Kosten effektiv für einfache Aufgaben in Stapelverarbeitung |
| Mistral Small (small-2402) | 3. | Moderater Preis, geeignet für Aufgaben mit minimalen Verstandsanforderungen |
| Mistral Medium (medium-2312) | 2. | Höherer Preis, ausgewogene Leistung für Aufgaben mittleren Schwierigkeitsgrades |
| Mistral Large (large-2402) | 1. | Höchster Preis, überragende Leistung für komplexe Aufgaben |
Aufgrund der dynamischen Natur der Leistung von LLMs und der damit verbundenen Kosten wird empfohlen, aktuelle Benchmarks und Preise für einen genauen Vergleich heranzuziehen. Plattformen wie Hugging Face's Chatbot Arena Leaderboard (opens in a new tab) und Artificial Analysis (opens in a new tab) können für aktuelle Benchmarks und Leistungserkenntnisse wertvolle Informationen liefern.
Entscheidungshilfe: Welches Mistral AI Modell sollten Sie wählen?
Die Auswahl des richtigen Modells hängt von der Balance der Leistungsanforderungen gegenüber den Kostenbeschränkungen ab, wobei die Komplexität der Aufgaben berücksichtigt wird, die Ihre Anwendung bearbeiten soll.
- Für einfache Aufgaben: Beginnen Sie mit Mistral Small oder Mistral 7B für eine kosteneffiziente Lösung.
- Für Aufgaben mittleren bis hohen Schwierigkeitsgrades: Prüfen Sie, ob die verbesserte Leistung von Mistral Medium oder Mistral Large den zusätzlichen Aufwand basierend auf Ihren spezifischen Anforderungen rechtfertigt.
Dieser strukturierte Vergleich soll fundierte Entscheidungen erleichtern, wenn Sie aus dem Angebot der Mistral AI Modelle auswählen, und sicherstellen, dass das gewählte Modell sowohl den funktionalen Anforderungen als auch dem Budgetrahmen Ihres Projekts entspricht.

Teil 1: So führen Sie Mistral mit Ollama lokal aus (der einfache Weg)
Das Ausführen von Mistral AI-Modellen lokal mit Ollama bietet Ihnen eine zugängliche Möglichkeit, die Leistung dieser fortschrittlichen LLMs direkt auf Ihrem Computer zu nutzen. Dieser Ansatz eignet sich ideal für Entwickler, Forscher und Enthusiasten, die ohne Cloud-Services mit KI-gesteuerter Textanalyse, Generierung und mehr experimentieren möchten. Hier ist ein knapper Leitfaden, um Ihnen den Einstieg zu erleichtern:
Schritt 1: Laden Sie Ollama herunter
- Besuchen Sie die Download-Seite von Ollama und wählen Sie die passende Version für Ihr Betriebssystem aus. Für macOS-Benutzer wird eine
.dmg-Datei heruntergeladen. - Installieren Sie Ollama, indem Sie die heruntergeladene Datei in Ihr
/Applications-Verzeichnis ziehen.
Schritt 2: Erforschen Sie Ollama-Befehle
Öffnen Sie Ihr Terminal und geben Sie ollama ein, um die Liste der verfügbaren Befehle anzuzeigen. Sie sehen Optionen wie serve, create, show, run, pull und mehr.
Schritt 3: Installieren Sie Mistral AI
Um ein Mistral AI-Modell zu installieren, müssen Sie zunächst das gewünschte Modell finden. Wenn Sie sich für die Mistral:instruct-Version interessieren, können Sie es direkt installieren oder es ziehen, wenn es noch nicht auf Ihrem Rechner ist.
- Um direkt auszuführen (und gegebenenfalls herunterzuladen):
ollama run mistral:instruct - Um das Modell vorab herunterzuladen:
ollama pull mistral:instruct
Schritt 4: Mit Mistral AI interagieren
Sobald das Modell installiert ist, können Sie mit ihm im interaktiven Modus interagieren oder Eingaben direkt übergeben.
-
Für den interaktiven Modus:
ollama run mistral --verboseBefolgen Sie dann die Aufforderungen, um Ihre Anfragen einzugeben.
-
Für den nicht-interaktiven Modus (direkte Eingabe): Nehmen wir an, Sie haben einen Artikel, den Sie zusammenfassen möchten, der in
bbc.txtgespeichert ist. Sie können den Inhalt des Artikels direkt an Mistral übergeben, um eine Zusammenfassung zu erhalten:ollama run mistral --verbose "Bitte fassen Sie diesen Artikel zusammen: $(cat bbc.txt)"Ersetzen Sie
"Bitte fassen Sie diesen Artikel zusammen: $(cat bbc.txt)"durch eine beliebige für Ihre Aufgabe relevante Eingabeaufforderung.
Beispiel für Ausgabenanalyse
Ihr Terminal zeigt die Ausgabe des Modells an, einschließlich der Zusammenfassung oder Antwort auf Ihre Eingabeaufforderung. Es ist faszinierend zu sehen, wie Mistral komplexe Anfragen verarbeitet und versteht und bei Ungenauigkeiten sogar Korrekturen anbietet.
Ausführen von Mistral AI über die HTTP-API
Ollama unterstützt auch eine HTTP-API, die eine programmatische Interaktion mit den Modellen ermöglicht.
- Beispiel für eine
curl-Anfrage:curl -X POST http://localhost:11434/api/generate -d '{ "model": "mistral", "prompt": "Was ist die Bewertung dieses Satzes: Die Situation rund um den Video-Assistent-Schiedsrichter ist kritisch." }'
Diese Methode gibt JSON-Antworten aus, die programmatisch analysiert werden können und eine flexible Möglichkeit bieten, die Fähigkeiten von Mistral AI in Anwendungen zu integrieren.
Die Verwendung von Mistral AI mit Ollama auf einem lokalen Rechner eröffnet umfangreiche Möglichkeiten zur Nutzung von KI in persönlichen Projekten, Entwicklung und Forschung. Die einfache Installation und Verwendung in Kombination mit der Leistungsfähigkeit der Mistral Language Modelle machen dies zu einer überzeugenden Option für jeden, der die Grenzen der KI-Technologie erkunden möchte.
Teil 2. Wie man Mistral 7B lokal unter Windows ausführt
Mistral 7B kann über verschiedene Plattformen wie HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart und Baseten genutzt werden. Kaggle's "Models" Funktion bietet auch einen vereinfachten Ansatz, mit dem Sie innerhalb von Minuten mit der Inferenz oder Feinabstimmung beginnen können, ohne das Modell oder den Datensatz herunterladen zu müssen.
Voraussetzungen für den Zugriff auf Mistral 7B
Bevor Sie loslegen, stellen Sie sicher, dass Ihre Umgebung auf dem neuesten Stand ist, um gängige Fehler wie KeyError: 'mistral' zu vermeiden:
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytesUmsetzung der 4-Bit-Quantisierung
Um das Laden des Modells zu beschleunigen und den Speicherbedarf zu reduzieren, wird eine 4-Bit-Quantisierung verwendet:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Laden von Mistral 7B in Kaggle Notebooks
Kaggle Notebooks erleichtern das Hinzufügen von Mistral 7B durch eine einfache Benutzeroberfläche. Nach Auswahl der entsprechenden Modellvariation und -version können Sie das Modell und den Tokenizer problemlos laden:
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)Die Verwendung der Funktion pipeline vereinfacht den Prozess zur Generierung von Antworten basierend auf der gegebenen Eingabeaufforderung.
Beispiel für Inferenz
Durch Festlegen einer Eingabeaufforderung und Aufrufen der Pipeline generiert Mistral 7B zusammenhängende und kontextuell relevante Antworten, die sein Verständnis komplexer Konzepte wie Regularisierung im maschinellen Lernen veranschaulichen:
prompt = "Als Data Scientist können Sie das Konzept der Regularisierung im maschinellen Lernen erklären?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])Feinabstimmung von Mistral 7B
Der Feinabstimmungsprozess umfasst das Aktualisieren von Bibliotheken, das Einrichten von Modulen und die Anpassung des Modells an Ihren Datensatz. Mit Kaggle Notebooks werden API-Schlüssel für Dienste wie Hugging Face und Weights & Biases sicher gespeichert und abgerufen. Dieser Abschnitt erläutert die wesentlichen Schritte und Konfigurationen für eine effektive Feinabstimmung, um das Potenzial des Modells optimal auf Ihren spezifischen Datensatz zu nutzen.
- Aktualisieren und Installieren der erforderlichen Bibliotheken: Stellt Kompatibilität und Zugriff auf die neuesten Funktionen für die Feinabstimmung sicher.
- Module laden und API-Zugriff einrichten: Ermöglicht die Interaktion mit externen Diensten und Modell-Repositories.
- Modell konfigurieren und trainieren: Passt das Modell an die Eigenheiten Ihres Datensatzes an und nutzt die Leistungsfähigkeit von PEFT (Parameter-efficient Fine-tuning) für effizientes Training.
- Bewerten und speichern Sie Ihr Modell: Bewertet die Leistung des Modells und speichert die Feinabstimmung.
Der detaillierte Leitfaden soll Ihnen die Werkzeuge und Kenntnisse vermitteln, um die Fähigkeiten des Mistral 7B-Modells effektiv zu nutzen. Vom Zugriff auf das Modell bis zur Feinabstimmung auf einen bestimmten Datensatz ist jeder Schritt darauf ausgelegt, die Fähigkeiten der natürlichen Sprachverarbeitung Ihres Projekts zu verbessern.
Teil 3. Wie man Mixtral 8x7b lokal mit LlamaIndex und Ollama ausführt

Der europäische KI-Gigant Mistral AI hat kürzlich sein Modell "Mixtral 8x7b" vorgestellt, das ein "Mixture of Experts" darstellt. Dieses Modell, das aus acht Experten besteht, von denen jeder mit 7 Milliarden Parametern trainiert wurde, hat aufgrund seiner Leistung bei verschiedenen Benchmarks großes Interesse geweckt und sogar die Leistung von GPT-3.5 und Llama2 70b übertroffen.
Schritt 1: Installation von Ollama
Ollama ist ein Open-Source-Tool, das für MacOS, Linux und Windows (über Windows Subsystem for Linux) verfügbar ist und den Prozess des lokalen Ausführens von Modellen vereinfacht. Mit Ollama können Sie Mixtral mit einem einzigen Befehl starten:
ollama run mixtralDieser Befehl lädt das Modell herunter (was einige Zeit dauern kann) und erfordert eine erhebliche Menge an RAM (48 GB), um reibungslos ausgeführt zu werden. Für Systeme mit niedrigeren Spezifikationen ist Mistral 7b eine alternative Option.
Schritt 2: Abhängigkeiten installieren
Um Mixtral mit LlamaIndex zu integrieren, benötigen Sie mehrere Abhängigkeiten. Installieren Sie sie mit pip:
pip install llama-index qdrant_client torch transformersSchritt 3: Smoke-Test
Überprüfen Sie die Einrichtung mit einem "Smoke-Test" unter Verwendung von Ollama und LlamaIndex:
from llama_index.llms import Ollama
llm = Ollama(model="mixtral")
response = llm.complete("Wer ist Laurie Voss?")
print(response)Schritt 4: Daten laden und indexieren
Daten vorbereiten:
Verwenden Sie für dieses Beispiel einen beliebigen Datensatz; hier verwenden wir eine Sammlung von Tweets. Die Daten werden in Qdrant, einer Open-Source-Vektor-Datenbank, gespeichert. Die folgenden Code-Snippets zeigen den Prozess des Ladens und Indexierens der Daten mit Qdrant und LlamaIndex:
from pathlib import Path
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext, download_loader
from llama_index.llms import Ollama
from llama_index.storage.storage_context import StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Initialisieren Sie Qdrant und laden Sie Tweets
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
## Service-Kontext mit Mixtral und lokaler Einbettung einrichten
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## Indexieren und Abfragen von Daten
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("Was denkt der Autor über Star Trek? Geben Sie Details.")
print(response)Index überprüfen:
Der letzte Schritt besteht darin, den vorbereiteten Index zur Beantwortung von Abfragen zu verwenden. Dieser Vorgang erfordert kein erneutes Laden der Daten, da diese bereits in Qdrant indiziert sind:
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import Ollama
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Laden des Vektor-Speichers und von Mixtral
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## Index laden und Abfragen
index = VectorStoreIndex.from_vector_store(vector_store=vector_store, service_context=service_context)
query_engine = index.as_query_engine(similarity_top_k=20)
response = query_engine.query("Mag der Autor SQL? Geben Sie Details.")
print(response)Teil 4. So führen Sie Mistral 8x7B lokal mit llama.cpp aus
Das Ausführen von Mistral AI-Modellen lokal ist dank Tools wie llama.cpp und dem Plugin llm-llama-cpp einfacher geworden. Mit der Veröffentlichung des Mixtral 8x7B-Modells, einem hochwertigen dünn besetzten Mixture-of-Experts (SMoE)-Modell, wurde ein bedeutender Fortschritt in der offenen KI-Landschaft erzielt. Hier ist eine kurze Anleitung, wie Sie Mixtral 8x7B lokal mithilfe von llama.cpp und den dazugehörigen Tools ausführen können.
Installation und Ausführung von Mixtral 8x7B lokal
-
Installieren Sie das LLM-Tool: Stellen Sie zuerst sicher, dass Sie LLM auf Ihrem Rechner installiert haben. LLM fungiert als Brücke, um verschiedene KI-Modelle lokal auszuführen.
pipx install llm -
Installieren Sie das
llm-llama-cpp-Plugin: Dieses Plugin ist erforderlich, um Mixtral und andere vonllama.cppunterstützte Modelle auszuführen.llm install llm-llama-cpp -
Richten Sie
llama-cpp-pythonein: Für Apple Silicon Macs kann die Einrichtung die Aktivierung der Unterstützung für Metal umfassen:CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 llm install llama-cpp-pythonDetaillierte Anweisungen können je nach Plattform variieren, daher finden Sie in der
llm-llama-cpp-README-Anleitung. -
Laden Sie das Mixtral-Modell herunter: Sie benötigen die GGUF-Datei für Mixtral 8x7B. Wählen Sie eine geeignete Dateigröße für Ihre Bedürfnisse, zum Beispiel die 36GB-Variante für die Instruct-Version des Modells:
curl -LO 'https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf?download=true' -
Führen Sie das Modell aus: Mit dem heruntergeladenen Modell können Sie Mixtral 8x7B mit dem
llm-Tool ausführen:llm -m gguf -o path mixtral-8x7b-instruct-v0.1.Q6_K.gguf '[INST] Schreiben Sie eine Python-Funktion, die eine Datei von einer URL herunterlädt[/INST]'Dieser Befehl gibt an, das GGUF-Modell mit der Option
-m ggufzu verwenden und gibt den Pfad zur heruntergeladenen GGUF-Datei mit-o pathan.
Weitere Überlegungen
-
Interaktiver Modus: Wenn Sie mit dem Modell in einer dialogähnlichen Weise interagieren möchten, können Sie
llmim interaktiven Modus ausführen. In diesem Modus ist ein Hin und Her mit dem KI-Modell möglich. -
Prompt-Konstruktion: Das Präfix
[INST]im obigen Befehlsbeispiel deutet auf die instruktionsbasierte Natur der Eingabe hin, die für Instruction-Versionen der Modelle geeignet ist. Passen Sie Ihre Anfragen an das erwartete Eingabeformat des Modells an, um optimale Ergebnisse zu erzielen.
Teil 5. Mistral 7B lokal auf einem iPhone ausführen

Die Mistral 7B-Model auf einem iPhone auszuführen erfordert einige technische Schritte, da iOS-Geräte in der Regel mehr Einschränkungen haben als Desktop-Umgebungen. Hier ist eine vereinfachte Schritt-für-Schritt-Anleitung:
-
Voraussetzungen:
- Stellen Sie sicher, dass Ihr iPhone die neueste iOS-Version verwendet, um Kompatibilitätsprobleme zu vermeiden.
- Installieren Sie eine iOS-App-Entwicklungsumgebung wie Xcode auf Ihrem Mac, um die benutzerdefinierte App zu erstellen und auszuführen, die Mistral 7B verwenden wird.
-
Ausführungsoption auswählen: Für die iPhone-Bereitstellung ist
llm-llama-cppmöglicherweise am besten geeignet, da es mit C++-Umgebungen kompatibel ist und in iOS-Projekte integriert werden kann. -
Entwicklungsumgebung einrichten:
- Laden Sie die GGUF-Datei für
llm-llama-cppaus dem offiziellen Repository herunter. - Öffnen Sie Xcode und erstellen Sie ein neues iOS-Projekt.
- Integrieren Sie die
llm-llama-cpp-Bibliothek in Ihr Projekt. Dies erfordert möglicherweise zusätzliche Abhängigkeiten, also werfen Sie einen Blick in die Dokumentation.
- Laden Sie die GGUF-Datei für
-
Programmierung:
- Schreiben Sie Swift- oder Objective-C-Code, um mit der C++-Bibliothek zu interagieren. Hierbei könnte es erforderlich sein, eine Bridging-Header-Datei zu erstellen, um C++-Code in Swift-Projekten verwenden zu können.
- Initialisieren Sie das Modell innerhalb Ihrer App und nehmen Sie etwaige erforderliche Konfigurationen vor, z. B. den Modellpfad und die Parameter.
-
Testen und Bereitstellen:
- Testen Sie die App auf Ihrem iPhone, um sicherzustellen, dass das Modell reibungslos läuft und wie erwartet funktioniert.
- Veröffentlichen Sie die App über Xcode, entweder für den persönlichen Gebrauch oder, sofern sie den Richtlinien von Apple entspricht, reichen Sie sie im App Store ein.
Teil 6. Mistral AI lokal mit API ausführen

Um Mistral AI lokal mit seiner API auszuführen, befolgen Sie diese Schritte und stellen Sie sicher, dass Ihre Umgebung HTTP-Anfragen unterstützt. Sie können dazu beispielsweise Postman zum Testen oder Programmiersprachen mit HTTP-Anfragefunktionen (z. B. Python mit der requests-Bibliothek) verwenden.
Voraussetzungen:
- Erhalten Sie einen API-Schlüssel (opens in a new tab), indem Sie sich für den Zugriff auf die Mistral API anmelden.
- Stellen Sie sicher, dass Ihre lokale Umgebung Internetzugang hat, um mit den Mistral API-Servern zu kommunizieren.
- Installieren Sie das Plugin
llm-mistralfür Ihre lokale Umgebung. Dies könnte bedeuten, es zu den Abhängigkeiten Ihres Projekts hinzuzufügen, falls es sich um ein Programmierprojekt handelt. - Konfigurieren Sie Ihr Projekt oder Ihr Tool so, dass Ihr Mistral API-Schlüssel verwendet wird. Normalerweise erfolgt dies durch Hinzufügen des Schlüssels in einer Konfigurationsdatei oder als Umgebungsvariable.
Chat-Vervollständigungen erstellen
Dieser API-Endpunkt ermöglicht es Ihnen, Textergänzungen basierend auf einer Eingabe zu generieren. Die Anfrage erfordert Angaben zum Modell, zu den Nachrichten (Eingaben) und verschiedenen Parametern, um den Generierungsprozess zu steuern, wie Temperatur, top_p und max_tokens.
Beispielcode für Chat-Vervollständigungen in Python:
import requests
url = "https://api.mistral.ai/chat/completions"
payload = {
"model": "mistral-small-latest",
"messages": [{"role": "user", "content": "Wie fange ich an, Mistral AI zu nutzen?"}],
"temperature": 0.7,
"top_p": 1,
"max_tokens": 512,
"stream": False,
"safe_prompt": False,
"random_seed": 1337
}
headers = {
"Authorization": "Bearer DEIN_API_SCHLÜSSEL",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Fehler:", response.text)Einbettungen erstellen
Der Einbettungs-API-Endpunkt wird verwendet, um Text in hochdimensionale Vektoren umzuwandeln. Dies kann nützlich sein für Aufgaben wie semantische Suche, Clustering oder das Finden ähnlicher Texte.
Beispielcode für das Erstellen von Einbettungen in Python:
import requests
url = "https://api.mistral.ai/embeddings"
payload = {
"model": "mistral-embed",
"input": ["Hallo", "Welt"],
"encoding_format": "float"
}
headers = {
"Authorization": "Bearer DEIN_API_SCHLÜSSEL",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Fehler:", response.text)List verfügbarer Modelle
Dieser API-Aufruf ist unkompliziert und ermöglicht es Ihnen, eine Liste aller für Sie zugänglichen Modelle abzurufen. Dies kann bei der dynamischen Auswahl von Modellen für verschiedene Aufgaben basierend auf deren Fähigkeiten oder Ihren Anforderungen hilfreich sein.
Beispielcode für das Auflisten verfügbarer Modelle in Python:
import requests
url = "https://api.mistral.ai/models"
headers = {
"Authorization": "Bearer DEIN_API_SCHLÜSSEL"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Fehler:", response.text)Diese Beispiele bieten eine Grundlage für die Interaktion mit der Mistral AI-API und ermöglichen die Erstellung anspruchsvoller KI-gesteuerter Anwendungen. Ersetzen Sie dabei den Wert "DEIN_API_SCHLÜSSEL" durch Ihren tatsächlichen API-Schlüssel.
Diese Schritte bieten eine grundlegende Outline für die Integration und Nutzung des Mistral 7B KI-Modells lokal auf einem iPhone und über seine API. Anpassungen können je nach spezifischen Projektanforderungen oder Plattform-Updates erforderlich sein.