Einführung in Jamba, das bahnbrechende SSM-Transformer-Modell

AI21 Labs präsentiert stolz Jamba, das weltweit erste Produktionsmodell auf Basis der revolutionären Mamba-Architektur. Durch die nahtlose Integration der Mamba Structured State Space (SSM)-Technologie mit Elementen der traditionellen Transformer-Architektur überwindet Jamba die Einschränkungen reiner SSM-Modelle und bietet außergewöhnliche Leistung und Effizienz.
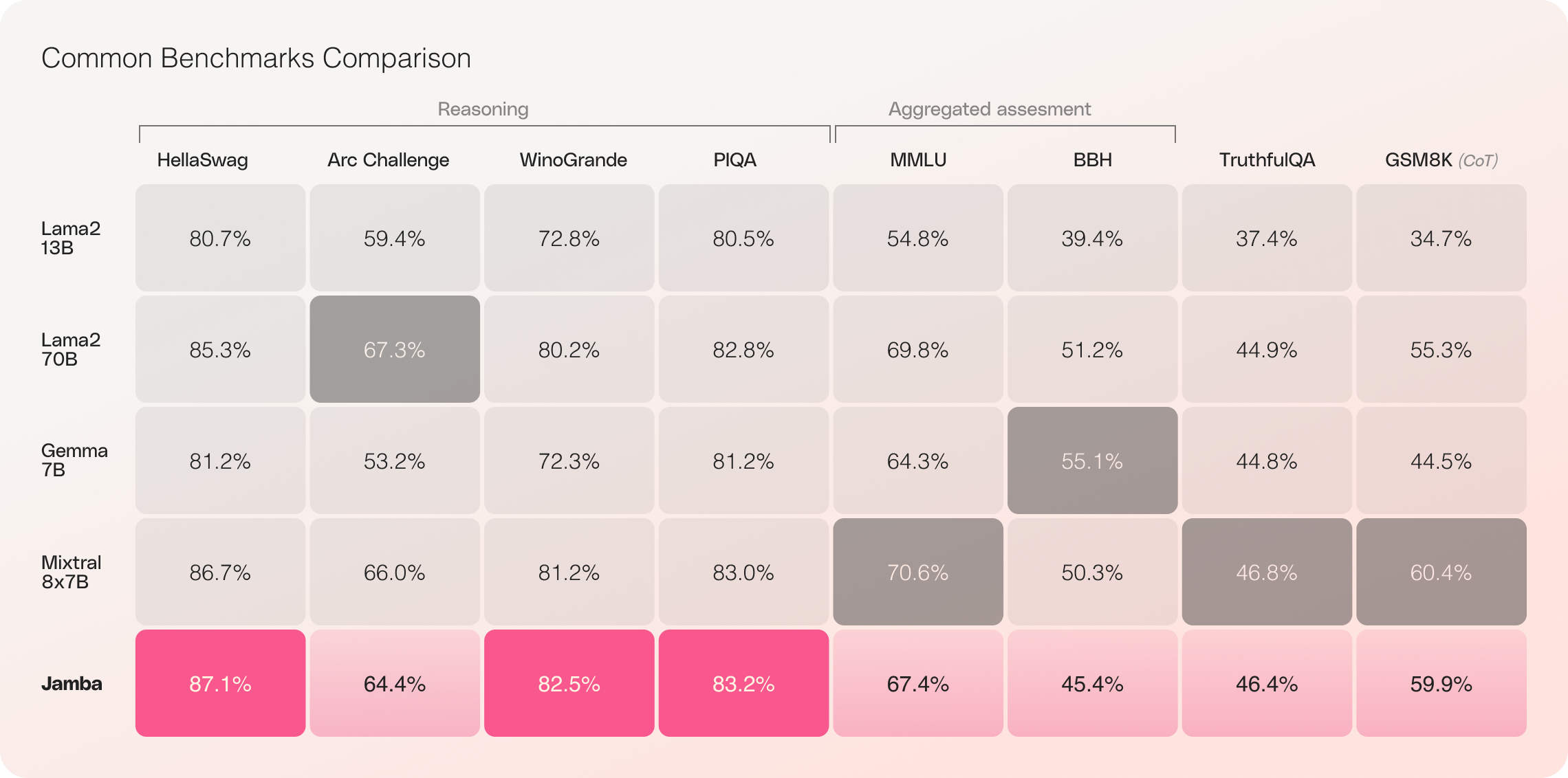
Mit seinem beeindruckenden 256K-Kontextfenster und bemerkenswerten Durchsatzgewinnen wird Jamba voraussichtlich die KI-Landschaft neu gestalten und neue Möglichkeiten für Forscher, Entwickler und Unternehmen eröffnen. Jamba hat bereits herausragende Ergebnisse in einer Vielzahl von Benchmarks erzielt und Modelle der neuesten Generation in seiner Größenklasse erreicht oder übertroffen.
TLDR: Jamba verfügt nicht über Sicherheitsmechanismen und Begrenzungen und verwendet die Apache-2.0 Open-Source-Lizenz.

Hauptmerkmale von Jamba
- Erstes produktionsreifes Mamba-basiertes Modell: Jamba ist das erste Produktionsmodell seiner Art, das die SSM-Transformer-Hybridarchitektur in einem Maßstab und einer Qualität einsetzt.
- Unglaublicher Durchsatz: Jamba erreicht einen 3-fachen Durchsatz bei langen Kontexten im Vergleich zu Mixtral 8x7B und setzt neue Maßstäbe für Effizienz.
- Großes Kontextfenster: Mit einem 256K-Kontextfenster ermöglicht Jamba den Zugriff auf umfangreiche Fähigkeiten zur Kontextverarbeitung für jedermann.
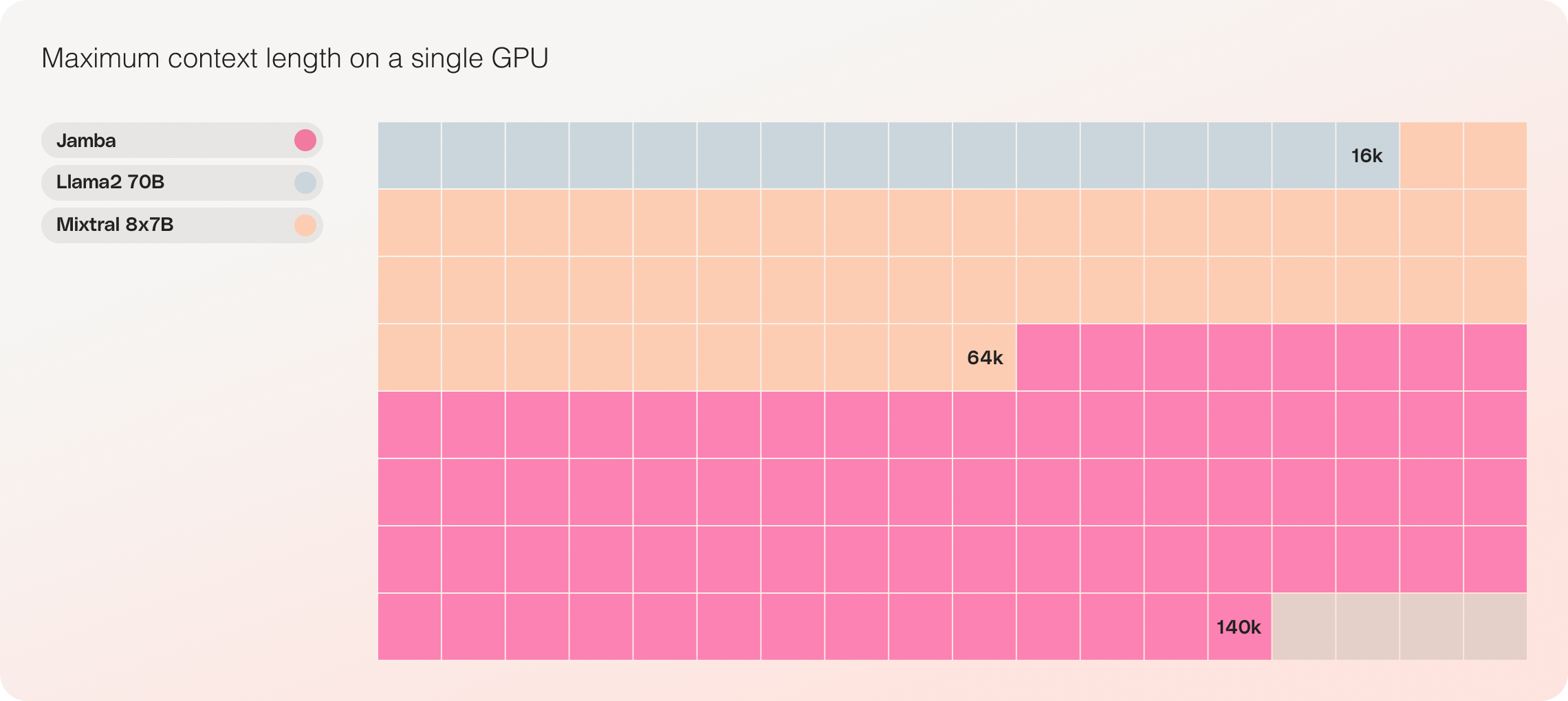
- Kompatibilität mit einer einzelnen GPU: Jamba ist das einzige Modell seiner Größenklasse, das bis zu 140K Kontext auf einer einzelnen GPU speichern kann. Dadurch wird es zugänglicher für Bereitstellung und Experimente.
- Verfügbarkeit als Open Source: Jamba wurde unter der Apache 2.0-Lizenz mit offenen Gewichten veröffentlicht und lädt die KI-Community zu weiteren Optimierungen und Entdeckungen ein.
- Integration in den kommenden NVIDIA-API-Katalog: Jamba wird bald über den NVIDIA-API-Katalog als NVIDIA NIM-Inferenz-Microservice zugänglich sein und es Entwicklern von Unternehmensanwendungen ermöglichen, ihn unter Verwendung der NVIDIA AI Enterprise-Softwareplattform bereitzustellen.
Jamba: Verbindung des Besten aus Mamba- und Transformer-Architekturen
Jamba stellt einen wichtigen Meilenstein in der LLM-Innovation dar, indem es Mamba erfolgreich neben der Transformer-Architektur integriert und das Hybrid-SSM-Transformer-Modell auf eine produktionsreife Qualität bringt.
Traditionelle Transformer-basierte LLMs stehen vor zwei großen Herausforderungen:
- Großer Speicherbedarf: Der Speicherbedarf des Transformers steigt mit der Kontextlänge, was das Ausführen langer Kontextfenster oder zahlreicher paralleler Batches ohne umfangreiche Hardwareressourcen schwierig macht.
- Langsames Inferieren bei langen Kontexten: Der Aufmerksamkeitsmechanismus in Transformers skaliert quadratisch mit der Sequenzlänge, wodurch der Durchsatz verlangsamt wird, da jedes Token von der gesamten vorhergehenden Sequenz abhängt.
Mamba, von Forschern der Carnegie Mellon University und der Princeton University vorgeschlagen, löst diese Probleme. Ohne Aufmerksamkeit für den gesamten Kontext kann Mamba jedoch nicht die Ausgabequalität der besten vorhandenen Modelle erreichen, insbesondere bei rückrufbezogenen Aufgaben.

Jamba vs Mamba vs Transformer
Jambas Hybridarchitektur, bestehend aus Transformer-, Mamba- und Mixtur-von-Experten-(MoE)-Schichten, optimiert gleichzeitig Speicher, Durchsatz und Leistung. Die MoE-Schichten ermöglichen es Jamba, während des Inferierens nur 12B seiner 52B-Parameter zu nutzen, wodurch diese aktiven Parameter effizienter sind als bei einem reinen Transformer-Modell gleicher Größe.
Skalierung der Hybridarchitektur von Jamba
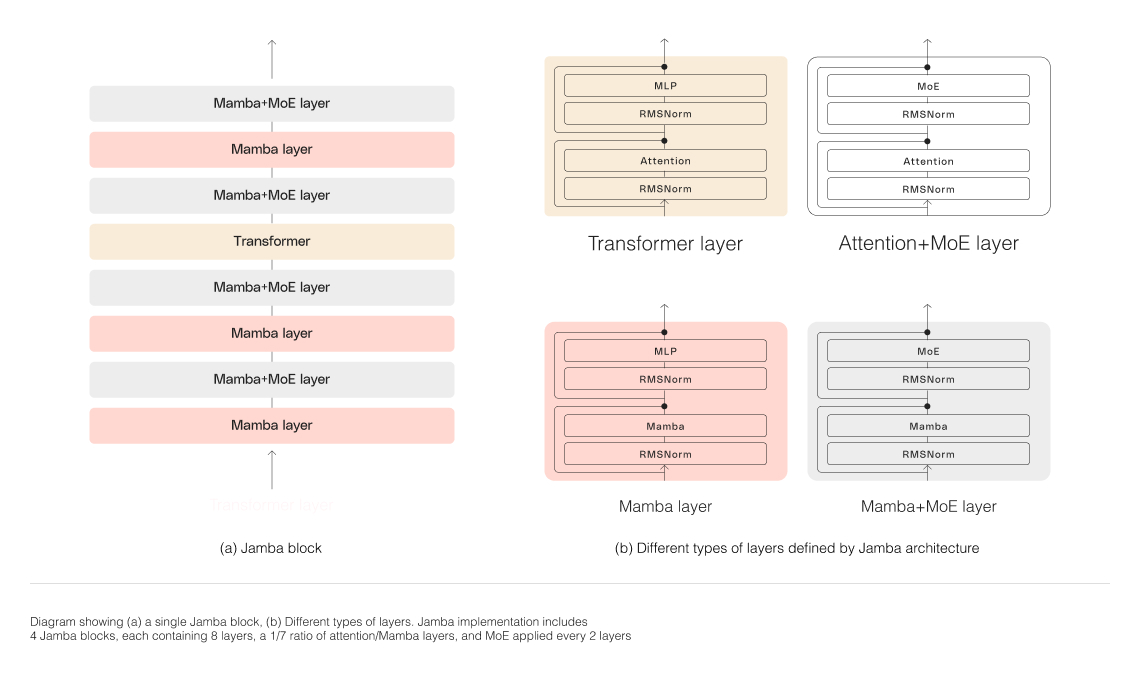
Um die hybride Struktur von Jamba erfolgreich zu skalieren, hat AI21 Labs mehrere Kernarchitekturinnovationen umgesetzt:
-
Ansatz mit Blöcken und Schichten: Jambas Architektur basiert auf einem Ansatz mit Blöcken und Schichten, der eine nahtlose Integration der Transformer- und Mamba-Architekturen ermöglicht. Jeder Jamba-Block enthält entweder eine Aufmerksamkeits- oder eine Mamba-Schicht, gefolgt von einem Mehrschicht-Perzeptron (MLP). Das Ergebnis ist ein Verhältnis von einem Transformer-Layer zu jedem achten Layer.
-
Verwendung der Mixtur-von-Experten (MoE): Durch den Einsatz von MoE-Schichten erhöht Jamba die Gesamtzahl der Modellparameter und optimiert gleichzeitig die Anzahl der aktiven Parameter während des Inferierens. Dadurch wird die Modellkapazität erhöht, ohne dass die Berechnungsanforderungen entsprechend steigen. Die Anzahl der MoE-Schichten und -Experten wurde optimiert, um die Qualität und den Durchsatz des Modells auf einer einzelnen 80GB-GPU zu maximieren und gleichzeitig ausreichend Speicher für häufige Inferenz-Workloads bereitzustellen.
Beeindruckende Leistung und Effizienz von Jamba
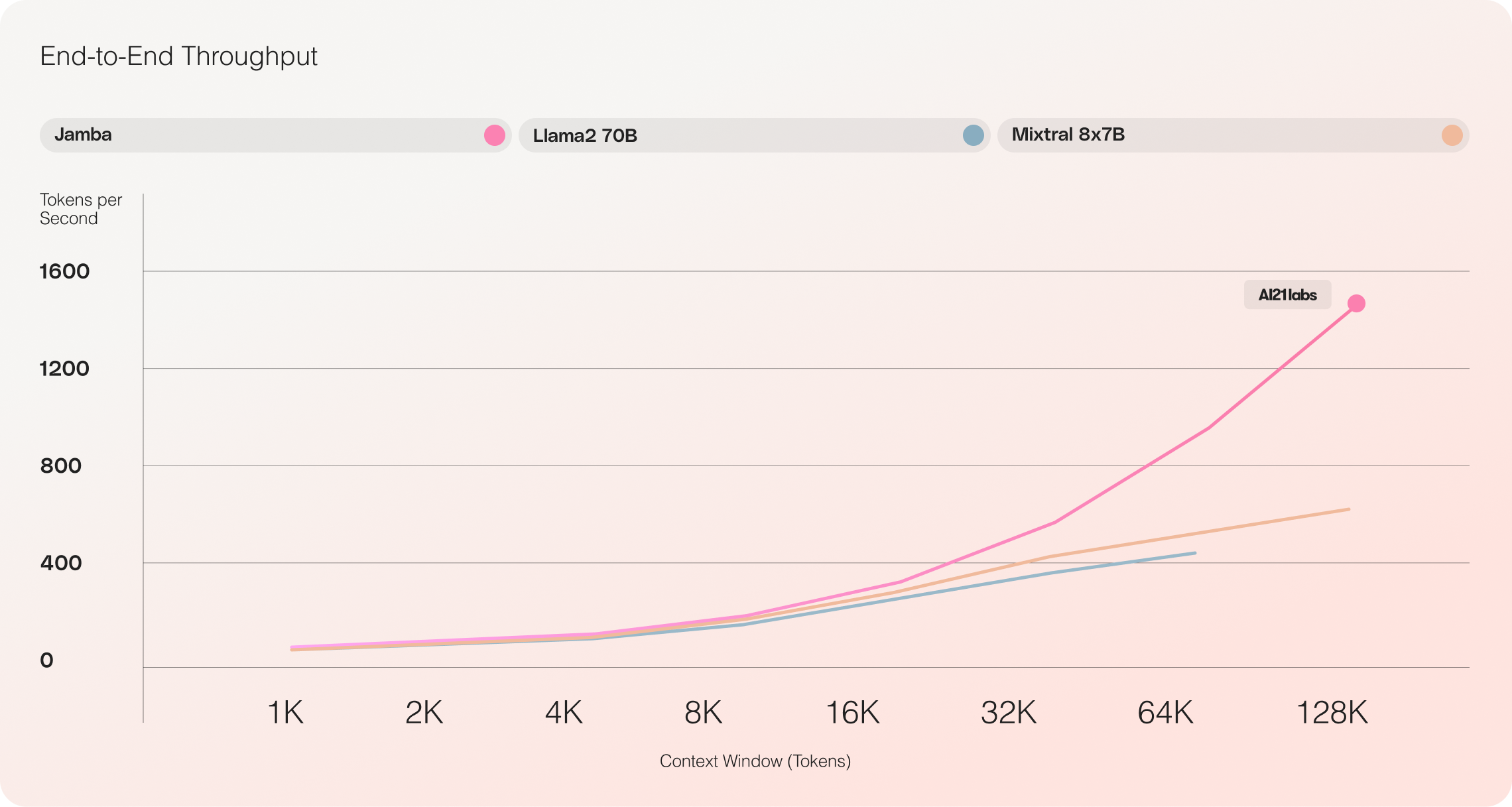
Jamba vs Llama 70B vs Mixtral 8x7B
Erste Evaluationen von Jamba haben beeindruckende Ergebnisse in Bezug auf Schlüsselmessgrößen wie Durchsatz und Effizienz erbracht. Diese Benchmarks werden voraussichtlich weiter verbessert, während die Community weiterhin mit dieser bahnbrechenden Technologie experimentiert und sie optimiert.
- Effizienz: Jamba liefert eine dreifache Durchsatzleistung bei langen Kontexten und ist dadurch effizienter als vergleichbare Transformer-basierte Modelle wie Mixtral 8x7B.
- Kosteneffizienz: Durch die Möglichkeit, 140K Kontext auf einer einzigen GPU zu verarbeiten, ermöglicht Jamba eine einfachere Bereitstellung und experimentelle Möglichkeiten im Vergleich zu anderen Open-Source-Modellen ähnlicher Größe.
Zukünftige Optimierungen wie erweiterte MoE-Parallelisierung und schnellere Mamba-Implementierungen sollen diese bereits beeindruckenden Fortschritte weiter steigern.
Beginnen Sie mit dem Aufbau mit Jamba
Jamba ist jetzt auf Hugging Face erhältlich und wird unter der Apache 2.0-Lizenz mit offenen Gewichten veröffentlicht. Als Basismodell soll Jamba als Grundlage für Feinabstimmung, Training und Entwicklung individueller Lösungen dienen. Es ist wichtig, angemessene Leitplanken für eine verantwortungsbewusste und sichere Nutzung hinzuzufügen.
Eine instruktive Version von Jamba wird in Kürze über die AI21-Plattform verfügbar sein. Um Ihre Projekte zu teilen, Feedback zu geben oder Fragen zu stellen, schließen Sie sich der Diskussion auf Discord an.
Fazit
Die Einführung von Jamba markiert einen bedeutenden Fortschritt in der KI-Technologie und zeigt das immense Potenzial hybrider SSM-Transformer-Architekturen auf. Durch die Kombination der Stärken von Mamba und Transformer und die Optimierung von Effizienz und Leistung setzt Jamba neue Maßstäbe für KI-Modelle in seiner Größenklasse.
Mit seiner beeindruckenden Kontextverarbeitung, Durchsatzleistung und Kosteneffizienz ist Jamba bereit, die KI-Landschaft zu revolutionieren und Forscher, Entwickler und Unternehmen dabei zu unterstützen, die Grenzen des Möglichen zu erweitern. Während die Gemeinschaft Jambas Innovationen weiter erforscht und darauf aufbaut, können wir eine neue Welle von KI-Anwendungen erwarten, die die Zukunft der künstlichen Intelligenz prägen werden.