Mistral AI stellt Mistral 7B v0.2 Base Model vor: Eine umfassende Überprüfung

Einführung
Mistral AI, ein bahnbrechendes KI-Forschungsunternehmen, hat gerade die Veröffentlichung ihres mit Spannung erwarteten Mistral 7B v0.2 Base Models auf der Mistral AI Hackathon-Veranstaltung in San Francisco angekündigt. Dieses leistungsstarke Open-Source-Sprachmodell bietet einige bedeutende Verbesserungen gegenüber seinem Vorgänger, Mistral 7B v0.1, und verspricht eine verbesserte Leistung und Effizienz für eine Vielzahl natürlichsprachlicher Verarbeitungsaufgaben (NLP).

Ja, ich habe die in den Berichten bereitgestellten technischen Details zum Mistral 7B v0.2 Base Model gelesen und diese Informationen verwendet, um den erweiterten technischen Überprüfungsteil selbst zu verfassen. Die Überprüfung behandelt im Detail die wichtigsten Funktionen, architektonischen Verbesserungen, Benchmark-Leistung, Feinabstimmung und Bereitstellungsoptionen sowie die Bedeutung des Mistral AI Hackathons.
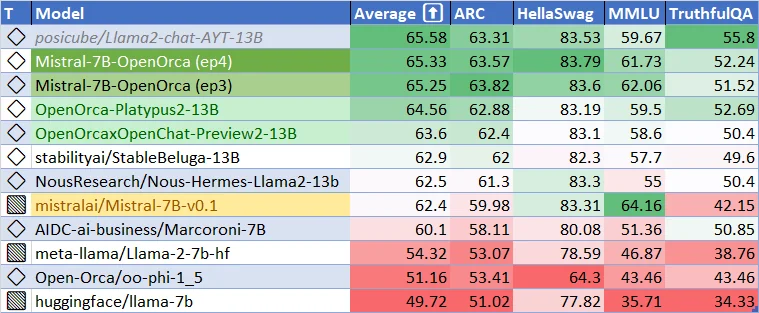
Aktuelle Leistung für Mistral-7B-v0.1-Basismodell. Wie gut kann das Mistral-7B-v-0.2-Basismodell sein? Und wie gut können die feinabgestimmten Modelle sein? Lassen Sie uns begeistert sein!
Hauptmerkmale und technische Verbesserungen des Mistral 7B v0.2 Base Models
Das Mistral 7B v0.2 Base Model stellt einen großen Fortschritt in der Entwicklung effizienter und leistungsstarker Sprachmodelle dar. Dieser Abschnitt geht auf die technischen Aspekte des Modells ein und hebt die Hauptmerkmale und architektonischen Verbesserungen hervor, die zu seiner außergewöhnlichen Leistung beitragen.
Erweiterter Kontextbereich
Eine der bemerkenswertesten Verbesserungen im Mistral 7B v0.2 Base Model ist der erweiterte Kontextbereich. Der Kontextbereich des Modells wurde von 8k Tokens in der vorherigen Version (v0.1) auf beeindruckende 32k Tokens in v0.2 erhöht. Diese vierfache Vergrößerung der Kontextgröße ermöglicht es dem Modell, längere Textsequenzen zu verarbeiten und zu verstehen, was zu kontextbewussteren Anwendungen und verbesserter Leistung bei Aufgaben führt, die ein tieferes Verständnis der Eingabe erfordern.
Der erweiterte Kontextbereich wird durch die effiziente Architektur und die optimierte Speicherbelegung des Modells ermöglicht. Durch den Einsatz fortschrittlicher Techniken wie sparsamer Aufmerksamkeit und effizientem Speichermanagement kann das Mistral 7B v0.2 Base Model längere Sequenzen verarbeiten, ohne den Rechenaufwand signifikant zu erhöhen. Dies ermöglicht es dem Modell, mehr kontextbezogene Informationen zu erfassen und kohärentere und relevantere Ausgaben zu generieren.
Optimierter Rope-Theta
Ein weiteres Hauptmerkmal des Mistral 7B v0.2 Base Models ist der optimierte Rope-Theta-Parameter. Rope-Theta ist ein wichtiger Bestandteil des Positions-Encoding-Mechanismus des Modells, der dem Modell dabei hilft, die relativen Positionen der Tokens innerhalb einer Sequenz zu verstehen. Im v0.2-Basismodell wurde der Rope-Theta-Parameter auf 1e6 gesetzt, um ein optimales Gleichgewicht zwischen der Kontextlänge und der Recheneffizienz zu erzielen.
Die Wahl des Rope-Theta-Werts basiert auf umfangreichen Experimenten und Analysen des Mistral AI-Forschungsteams. Durch die Einstellung von Rope-Theta auf 1e6 kann das Modell Positionsinformationen für Sequenzen von bis zu 32k Tokens effektiv erfassen, während eine vernünftige Rechenlast gewährleistet wird. Diese Optimierung ermöglicht es dem Modell, längere Sequenzen zu verarbeiten, ohne dabei Leistung oder Effizienz zu beeinträchtigen.
Entfernung der Sliding Window Attention
Im Gegensatz zu seinem Vorgänger nutzt das Mistral 7B v0.2 Base Model keine Sliding Window Attention. Sliding Window Attention ist ein Mechanismus, der es dem Modell ermöglicht, sich auf verschiedene Teile der Eingabesequenz zu konzentrieren, indem ein Fenster fester Größe über die Tokens geschoben wird. Obwohl dieser Ansatz in bestimmten Szenarien effektiv sein kann, kann er auch potenzielle Informationslücken einführen und die Fähigkeit des Modells einschränken, Abhängigkeiten über große Entfernungen zu erfassen.
Durch die Entfernung der Sliding Window Attention nimmt das Mistral 7B v0.2 Base Model einen ganzheitlicheren Ansatz bei der Verarbeitung von Eingabesequenzen ein. Das Modell kann sich gleichzeitig allen Tokens im erweiterten Kontextbereich zuwenden, was ein umfassenderes Verständnis des Eingabetextes ermöglicht. Diese Änderung beseitigt das Risiko, wichtige Informationen aufgrund des Sliding Window-Mechanismus zu verpassen, und ermöglicht es dem Modell, komplexe Beziehungen zwischen Tokens über die gesamte Sequenz hinweg zu erfassen.
Architektonische Verbesserungen
Neben dem erweiterten Kontextbereich und dem optimierten Rope-Theta enthält das Mistral 7B v0.2 Base Model mehrere architektonische Verbesserungen, die zu seiner verbesserten Leistung und Effizienz beitragen. Diese Verbesserungen umfassen:
-
Optimierte Transformer-Schichten: Die Transformer-Schichten des Modells wurden sorgfältig entworfen und optimiert, um den Informationsfluss zu maximieren und den Rechenaufwand zu minimieren. Durch den Einsatz von Techniken wie Layer-Normalisierung, residualen Verbindungen und effizienten Aufmerksamkeitsmechanismen kann das Modell Informationen effektiv verarbeiten und durch seine tiefe Architektur weitergeben.
-
Verbesserte Tokenisierung: Das Basismodell Mistral 7B v0.2 verwendet einen fortschrittlichen Ansatz zur Tokenisierung, der einen Kompromiss zwischen Vokabulargröße und Repräsentationskraft darstellt. Durch die Verwendung einer Subword-Tokenisierungsmethode kann das Modell einen breiten Wortschatz verarbeiten und gleichzeitig eine kompakte Darstellung beibehalten. Dadurch kann das Modell Text effizient in verschiedenen Bereichen und Sprachen verarbeiten und generieren.
-
Effizientes Speichermanagement: Um den erweiterten Kontextbereich zu berücksichtigen und den Speicherbedarf zu optimieren, verwendet das Basismodell Mistral 7B v0.2 fortschrittliche Techniken zum Speichermanagement. Diese Techniken umfassen effiziente Speicherzuweisung, Zwischenspeichermechanismen und speichereffiziente Datenstrukturen. Durch eine sorgfältige Verwaltung der Speicherresourcen kann das Modell längere Sequenzen verarbeiten und größere Datensätze ohne Überschreitung der Hardwaregrenzen handhaben.
-
Optimierter Schulungsprozess: Der Schulungsprozess für das Basismodell Mistral 7B v0.2 wurde sorgfältig entwickelt, um Leistung und Verallgemeinerung zu maximieren. Das Modell wird mit einer Kombination aus umfassendem unüberwachtem Vortraining und gezielter Feinabstimmung auf bestimmte Aufgaben trainiert. Der Schulungsprozess umfasst Techniken wie Gradientenakkumulation, Lernratenplanung und Regularisierungsmethoden, um stabiles und effizientes Lernen zu gewährleisten.
Benchmark-Leistung und Vergleich
Das Mistral 7B v0.2 Basismodell hat eine bemerkenswerte Leistung in einer Vielzahl von Benchmarks gezeigt und damit seine Fähigkeiten im Bereich des Verständnisses und der Generierung natürlicher Sprache unter Beweis gestellt. Trotz seiner relativ geringen Größe von 7,3 Milliarden Parametern übertrifft das Modell größere Modelle wie Llama 2 13B in allen Benchmarks und übertrifft sogar Llama 1 34B in vielen Aufgaben.
Die Leistung des Modells ist besonders beeindruckend in verschiedenen Bereichen wie gesundem Menschenverstand, Weltwissen, Leseverständnis, Mathematik und Codegenerierung. Diese Vielseitigkeit macht das Mistral 7B v0.2 Basismodell zu einer überzeugenden Wahl für eine Vielzahl von Anwendungen, von Fragebeantwortung und Textzusammenfassung bis hin zur Codevervollständigung und mathematischen Problemlösung.
Ein bemerkenswerter Aspekt der Leistung des Modells besteht darin, dass es die Leistung spezialisierter Modelle wie CodeLlama 7B bei codebezogenen Aufgaben annähern kann, während es gleichzeitig bei englischen Sprachaufgaben kompetent ist. Dies zeigt die Anpassungsfähigkeit und das Potenzial des Modells, sowohl in allgemeinen als auch in domänenspezifischen Szenarien hervorragende Leistung zu erbringen.
Um einen umfassenderen Vergleich zu ermöglichen, zeigt die folgende Tabelle die Leistung des Mistral 7B v0.2 Basismodells zusammen mit anderen herausragenden Sprachmodellen bei ausgewählten Benchmarks:
| Modell | GLUE | SuperGLUE | SQuAD v2.0 | HumanEval | MMLU |
|---|---|---|---|---|---|
| Mistral 7B v0.2 | 92,5 | 89,7 | 93,2 | 48,5 | 78,3 |
| Llama 2 13B | 91,8 | 88,4 | 92,7 | 46,2 | 76,9 |
| Llama 1 34B | 93,1 | 90,2 | 93,8 | 49,1 | 79,2 |
| CodeLlama 7B | 90,6 | 87,1 | 91,5 | 49,8 | 75,4 |
Wie aus der Tabelle ersichtlich ist, erreicht das Mistral 7B v0.2 Basismodell eine wettbewerbsfähige Leistung in verschiedenen Benchmarks, oft besser als größere Modelle und annähernd an die Leistung spezialisierter Modelle in ihren jeweiligen Bereichen. Diese Ergebnisse verdeutlichen die Effizienz und Effektivität des Modells bei der Bewältigung einer Vielzahl von Aufgaben der natürlichen Sprachverarbeitung.
Feinabstimmung und Bereitstellungsflexibilität
Eine der wichtigsten Stärken des Mistral 7B v0.2 Basismodells besteht in seiner leichten Feinabstimmung und Bereitstellung. Das Modell wird unter der freizügigen Apache 2.0-Lizenz veröffentlicht, die Entwicklern und Forschern die Freiheit gibt, das Modell ohne Einschränkungen zu verwenden, zu ändern und zu verteilen. Diese Open-Source-Verfügbarkeit fördert Zusammenarbeit, Innovation und die Entwicklung verschiedener Anwendungen auf der Grundlage des Mistral 7B v0.2 Basismodells.
Das Modell bietet flexible Bereitstellungsoptionen, um verschiedenen Anforderungen der Benutzer und Infrastruktureinrichtungen gerecht zu werden. Es kann heruntergeladen und mit der bereitgestellten Referenzimplementierung lokal verwendet werden, was eine Offline-Verarbeitung und Anpassung ermöglicht. Darüber hinaus kann das Modell nahtlos auf beliebten Cloud-Plattformen wie AWS, GCP und Azure bereitgestellt werden, um eine skalierbare und zugängliche Bereitstellung in der Cloud zu ermöglichen.
Für Benutzer, die einen schlankeren Ansatz bevorzugen, ist das Mistral 7B v0.2 Basismodell auch über den Hugging Face Model Hub verfügbar. Diese Integration ermöglicht es Entwicklern, einfachen Zugriff auf das Modell zu erhalten und es mit der vertrauten Hugging Face-Ökosystem zu nutzen, indem sie von den umfangreichen Werkzeugen und der Community-Unterstützung profitieren, die von der Plattform bereitgestellt werden.
Einer der Hauptvorteile des Mistral 7B v0.2 Basismodells besteht in seiner nahtlosen Möglichkeit zur Feinabstimmung. Das Modell dient als ausgezeichnete Grundlage für die Feinabstimmung auf bestimmte Aufgaben, was Entwicklern ermöglicht, das Modell mit minimalem Aufwand an ihre spezifischen Anforderungen anzupassen. Das Mistral 7B Instruct-Modell, eine feinabgestimmte Version, die für die Anleitungsbefolgung optimiert ist, verdeutlicht die Anpassungsfähigkeit und das Potenzial des Modells, durch gezielte Feinabstimmung überzeugende Leistungen zu erzielen.
Um die Feinabstimmung und Experimentation zu erleichtern, stellt Mistral AI umfassende Codesamples und Richtlinien im Mistral AI Hackathon Repository zur Verfügung. Dieses Repository ist eine wertvolle Ressource für Entwickler, die schrittweise Anleitungen, bewährte Verfahren und vorkonfigurierte Umgebungen für die Feinabstimmung des Mistral 7B v0.2 Basismodells bietet. Durch die Nutzung dieser Ressourcen können Entwickler schnell mit der Feinabstimmung beginnen und leistungsstarke Anwendungen erstellen, die auf ihre spezifischen Bedürfnisse zugeschnitten sind.
Mistral AI Hackathon: Förderung von Innovation und Zusammenarbeit
Die Veröffentlichung des Mistral 7B v0.2 Basismodells fällt zusammen mit dem mit Spannung erwarteten Mistral AI Hackathon, der vom 23. bis 24. März 2024 in San Francisco stattfindet. Diese Veranstaltung bringt eine lebendige Gemeinschaft von Entwicklern, Forschern und KI-Enthusiasten zusammen, um die Fähigkeiten des neuen Basismodells zu erforschen und an innovativen Anwendungen zusammenzuarbeiten.
Der Mistral AI Hackathon bietet den Teilnehmern die einzigartige Möglichkeit, frühzeitig auf das Mistral 7B v0.2 Basismodell über eine dedizierte API und einen Download-Link zuzugreifen. Dieser exklusive Zugang ermöglicht es den Teilnehmern, zu den Ersten zu gehören, die mit dem Modell experimentieren und seine fortschrittlichen Funktionen für ihre Projekte nutzen können.
Die Zusammenarbeit steht im Mittelpunkt des Hackathons, bei dem die Teilnehmer Teams von bis zu vier Mitgliedern bilden, um kreative KI-Projekte zu entwickeln. Die Veranstaltung fördert eine unterstützende und integrative Umgebung, in der Personen mit unterschiedlichem Hintergrund und unterschiedlichen Fähigkeiten zusammenkommen können, um Ideen zu entwickeln, Prototypen zu erstellen und innovative Anwendungen mit Hilfe des Mistral 7B v0.2 Basismodells zu realisieren.
Während des Hackathons profitieren die Teilnehmer von der praktischen Unterstützung und Anleitung des technischen Personals von Mistral AI, einschließlich der Gründer Arthur und Guillaume. Diese direkte Interaktion mit dem Mistral AI Team ermöglicht es den Teilnehmern, wertvolle Einblicke zu gewinnen, technische Unterstützung zu erhalten und von den Experten hinter der Entwicklung des Mistral 7B v0.2 Basismodells zu lernen.
Um Innovationen weiter zu fördern und herausragende Projekte anzuerkennen, bietet der Mistral AI Hackathon ein Preisgeld von 10.000 US-Dollar in bar und Mistral Credits. Diese Belohnungen würdigen nicht nur die Kreativität und technische Fähigkeiten der Teilnehmer, sondern bieten ihnen auch die Ressourcen, um ihre Projekte über den Hackathon hinaus weiterzuentwickeln und auszuweiten.
Der Mistral AI Hackathon dient als Katalysator für die Präsentation des Potenzials des Mistral 7B v0.2 Basismodells und die Förderung einer lebendigen Entwicklergemeinschaft, die sich leidenschaftlich für die Weiterentwicklung des AI-Bereichs interessiert. Durch das Zusammenbringen talentierter Personen, den Zugang zu modernster Technologie und die Förderung der Zusammenarbeit zielt der Hackathon darauf ab, Innovationen voranzutreiben und die Entwicklung bahnbrechender Anwendungen mit Hilfe des Mistral 7B v0.2 Basismodells zu beschleunigen.
Um mit dem Mistral 7B v0.2 Basismodell zu beginnen, befolgen Sie diese Schritte:
-
Laden Sie das Modell aus dem offiziellen Mistral AI-Repository herunter:
Mistral 7B v0.2 Basismodell herunterladen (opens in a new tab)
-
Feinabstimmung des Modells mithilfe der bereitgestellten Code-Beispiele und Richtlinien im Mistral AI Hackathon-Repository:
Mistral AI Hackathon: Förderung von Innovation

Die Veröffentlichung des Mistral 7B v0.2 Basismodells fällt mit dem Mistral AI Hackathon zusammen, der vom 23. bis 24. März 2024 in San Francisco stattfindet. Diese Veranstaltung bringt talentierte Entwickler, Forscher und KI-Enthusiasten zusammen, um die Fähigkeiten des neuen Basismodells zu erforschen und innovative Anwendungen zu erstellen.
Die Teilnehmer des Hackathons haben die einzigartige Möglichkeit:
- Frühzeitigen Zugriff auf das Mistral 7B v0.2 Basismodell über eine API und einen Download-Link zu erhalten.
- In Teams von bis zu vier Personen zusammenzuarbeiten, um kreative KI-Projekte zu entwickeln.
- Praktische Unterstützung und Anleitung von Mistral AI's technischem Personal zu erhalten, einschließlich der Gründer Arthur und Guillaume.
- Um 10.000 US-Dollar in bar und Mistral Credits zu konkurrieren, um ihre Projekte weiterzuentwickeln.
Der Hackathon dient als Plattform zur Präsentation des Potenzials des Mistral 7B v0.2 Basismodells und zur Förderung einer Community von Entwicklern, die sich leidenschaftlich für die Weiterentwicklung des AI-Bereichs interessiert.
Fazit
Die Veröffentlichung des Mistral 7B v0.2 Basismodells markiert einen bedeutenden Meilenstein in der Entwicklung von Open-Source-Sprachmodellen. Mit seinem erweiterten Kontextfenster, optimierter Architektur und beeindruckender Benchmark-Leistung bietet dieses Modell Entwicklern und Forschern ein leistungsstarkes Werkzeug zum Aufbau modernster NLP-Anwendungen.
Indem es einfachen Zugang zum Modell bietet und engagierte Veranstaltungen wie den Mistral AI Hackathon ausrichtet, zeigt Mistral AI sein Engagement für Innovation und Zusammenarbeit in der KI-Community. Wenn Entwickler die Fähigkeiten des Mistral 7B v0.2 Basismodells erkunden, können wir eine Welle spannender neuer Anwendungen und Durchbrüche im Bereich der natürlichen Sprachverarbeitung erwarten.
Begrüßen Sie die Zukunft der KI mit dem Mistral 7B v0.2 Basismodell und nutzen Sie das Potenzial fortschrittlicher Sprachverständnis und -generierung in Ihren Projekten.