Retrieval-Augmented Generation (RAG): Einfach erklärt
- Name
- Jennie Rose
Published on
Wenn Sie sich in der komplexen Welt der Sprachlernmodelle (LLMs) bewegen, dürfen Sie RAG, kurz für Retrieval-Augmented Generation, nicht übersehen. Diese Technik ist ein Game-Changer und bietet einen differenzierten Ansatz für maschinelles Lernen und die natürliche Sprachverarbeitung. Dieser Leitfaden soll Ihre ultimative Ressource sein, um RAG in LLMs zu verstehen und zu implementieren.
Ob Datenwissenschaftler oder Neuling im maschinellen Lernen, die Beherrschung von RAG kann Ihre Geheimwaffe sein. Wir werden seine Architektur, seine Integration in LLMs, seinen Vergleich mit Fine-Tuning und seine Anwendung in Plattformen wie langChain behandeln. Also, lassen Sie uns loslegen!
Was ist RAG?
Definition von RAG
Retrieval-Augmented Generation (RAG) ist ein fortgeschrittenes maschinelles Lernmodell, das die Fähigkeiten von zwei unterschiedlichen Modelltypen kombiniert: ein Retriever und ein Generator. Im Wesentlichen durchsucht der Retriever ein Datenset nach relevanten Informationen, die der Generator dann verwendet, um eine detaillierte und kohärente Antwort zu konstruieren.
- Retriever: Verwendet Algorithmen wie BM25 oder Dense Retriever, um ein Korpus zu durchsuchen und relevante Dokumente zu finden.
- Generator: In der Regel ein transformer-basiertes Modell wie BERT, GPT-2 oder GPT-3, das menschenähnlichen Text basierend auf den abgerufenen Dokumenten generiert.
Wie RAG funktioniert: Eine technische Vertiefung
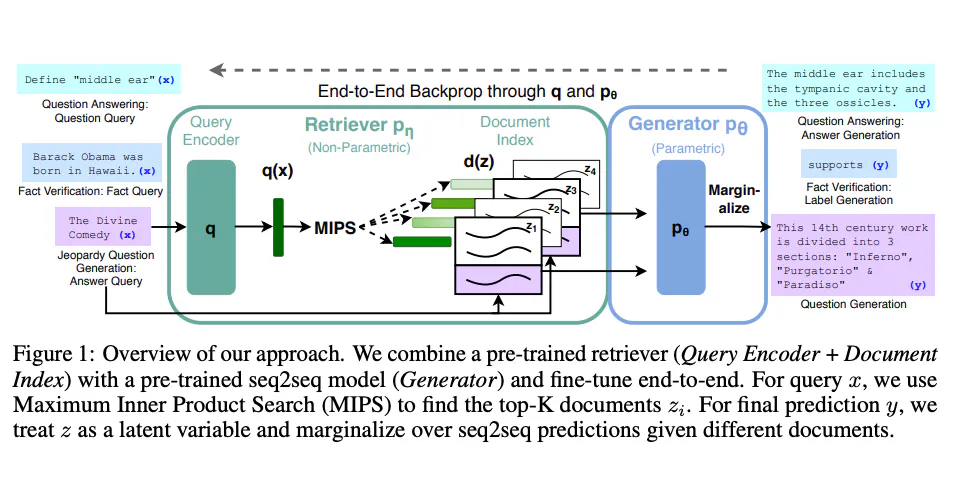
Das RAG-Modell arbeitet in einem zweistufigen Prozess:
- Abrufschritt: Bei einer Abfrage durchsucht der Retriever das Korpus und ruft die
Nrelevantesten Dokumente ab. Dies geschieht oft mit Hilfe einer Ähnlichkeitsmetrik wie der Kosinus-Ähnlichkeit.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(corpus)
query_vector = vectorizer.transform([query])
similarity_scores = cosine_similarity(query_vector, tfidf_matrix)- Generierungsschritt: Der Generator nimmt diese
NDokumente und die ursprüngliche Abfrage entgegen, um eine kohärente Antwort zu generieren.
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base")
retriever = RagRetriever.from_pretrained("facebook/rag-token-base", index_name="exact", use_dummy_dataset=True)
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-base", retriever=retriever)
input_ids = tokenizer(query, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
generated = tokenizer.decode(outputs[0], skip_special_tokens=True)Durch die Kombination dieser beiden Schritte kann RAG komplexe Abfragen mit detaillierten, kontextuell relevanten Antworten beantworten.
Verwendung von RAG für LLMs
Einrichten von RAG für LLMs
Um RAG in LLMs zu implementieren, benötigen Sie:
- Ein Korpus: Dies kann in Form einer SQL-Datenbank, Elasticsearch oder einer einfachen JSON-Datei vorliegen.
- Ein Machine Learning-Framework: TensorFlow oder PyTorch werden häufig verwendet.
- Rechenressourcen: Ausreichende CPU-/GPU-Kapazität für Training und Inferenz.
Schritte zur Implementierung von RAG in LLMs
Hier finden Sie eine Schritt-für-Schritt-Anleitung zur Implementierung von RAG in Ihrem LLM:
- Datenvorbereitung: Ihr Korpus muss in einem durchsuchbaren Format vorliegen. Wenn Sie Elasticsearch verwenden, stellen Sie sicher, dass Ihre Daten indiziert sind.
curl -X PUT "localhost:9200/my_index"-
Modellauswahl: Wählen Sie Ihre Retriever- und Generator-Modelle aus. Sie können vortrainierte Modelle verwenden oder eigene Modelle trainieren.
-
Training: Trainieren Sie die Retriever- und Generator-Modelle. Dies geschieht oft separat.
retriever.train()
generator.train()- Integration: Kombinieren Sie den trainierten Retriever und Generator zu einem einzigen RAG-Modell.
rag_model = RagModel(retriever, generator)- Tests: Überprüfen Sie die Leistung des Modells mithilfe verschiedener Metriken wie BLEU für die Qualität der Textgenerierung und recall@k für die Genauigkeit des Abrufs.
Indem Sie diesen Schritten folgen, erhalten Sie ein robustes RAG-Modell, das in verschiedene LLMs integriert werden kann und überlegene Leistung bietet.
Hilfsfunktionen in RAG für LLMs
Um Ihr RAG-Modell zu evaluieren, können Sie Hilfsfunktionen wie get_retrieval_score() verwenden, die bewerten, wie gut der Retriever funktioniert. Diese Funktion verwendet in der Regel Metriken wie Precision@k oder NDCG zur Bewertung.
from sklearn.metrics import ndcg_score
ndcg = ndcg_score(y_true, y_score)Diese Funktion kann unschätzbar sein, um die Leistung Ihres Retriever-Modells zu verfeinern und sicherzustellen, dass es die relevantesten Dokumente aus dem Korpus abruft.
RAG vs Fine-Tuning
Was unterscheidet RAG und Fine-Tuning?
Obwohl sowohl RAG als auch Fine-Tuning darauf abzielen, die Leistung von Sprachlernmodellen (LLMs) zu verbessern, gehen sie die Aufgabe auf unterschiedliche Weise an. Beim Fine-Tuning wird ein vorhandenes vortrainiertes Modell angepasst, um sich besser an eine spezifische Aufgabe oder einen spezifischen Datensatz anzupassen. RAG hingegen kombiniert Abruf- und Generierungsmechanismen, um komplexe Abfragen zu beantworten.
- Fine-Tuning: Dabei werden die Gewichte eines vortrainierten Modells während der Trainingsphase auf einen spezifischen Datensatz angepasst.
- RAG: Kombiniert einen Retriever und einen Generator, um relevante Informationen aus einem Korpus abzurufen und dann eine kohärente Antwort zu generieren.
Technischer Vergleich: RAG vs Fine-Tuning
- Rechenlast:
- RAG: Erfordert mehr Rechenressourcen, da zwei separate Modelle verwendet werden.
- Fine-Tuning: Im Allgemeinen weniger rechenintensiv.
- Flexibilität:
- RAG: Hochflexibel, kann sich verschiedenen Arten von Abfragen anpassen.
- Feinabstimmung: Auf die spezifische Aufgabe beschränkt, für die sie abgestimmt wurde.
- Datenanforderungen:
- RAG: Erfordert einen großen, gut strukturierten Korpus für die Informationssuche.
- Feinabstimmung: Benötigt einen aufgabenbezogenen Datensatz für das Training.
- Umsetzungskomplexität:
- RAG: Komplexer aufgrund der Integration von zwei Modellen.
- Feinabstimmung: Relativ einfach.
Beispielcode: RAG vs. Feinabstimmung
Für RAG:
# Verwendung der Hugging Face Transformers-Bibliothek
from transformers import RagModel
rag_model = RagModel.from_pretrained("facebook/rag-token-nq")Für Feinabstimmung:
# Feinabstimmung eines BERT-Modells mit PyTorch
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
model.train()Durch das Verständnis dieser Unterschiede können Sie eine informierte Entscheidung darüber treffen, welcher Ansatz am besten für Ihr LLM-Projekt geeignet ist.
Verwendung von RAG für LLM-Anwendungen
Einbindung von RAG in bestehende LLMs
Wenn Sie bereits ein LLM haben und RAG integrieren möchten, befolgen Sie diese Schritte:
-
Bestimmen Sie den Anwendungsfall: Bestimmen Sie, was Sie mit RAG erreichen möchten - ob es sich um eine bessere Fragebeantwortung, Zusammenfassung oder etwas anderes handelt.
-
Datenabstimmung: Stellen Sie sicher, dass Ihr vorhandener Korpus mit dem Relevanzsucher kompatibel ist, den Sie in RAG verwenden möchten.
-
Modellintegration: Integrieren Sie das RAG-Modell in die Architektur Ihres bestehenden LLM.
# Beispiel mit PyTorch
class MyLLMWithRAG(nn.Module):
def __init__(self, my_llm, rag_model):
super(MyLLMWithRAG, self).__init__()
self.my_llm = my_llm
self.rag_model = rag_model- Tests und Validierung: Führen Sie Tests durch, um zu validieren, dass das RAG-Modell die Leistung Ihres LLM verbessert.
Häufige Fallstricke und wie man sie vermeidet
- Unzureichender Korpus: Stellen Sie sicher, dass Ihr Korpus groß und vielfältig genug ist, damit der Relevanzsucher relevante Dokumente findet.
- Nicht übereinstimmende Modelle: Der Relevanzsucher und der Generator sollten in Bezug auf Datentypen und Dimensionen kompatibel sein.
Durch sorgfältige Integration von RAG in Ihre LLM-Anwendungen können Sie deren Fähigkeiten und Leistung signifikant verbessern.
Verwendung von RAG mit langChain
Was ist langChain?
langChain ist eine dezentralisierte Plattform für Sprachmodelle. Sie ermöglicht die Integration verschiedener maschineller Lernmodelle, einschließlich RAG, um verbesserte natürliche Sprachverarbeitungsdienste anzubieten.
Schritte zur Implementierung von RAG in langChain
-
Installation: Installieren Sie das langChain SDK und richten Sie Ihre Entwicklungsumgebung ein.
-
Modell-Upload: Laden Sie Ihr vortrainiertes RAG-Modell auf die langChain-Plattform hoch.
langChain upload --model my_rag_model- API-Integration: Verwenden Sie die API von langChain, um das RAG-Modell in Ihre Anwendung zu integrieren.
from langChain import RagService
rag_service = RagService(api_key="your_api_key")- Abfrageausführung: Führen Sie Abfragen über die langChain-Plattform aus, die Ihr RAG-Modell zur Generierung von Antworten einsetzt.
response = rag_service.query("Was ist der Sinn des Lebens?")Durch Befolgung dieser Schritte können Sie RAG nahtlos in langChain integrieren und dabei die dezentrale Architektur der Plattform für verbesserte Leistung und Skalierbarkeit nutzen.
Fazit
RAG ist ein leistungsstarkes Werkzeug, das die Fähigkeiten von Language Learning Models erheblich erweitern kann. Egal ob Sie es in vorhandene LLMs integrieren möchten, es mit Feinabstimmungsmethoden vergleichen oder sogar in dezentralisierten Plattformen wie langChain verwenden möchten - das Verständnis von RAG kann Ihnen einen deutlichen Vorteil verschaffen. Mit seinen dualen Mechanismen der Informationssuche und Generierung bietet RAG einen nuancierten Ansatz für komplexe Abfragen und ist somit eine wertvolle Ressource im Bereich des maschinellen Lernens und der natürlichen Sprachverarbeitung.
FAQs
Was ist RAG in LLM?
RAG oder Retrieval-Augmented Generation ist eine Technik, die einen Relevanzsucher und einen Generator kombiniert, um komplexe Abfragen in Language Learning Models zu beantworten.
Was ist der Unterschied zwischen RAG und LLM?
RAG ist eine spezifische Technik, um die Fähigkeiten von LLMs zu verbessern. Es handelt sich nicht um ein eigenständiges Modell, sondern um eine Komponente, die in vorhandene LLMs integriert werden kann.
Wie bewertet man ein rag LLM?
Bewertungsmetriken wie BLEU für die Qualität der Textgenerierung und recall@k für die Genauigkeit der Informationssuche werden häufig verwendet.
Was ist rag vs. Feinabstimmung?
RAG kombiniert Mechanismen der Informationssuche und Generierung, während Feinabstimmung die Anpassung eines vorhandenen Modells an eine spezifische Aufgabe beinhaltet.
Was sind die Vorteile von Rag LLM?
RAG ermöglicht nuanciertere und inhaltlich relevante Antworten, was es besonders effektiv für komplexe Abfragen macht.