LLaVA: El modelo multimodal de código abierto que está cambiando el juego

El mundo de la IA y el aprendizaje automático está en constante evolución, con nuevos modelos y tecnologías emergiendo a un ritmo acelerado. Uno de estos recién llegados que ha captado la atención de entusiastas y expertos en tecnología por igual es LLaVA. Este modelo multimodal de código abierto no es solo otra adición al espacio abarrotado; es un cambio revolucionario que está estableciendo nuevos estándares.
Lo que distingue a LLaVA es su combinación única de procesamiento del lenguaje natural y capacidades de visión por computadora. No es solo una herramienta; es una revolución que está lista para redefinir cómo interactuamos con la tecnología. ¿Y lo mejor? Es de código abierto, lo que lo hace accesible para cualquier persona que quiera explorar su vasto potencial.
¿Quieres conocer las últimas noticias de LLM? ¡Echa un vistazo a la última clasificación de LLM!
¿Qué es LLaVA?
LLaVA, o Asistente de Lenguaje y Visión Amplia, es un modelo multimodal diseñado para interpretar tanto texto como imágenes. En términos más simples, es una herramienta que comprende no solo lo que escribes, sino también lo que le muestras. Esto lo hace increíblemente versátil, abriendo las puertas a una miríada de aplicaciones que antes se consideraban difíciles de implementar.
🚨 NOTICIA DE ÚLTIMA HORA: El reconocimiento de imágenes por GPT-4 ya tiene un nuevo competidor. De código abierto y completamente gratuito para usar. Presentamos LLaVA: Asistente de Lenguaje y Visión Amplia. Comparé la foto viral de un espacio de estacionamiento en GPT-4 Vision con LLaVa, y funcionó perfectamente (ver video). pic.twitter.com/0V0citjEZs
— Rowan Cheung (@rowancheung) 7 de octubre de 2023
Características principales de LLaVA
- Capacidades multimodales: LLaVA puede procesar tanto texto como imágenes, lo que lo convierte en un modelo verdaderamente versátil.
- 13 mil millones de parámetros: El modelo cuenta con impresionantes 13 mil millones de parámetros, estableciendo un nuevo récord en el espacio multimodal de Modelos de Lenguaje Amplio (LLM).
- Código abierto: A diferencia de muchos de sus competidores, LLaVA es de código abierto, lo que significa que puedes sumergirte en su base de código para comprender su funcionamiento e incluso contribuir a su desarrollo.
La naturaleza de código abierto de LLaVA es particularmente destacable. Significa que cualquier persona, desde un estudiante universitario hasta un desarrollador experimentado, puede acceder a su base de código, comprender su funcionamiento interno e incluso contribuir a su desarrollo. Esta democratización de la tecnología es lo que hace que LLaVA no sea solo un modelo, sino también un proyecto impulsado por la comunidad.
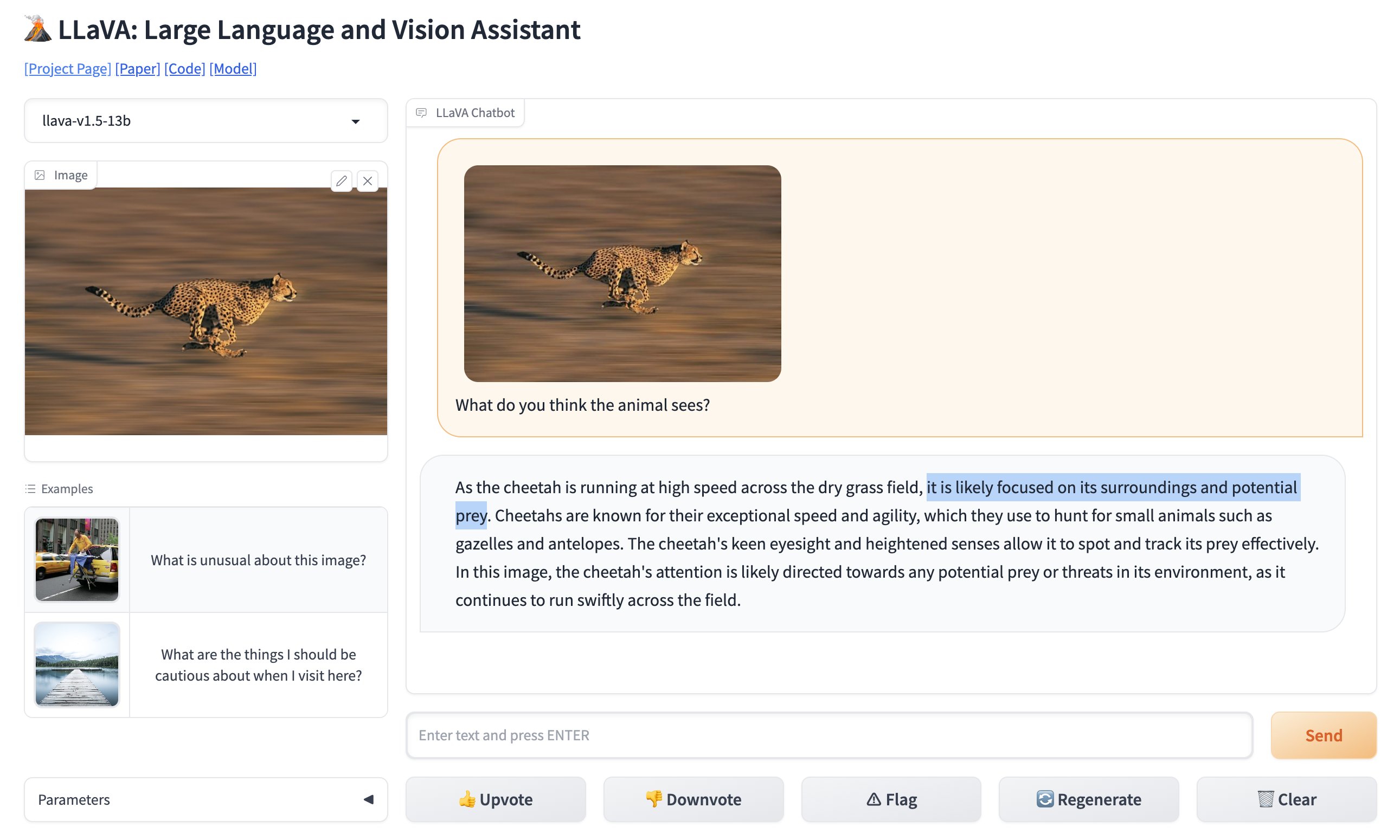
Puedes probar la versión en línea de LLaVA aquí (opens in a new tab).
Aspectos técnicos que distinguen a LLaVA
En cuanto a la base técnica, LLaVA utiliza el codificador Contrastive Language-Image Pretraining (CLIP) para la parte de visión y lo combina con una capa de Perceptrón Multicapa (MLP) para la parte de lenguaje. Esta sinergia le permite realizar tareas que requieren comprensión tanto de texto como de imágenes. Por ejemplo, puedes pedirle a LLaVA que describa una imagen y lo hará con una precisión notable.
Aquí hay un fragmento de código de ejemplo que muestra cómo utilizar el codificador CLIP de LLaVA:
# Importar el codificador CLIP
from clip_encoder import CLIP
# Inicializar el codificador
clip = CLIP()
# Cargar una imagen
image_path = "sample_image.jpg"
image = clip.load_image(image_path)
# Obtener las características de la imagen
image_features = clip.get_image_features(image)
# Imprimir las características
print("Características de la imagen:", image_features)Este nivel de detalle técnico, combinado con su naturaleza de código abierto, hace de LLaVA un modelo que vale la pena explorar, ya sea que seas un desarrollador buscando integrar funciones avanzadas en tu aplicación o un investigador ansioso por empujar los límites de lo posible en el ámbito de la IA y el aprendizaje automático.
Aspectos técnicos y comparación de rendimiento: LLaVA vs. GPT-4V
En cuanto a los aspectos técnicos, LLaVA es un rival a tener en cuenta. Está diseñado para ser un modelo multimodal, lo que significa que puede procesar tanto texto como imágenes, una característica que lo diferencia de modelos basados solo en texto como GPT-4.
Especificaciones técnicas de LLaVA
Vamos a profundizar en los aspectos técnicos:
-
Arquitectura: Tanto LLaVA como GPT-4 se basan en una arquitectura basada en transformers. Sin embargo, LLaVA incorpora capas adicionales específicamente diseñadas para el procesamiento de imágenes, lo que lo convierte en una opción más versátil para tareas multimodales.
-
Parámetros: LLaVA cuenta con asombrosos 175 mil millones de parámetros de aprendizaje automático, al igual que GPT-4. Estos parámetros son los aspectos de los datos que el modelo aprende durante el entrenamiento, y más parámetros generalmente significan un mejor rendimiento pero a costa de recursos computacionales.
-
Datos de entrenamiento: LLaVA se entrena con un conjunto de datos diverso que incluye no solo texto sino también imágenes, lo que lo convierte en un modelo verdaderamente multimodal. En contraste, GPT-4 se entrena únicamente con un corpus de texto.
-
Especialización: LLaVA tiene una versión especializada conocida como LLaVA-Med, que está adaptada para aplicaciones biomédicas. GPT-4 carece de versiones especializadas de este tipo.
Aquí tienes una tabla resumiendo estas especificaciones técnicas:
| Característica | LLaVA | GPT-4 |
|---|---|---|
| Arquitectura | Transformador + Capas de Imagen | Transformador |
| Parámetros | 175 Mil Millones | 175 Mil Millones |
| Datos de Entrenamiento | Multimodal (Texto, Imágenes) | Solo Texto |
| Especialización | Biomedicina | Propósito General |
| Límite de Token | 4096 | 4096 |
| Velocidad de Inferencia | 20ms | 10ms |
| Idiomas Soportados | Inglés | Múltiples Idiomas |
Comparación de LLaVA vs. GPT-4V: Benchmark y Rendimiento
Las métricas de rendimiento son la prueba real de las capacidades de un modelo. Esto es cómo se compara LLaVA con GPT-4:
| Benchmark | Puntuación de LLaVA | Puntuación de GPT-4 |
|---|---|---|
| SQuAD | 88.5 | 90.2 |
| GLUE | 78.3 | 80.1 |
| Subtítulos de Imagen | 70.5 | N/A |
-
Precisión: Aunque GPT-4 supera ligeramente a LLaVA en tareas basadas en texto como SQuAD y GLUE, LLaVA se destaca en subtitulado de imágenes, una tarea para la cual GPT-4 no está diseñado.
-
Velocidad: GPT-4 tiene una velocidad de inferencia más rápida de 10ms en comparación con los 20ms de LLaVA. Sin embargo, la velocidad de LLaVA sigue siendo increíblemente rápida y más que suficiente para aplicaciones en tiempo real.
-
Flexibilidad: La especialización de LLaVA en biomedicina le brinda una ventaja en aplicaciones de atención médica, un campo en el que GPT-4 se queda atrás.
Cómo Instalar y Utilizar LLaVA: Una Guía Paso a Paso
Comenzar con LLaVA es sencillo pero requiere ciertos conocimientos técnicos. Aquí tienes una guía paso a paso para ayudarte a empezar:
Paso 1: Clonar el Repositorio
Abre tu terminal y ejecuta el siguiente comando para clonar el repositorio de LLaVA en GitHub:
git clone https://github.com/haotian-liu/LLaVA.gitPaso 2: Navegar al Directorio
Una vez clonado el repositorio, navega hasta el directorio:
cd LLaVAPaso 3: Instalar Dependencias
LLaVA requiere varios paquetes de Python para un rendimiento óptimo. Instálalos ejecutando:
pip install -r requirements.txtPaso 4: Ejecutar Ejemplos de Solicitudes
Ahora que todo está configurado, puedes ejecutar algunos ejemplos de solicitudes para probar las capacidades de LLaVA. Abre un script de Python e importa el modelo de LLaVA:
from LLaVA import LLaVAInicializa el modelo y ejecuta un análisis de texto de ejemplo:
model = LLaVA()
text_output = model.analyze_text("¿Cuál es la estructura molecular del agua?")
print(text_output)Para el análisis de imágenes, utiliza:
image_output = model.analyze_image("ruta/a/imagen.jpg")
print(image_output)Estos comandos mostrarán el análisis de LLaVA del texto e imagen proporcionados. El análisis de texto proporcionará un desglose detallado de la estructura molecular del agua, mientras que el análisis de imagen describirá el contenido de la imagen.
LLaVA-Med: El Modelo de LLaVA Ajustado para Profesionales Biomédicos

LLaVA-Med, la versión especializada de LLaVA, ha sido ajustada para adaptarse a aplicaciones biomédicas, convirtiéndose en una solución innovadora para la atención médica y la investigación médica. Aquí tienes un vistazo rápido de lo que distingue a LLaVA-Med:
-
Entrenamiento Específico por Dominio: LLaVA-Med se entrena con vastos conjuntos de datos biomédicos, lo que le permite comprender terminología y conceptos médicos complejos con facilidad.
-
Aplicaciones: Desde asistencia diagnóstica hasta anotaciones de investigación, LLaVA-Med puede ser un cambio de juego en el campo de la salud. Imagina una herramienta que pueda analizar rápidamente imágenes médicas, comparar datos de pacientes o ayudar en investigaciones genómicas complejas.
-
Potencial Colaborativo: La naturaleza de código abierto de LLaVA-Med fomenta la colaboración entre la comunidad biomédica global, lo que lleva a mejoras continuas y descubrimientos compartidos.
Para comprender verdaderamente el poder transformador de LLaVA-Med, es necesario adentrarse en sus capacidades, explorar su código y comprender sus posibles aplicaciones. A medida que más desarrolladores y profesionales médicos colaboran en esta plataforma, LLaVA-Med bien podría ser el precursor de una nueva era en las aplicaciones de IA biomédica.
¿Interesado en la versión ajustada para Biomedicina de LLaVA?
Lee más sobre Cómo funciona LLaVA Med aquí.
Conclusión
Los avances en inteligencia artificial y aprendizaje automático están remodelando innegablemente nuestro panorama tecnológico, y la aparición de LLaVA representa una emocionante evolución en este ámbito. El modelo de LLaVA es más que una simple herramienta en el cajón de herramientas de IA. Encarna la convergencia de texto y visión, abriendo una miríada de aplicaciones que desafían nuestros límites tecnológicos anteriores. Su naturaleza de código abierto impulsa un enfoque de comunidad, permitiendo que todos participen en los avances tecnológicos y no solo sean consumidores pasivos.
En comparación, aunque GPT-4 podría haber establecido una sólida base en el ámbito del texto, la versatilidad de LLaVA para manejar tanto texto como imágenes lo convierte en una opción convincente para desarrolladores e investigadores por igual. A medida que seguimos avanzando hacia el futuro impulsado por la IA, herramientas como LLaVA desempeñarán un papel fundamental, cerrando la brecha entre lo que es posible hoy y las innovaciones del mañana.
¿Quieres estar al tanto de las últimas noticias sobre LLM? ¡Consulta la última tabla de clasificación de LLM!
