Las 10 mejores bases de datos vectoriales de 2023: Una revisión completa

Las bases de datos vectoriales ya no son un tema de nicho discutido solo entre científicos de datos y administradores de bases de datos. A medida que avanzamos hacia 2023, se han convertido en un punto central para cualquier persona que maneje tipos de datos complejos como imágenes, audio y texto. Pero, ¿qué son exactamente las bases de datos vectoriales y por qué están atrayendo tanta atención?
En este artículo, desmitificaremos las bases de datos vectoriales, analizaremos sus ventajas y desventajas, y revelaremos el bombo que las rodea. También te mostraremos una visión exclusiva de las 9 mejores bases de datos vectoriales de 2023, con un enfoque especial en las opciones de código abierto. ¡Así que sumerjámonos!
¿Quieres conocer las últimas noticias de LLM? ¡Consulta la última tabla de clasificación de LLM!
¿Qué es una base de datos vectorial?
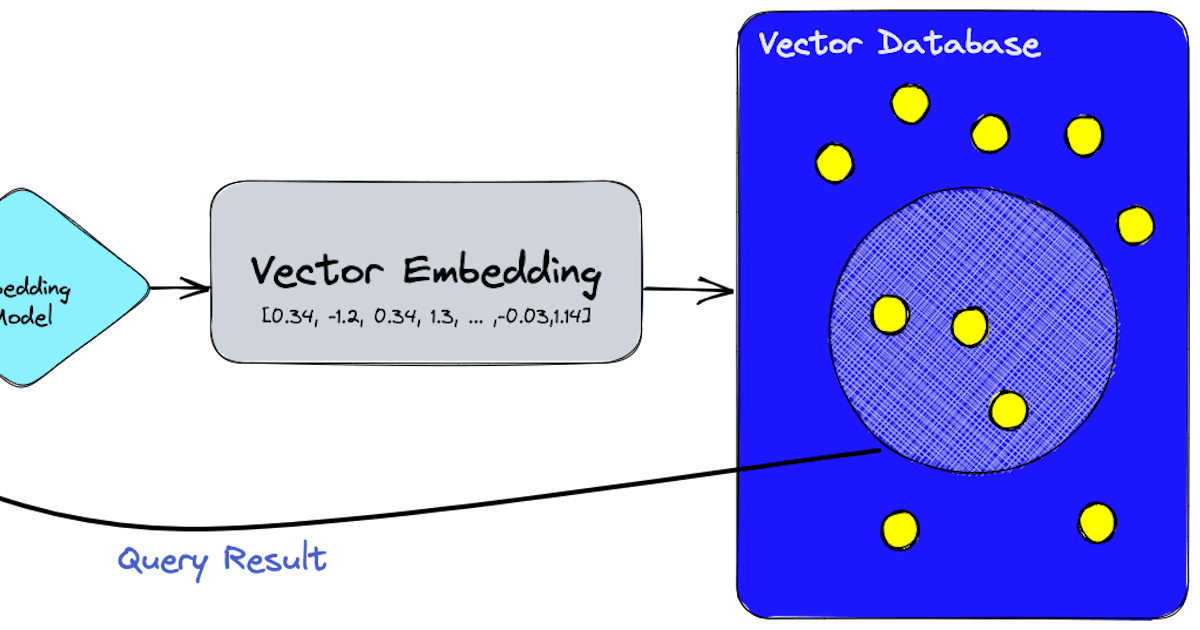
Una base de datos vectorial es un tipo especializado de base de datos diseñado para manejar tipos de datos complejos con los que las bases de datos tradicionales tienen dificultades. A diferencia de las bases de datos relacionales estándar que almacenan datos en tablas, las bases de datos vectoriales utilizan vectores matemáticos para representar los datos. Esto les permite gestionar y buscar eficientemente datos de alta dimensionalidad como imágenes, archivos de audio y contenido textual.
Las bases de datos vectoriales utilizan algoritmos como k-NN (k-Nearest Neighbors) para buscar en los datos de alta dimensionalidad. También emplean técnicas como la cuantización y particionamiento para optimizar el rendimiento de la búsqueda. Aquí tienes un ejemplo de consulta para buscar imágenes similares en una base de datos vectorial:
SELECT * FROM images WHERE VECTOR_SEARCH(image_vector, target_vector) < 0.2;En esta consulta de ejemplo, VECTOR_SEARCH es una función que calcula la similitud entre image_vector y target_vector. El < 0.2 especifica el umbral de similitud.
¿Por qué las bases de datos vectoriales son diferentes?
-
Manejo de datos de alta dimensionalidad: Las bases de datos tradicionales no están preparadas para manejar datos de alta dimensionalidad. Las bases de datos vectoriales llenan este vacío utilizando vectores matemáticos para representar los datos, lo que facilita el manejo de tipos de datos complejos.
-
Capacidad de búsqueda rápida: Una de las características destacadas de las bases de datos vectoriales es su capacidad para realizar búsquedas de similitud rápidas. Por ejemplo, si tienes una imagen, una base de datos vectorial puede encontrar rápidamente imágenes similares en la base de datos sin tener que analizar cada entrada.
-
Escalabilidad: A medida que los datos crecen, la necesidad de bases de datos que puedan escalar sin degradación del rendimiento se vuelve crucial. Las bases de datos vectoriales están diseñadas teniendo en cuenta la escalabilidad, lo que les permite manejar grandes volúmenes de datos de manera eficiente.
Revisión de bases de datos vectoriales: ¿Cumplen con el bombo?
Como sucede con cualquier tecnología emergente, las bases de datos vectoriales han estado rodeadas de una considerable cantidad de bombo. Muchos afirman que son la próxima gran cosa en la tecnología de bases de datos, estableciendo paralelismos con el movimiento NoSQL que perturbó el panorama de las bases de datos hace una década. Pero ¿cuánto de esto es cierto y qué precauciones debes tomar?
La dura verdad de las bases de datos vectoriales: ¿Deberías adaptarte?
El bombo no es del todo infundado. Las bases de datos vectoriales ofrecen capacidades únicas que las bases de datos tradicionales carecen, especialmente cuando se trata de manejar datos complejos y de alta dimensionalidad. Sin embargo, es esencial separar el trigo de la paja. No todas las bases de datos vectoriales cumplen con el bombo, y algunas se centran más en el marketing que en ofrecer funciones sólidas.
Qué tener en cuenta al elegir bases de datos vectoriales:
-
Prometer demasiado y cumplir poco: Algunas bases de datos vectoriales prometen el oro y el moro, pero no cumplen con características esenciales como alta disponibilidad, sistemas de respaldo y tipos de datos avanzados como geoespaciales y de fecha y hora.
-
Complejidad: Si bien las bases de datos vectoriales son potentes, también pueden ser complejas de configurar y administrar. Asegúrate de tener la experiencia técnica para manejarlas o prepárate para invertir en formación.
-
Costos: Ten cuidado con los costos ocultos, especialmente con bases de datos propietarias. Las tarifas de licencia pueden acumularse y es posible que también necesites invertir en hardware especializado.
Al ser consciente de estos puntos, puedes navegar por el bombo y tomar decisiones más informadas. Recuerda siempre mirar más allá de las palabras de moda de marketing y profundizar en las características y limitaciones reales de la base de datos.
Ventajas vs Desventajas de las Bases de Datos Vectoriales
Las bases de datos vectoriales han ganado popularidad por su capacidad para manejar tipos de datos complejos como imágenes, audio y texto. Sin embargo, es crucial entender tanto sus ventajas como sus limitaciones.
Ventajas de las bases de datos vectoriales:
-
Búsqueda eficiente de similitud: Las bases de datos vectoriales destacan en encontrar los vecinos más cercanos en espacios de alta dimensionalidad, lo cual es crucial para sistemas de recomendación, reconocimiento de imágenes y procesamiento del lenguaje natural.
-
Escalabilidad: Muchas bases de datos vectoriales están diseñadas para manejar datos a gran escala, incluso algunas ofrecen arquitecturas distribuidas para escalado horizontal.
-
Flexibilidad: Con soporte para varios métricas de distancia y algoritmos de indexación, las bases de datos vectoriales pueden adaptarse fácilmente a casos de uso específicos.
-
Intensivas en recursos: La búsqueda de alta velocidad a menudo conlleva el uso intensivo de recursos computacionales. Algunas bases de datos requieren hardware especializado para un rendimiento óptimo.
Desventajas de las bases de datos vectoriales:
- Complejidad: La multitud de opciones algorítmicas y configuraciones puede hacer que las bases de datos vectoriales sean difíciles de configurar y mantener.
- Costo: Si bien existen opciones de código abierto, las bases de datos de vectores comerciales pueden ser costosas, especialmente para implementaciones a gran escala.
Principales 10 Bases de Datos de Vectores para Considerar en 202
Principales Bases de Datos de Vectores de Código Abierto en 2023
1. Faiss
- Precio de Inicio: Gratis (Código Abierto)
- Valoración: 4.7/5
- Pros:
- Aceleración excepcional de GPU a través de CUDA
- Admite miles de millones de vectores
- Amplias opciones algorítmicas como IVFADC, PQ y HNSW
- Contras:
- Requiere experiencia en cuantificación de vectores
- Limitado a implementaciones en un solo nodo
Detalles Técnicos: Faiss (opens in a new tab) utiliza una variedad de técnicas de indexación, incluyendo Inverted File Segmenter (IVF) y Scalar Quantizer (SQ) para búsquedas de similitud eficientes. También admite el procesamiento de consultas por lotes y la paralelización en múltiples GPUs. La biblioteca está optimizada tanto para la distancia L2 como para la similitud del producto interno, lo que la hace versátil para diferentes casos de uso.
Faiss Vector Database en GitHub: https://github.com/facebookresearch/faiss (opens in a new tab)

2. Annoy (Aproximación de los Vecinos Más Cercanos ¡Oh Sí!)
- Precio de Inicio: Gratis (Código Abierto)
- Valoración: 4.5/5
- Pros:
- Utiliza bosques de árboles para particionar el espacio vectorial
- Soporte de archivos mapeados en memoria para datos a gran escala
- Complejidad asintótica de las consultas es (O(\log N))
- Contras:
- Limitado a las métricas de distancia Angular, Euclidiana, Manhattan y Hamming
- Sin soporte nativo para computación distribuida
Detalles Técnicos: Annoy Vector Database (opens in a new tab) construye un árbol binario para cada vector, particionando el espacio en semiespacios. Luego, los árboles se utilizan para una búsqueda eficiente del vecino más cercano. También admite tiempos de construcción multi-hilo y permite guardar los índices en disco, que se pueden mapear en memoria posteriormente para búsquedas de similitud a gran escala.
Annoy Vector Database en GitHub: https://github.com/spotify/annoy (opens in a new tab)
3. NMSLIB (Biblioteca de Espacio No Métrico)
- Precio de Inicio: Gratis (Código Abierto)
- Valoración: 4.6/5
- Pros:
- Admite una gran cantidad de métricas de distancia como Coseno, Jaccard y Levenshtein
- Emplea gráficos Hierarchical Navigable Small World (HNSW) para una búsqueda eficiente
- Optimizado tanto para vectores de datos densos como dispersos
- Contras:
- Curva de aprendizaje pronunciada debido a las amplias opciones algorítmicas
- Soporte y documentación limitados por parte de la comunidad
Detalles Técnicos: NMSLIB Vector Database (opens in a new tab) utiliza algoritmos avanzados como VP-trees, SW-graph y HNSW para la indexación. También admite búsquedas de Vecino Más Cercano Aproximado (ANN), lo que permite encontrar un equilibrio entre el rendimiento de la consulta y la precisión. La biblioteca está optimizada para un rendimiento de baja latencia y alto rendimiento, lo que la hace adecuada para aplicaciones en tiempo real.
NMSLIB Vector Database en GitHub: https://github.com/nmslib/nmslib (opens in a new tab)
Bases de Datos de Vectores Comerciales: ¿Vale la Pena?
4. Milvus
- Precio de Inicio: Gratis (Código Abierto)
- Valoración: 4.2/5
- Pros:
- Escalabilidad: Maneja hasta 100 mil millones de vectores con una latencia de sub-segundo.
- Métricas de Distancia: Admite métricas Euclidiana, Coseno y Jaccard. Admite tipos de índice como IVF_FLAT, IVF_PQ y HNSW.
- Contras:
- Tipos de Datos: No admite tipos de datos geoespaciales y de fecha y hora.
- Respaldo: No cuenta con un sistema de respaldo incorporado.
- Autenticación: Características de seguridad inconsistentes.
- Requiere componentes adicionales como MySQL o SQLite para el almacenamiento de metadatos.
- Soporte transaccional limitado, no apto para aplicaciones compatibles con ACID
Ventajas de Milvus: Milvus está diseñado para entornos nativos de la nube y admite la escalabilidad horizontal. Emplea un sistema de índices híbridos que combina métodos de indexación basados en árboles y basados en hash para una recuperación eficiente de datos. El sistema también admite poda de vectores y filtrado de consultas para condiciones de búsqueda más complejas.
Desventajas de Milvus: Milvus puede ser de código abierto y escalable, pero tiene limitaciones. No admite tipos de datos avanzados como geoespaciales y fecha y hora. Esta es una brecha significativa para aplicaciones en SIG y análisis de series temporales. También carece de un sistema de respaldo incorporado, lo cual es una falla crítica. La implementación inconsistente de características de seguridad como OAuth y LDAP es otra preocupación.

5. Pinecone
- Precio de Inicio: A partir de $30/mes
- Valoración: 3.9/5
- Pros:
- Servicio totalmente administrado
- Funciones de versionado y reversión de datos incorporadas
- Admite multi-inquilino
- Contras:
- Costo: El costo puede aumentar rápidamente para implementaciones más grandes, lo que puede ser exponencial con el tamaño de los datos.
- Características Limitadas: Sin uniones, transacciones o indexación avanzada.
- Documentación: Documentación técnica escasa.
- Personalización Limitada debido a la naturaleza administrada
Ventajas de Pinecone: Pinecone utiliza un algoritmo de indexación vectorial propietario que está optimizado tanto para vectores densos como dispersos. Utiliza una arquitectura distribuida y fragmentada para la escalabilidad y ofrece APIs RESTful para una integración fácil. Sin embargo, la falta de acceso al código fuente podría ser una limitación para aquellos que deseen extender o personalizar sus funcionalidades.
Desventajas de Pinecone: La naturaleza comercial de Pinecone tiene un alto costo, especialmente para conjuntos de datos grandes. Carece de soporte para uniones y transacciones, que son esenciales para operaciones de datos complejas. La escasa documentación técnica es una señal de advertencia que sugiere que el producto puede no cumplir con las expectativas de su publicidad.

6. Zilliz
- Precio de Inicio: Precios Personalizados
- Valoración: 3.7/5
- Pros:
- API REST: Integración fácil con aplicaciones existentes.
- Búsqueda de atributos: Operaciones básicas de búsqueda de atributos admitidas.
- Basado en la nube: Escalabilidad sin sobrecarga operativa.
- Desventajas:
- Costo: Precios exponenciales con el tamaño de los datos.
- Características limitadas: No hay uniones, transacciones o indexaciones avanzadas.
- Documentación: Documentación técnica escasa.
- Falta de tipos avanzados de datos como geoespaciales y fecha/hora.
Ventajas de Zilliz: Zilliz utiliza una variedad de algoritmos de indexación, incluidos IVF_SQ8 y NSG, y admite aceleración de GPU para un procesamiento de consultas más rápido. También ofrece un lenguaje de consulta similar a SQL, lo que permite condiciones de búsqueda más complejas. Sin embargo, la falta de transparencia en sus características de alta disponibilidad plantea preguntas sobre su idoneidad para aplicaciones críticas.
Desventajas de Zilliz: Zilliz carece de características esenciales como uniones y transacciones, lo que lo hace poco confiable para aplicaciones serias. La ausencia de características de alta disponibilidad, como la replicación de datos y la conmutación por error automática, conlleva un riesgo. El sistema de copia de seguridad es insuficiente, lo que requiere recursos adicionales para la recuperación de datos.

Cómo evaluar bases de datos vectoriales
Al evaluar bases de datos vectoriales, tenga en cuenta los siguientes aspectos técnicos:
- Conjunto de características: ¿Admite uniones, transacciones y tipos de datos avanzados?
- Escalabilidad: ¿Puede manejar eficientemente datos a gran escala?
- Costo: ¿Cómo varía el precio con las características ofrecidas?
- Soporte de la comunidad: ¿Existe soporte activo de la comunidad y una documentación extensa?
- Evaluación comparativa: Utilice benchmarks de rendimiento como consultas por segundo (QPS), latencia y rendimiento para realizar comparaciones.
Para obtener más detalles, puede ejecutar herramientas proporcionadas por este repositorio de GitHub (opens in a new tab) como benchmark para bases de datos vectoriales.
Las mejores alternativas de bases de datos vectoriales de código abierto en 2023
7. Qdrant: La elección de la comunidad
- Precio inicial: Gratis (código abierto)
- Valoración: 4.5/5
Pros:
- Local y basado en la nube: Ofrece ambas opciones de implementación, brindándole flexibilidad.
- Modo en memoria: Permite realizar pruebas sin iniciar un contenedor.
- Amigable con la migración: Experiencia en muchas migraciones desde otras herramientas.
Cons:
- Documentación: Podría beneficiarse de guías más completas.
- Tamaño de la comunidad: Comunidad más pequeña en comparación con otras opciones de código abierto.
- Conjunto de características: Aún en crecimiento y puede carecer de algunas funciones avanzadas.
Detalles técnicos: Qdrant (opens in a new tab) ofrece opciones locales y basadas en la nube, lo que lo convierte en una elección flexible. Sin embargo, tiene una comunidad más pequeña y podría beneficiarse de una documentación más completa. Aunque está ganando impulso, el conjunto de características aún está en crecimiento y puede carecer de algunas opciones avanzadas.
Enlace de Qdrant: https://qdrant.tech/ (opens in a new tab)

8. Cassandra/AstraDB: El rey de la escalabilidad
Precio inicial: Disponible una capa gratuita Valoración: 4.3/5
Pros:
- Escalabilidad: Reconocido por manejar un gran flujo de datos sin colapsar.
- Local y basado en la nube: Ambas opciones de implementación están disponibles.
- Reconocimiento en la industria: Ha mantenido su posición en la industria durante años.
Cons:
- Complejidad: Mayor curva de aprendizaje para nuevos usuarios.
- Costo: La capa gratuita tiene limitaciones y los precios pueden aumentar.
- Soporte vectorial: No diseñado originalmente para datos vectoriales, por lo que puede carecer de algunas funcionalidades.
Detalles técnicos: Apache Cassandra (opens in a new tab)/DataStax AstraDB (opens in a new tab) es excelente para la escalabilidad, pero tiene una curva de aprendizaje pronunciada. Si bien ofrece una capa gratuita, rápidamente se alcanzan las limitaciones, lo que conduce a costos ascendentes. Además, no fue diseñado originalmente para datos vectoriales, por lo que puede carecer de algunas características especializadas.
Apache Cassandra: https://cassandra.apache.org (opens in a new tab) DataStax AstraDB: https://www.datastax.com/products/datastax-astra (opens in a new tab)

9. MyScale DB: La potencia de SQL como alternativa a Pinecone
Precio inicial: Generosa capa gratuita Valoración: 4.1/5
Pros:
- Soporte SQL: Soporte completo y ampliado de SQL para todas las operaciones de datos.
- Velocidad: Arquitectura de base de datos OLAP nativa en la nube para operaciones rápidas.
- Datos estructurados y vectorizados: Gestiona ambos en una sola base de datos.
Cons:
- Nuevo competidor: Relativamente nuevo y puede carecer de soporte de la comunidad.
- Documentación: Podría beneficiarse de guías técnicas adicionales.
- Complejidad: Se requieren conocimientos de SQL, lo que puede no ser adecuado para todos los usuarios.
Detalles técnicos: MyScale DB (opens in a new tab) ofrece una generosa capa gratuita y soporte completo de SQL, lo que lo convierte en una opción sólida para aquellos familiarizados con SQL. Sin embargo, al ser un producto relativamente nuevo, puede carecer de un amplio soporte de la comunidad y podría beneficiarse de una documentación técnica más completa.
MyScale DB: https://myscale.com (opens in a new tab)
10. SPTAG (Space Partition Tree and Graph)
- Precio inicial: Gratis (código abierto)
- Valoración: 4.3/5
- Pros:
- Desarrollado por Microsoft, lo que garantiza un nivel de confiabilidad.
- Capacidades de búsqueda k-NN de alta velocidad.
- Optimizado para bases de datos a gran escala con miles de millones de vectores.
- Cons:
- Soporte de la comunidad limitado.
- La documentación no es tan extensa como otras opciones de código abierto. Detalles técnicos: SPTAG (opens in a new tab) utiliza árboles KD y de bolas para la indexación, lo que permite búsquedas de k-NN de alta velocidad. Está optimizado para bases de datos a gran escala y puede manejar eficientemente miles de millones de vectores. El algoritmo también soporta búsqueda multi-threaded y procesamiento de consultas en lote.
SPTAG GitHub: https://github.com/microsoft/SPTAG (opens in a new tab)
Preguntas frecuentes
¿Cuáles son las principales bases de datos de vectores?
Las principales bases de datos de vectores hasta el año 2023 incluyen Faiss, Annoy, NMSLIB, Milvus, Pinecone, Zilliz, Elasticsearch, Weaviate, Jina y SPTAG.
¿Existe alguna base de datos de vectores gratuita?
Sí, existen varias bases de datos de vectores gratuitas y de código abierto disponibles, como Faiss, Annoy, NMSLIB, Milvus, Weaviate, Jina y SPTAG.
¿Es Pinecone la mejor base de datos de vectores?
Si bien Pinecone ofrece un servicio completamente gestionado y es fácil de usar, si es la "mejor" depende de tus necesidades específicas. No es de código abierto y puede ser costoso para implementaciones más grandes.
¿Cómo elijo una base de datos de vectores?
La elección de una base de datos de vectores depende de varios factores, como el tipo de datos con los que estás trabajando, la escala de tu proyecto y tu presupuesto. Opciones de código abierto como Faiss y Annoy son excelentes para aquellos que quieren tener más control y personalización, mientras que servicios gestionados como Pinecone pueden ser más adecuados para aquellos que buscan facilidad de uso.
Conclusión
Las bases de datos de vectores son una herramienta esencial para manejar datos complejos y de alta dimensión. Si bien ofrecen numerosas ventajas como búsquedas eficientes de similitud y escalabilidad, también tienen sus propias limitaciones. Opciones de código abierto como Faiss y Annoy ofrecen un rendimiento y flexibilidad excelentes, pero pueden requerir un período de aprendizaje más largo. Por otro lado, opciones comerciales como Pinecone ofrecen facilidad de uso pero pueden ser costosas. Por lo tanto, es crucial evaluar cuidadosamente los pros y los contras para elegir la base de datos de vectores que mejor se adapte a tus necesidades.
¿Quieres conocer las últimas noticias de LLM? ¡Visita el último leaderboard de LLM!
