Cómo Groq AI hace que las consultas de LLM sean x10 más rápidas

Groq, una empresa de soluciones de inteligencia artificial generativa, está redefiniendo el panorama de la inferencia de grandes modelos de lenguaje (LLM) con su revolucionaria Unidad de Procesamiento del Lenguaje (LPU). Este acelerador diseñado específicamente está diseñado para superar las limitaciones de las arquitecturas tradicionales de CPU y GPU, ofreciendo una velocidad y eficiencia sin igual en el procesamiento de LLM.
¿Quieres conocer las últimas noticias sobre LLM? ¡Visita el último ranking de LLM!

La arquitectura LPU: Un enfoque profundo
En el núcleo de la arquitectura LPU de Groq se encuentra un diseño de núcleo único que prioriza el rendimiento secuencial. Este enfoque permite que la LPU logre una densidad de cálculo excepcional, con un rendimiento máximo de 1 PetaFLOP/s en un solo chip. La arquitectura única de la LPU de Groq también elimina los cuellos de botella de memoria externa al incorporar 220 MB de SRAM en el chip, lo que proporciona un asombroso ancho de banda de memoria de 1.5 TB/s.
Las capacidades de red síncronas de la LPU permiten una escalabilidad perfecta en implementaciones a gran escala. Con un ancho de banda bidireccional de 1.6 TB/s por LPU, la tecnología de Groq puede manejar eficientemente las transferencias masivas de datos requeridas para la inferencia de LLM. Además, la LPU admite una amplia gama de niveles de precisión, desde FP32 hasta INT4, lo que permite una alta precisión incluso en configuraciones de precisión más baja.
Evaluación del rendimiento de Groq
El Motor de Inferencia LPU de Groq ha superado consistentemente a los gigantes de la industria en varias evaluaciones. En las pruebas internas realizadas en el modelo Llama-2 70B de Meta AI, Groq logró una impresionante velocidad de 300 tokens por segundo por usuario. Esto representa un avance significativo en la velocidad de inferencia de LLM, superando el rendimiento de los sistemas basados en GPU tradicionales.
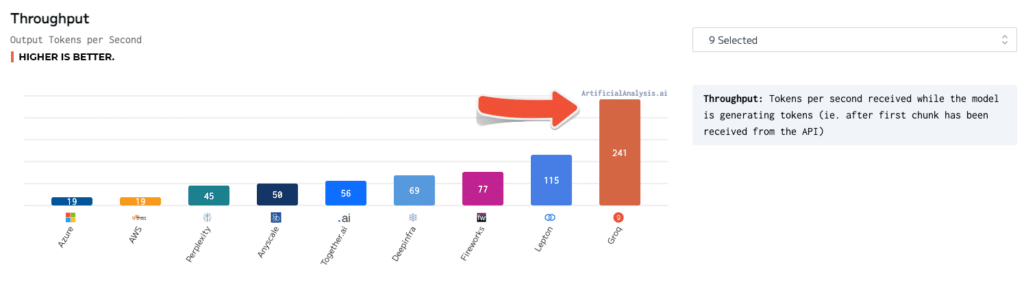
Las evaluaciones independientes han validado aún más la superioridad de Groq. En pruebas realizadas por ArtificialAnalysis.ai, la API de Llama 2 Chat (70B) de Groq logró un rendimiento de 241 tokens por segundo, más del doble de la velocidad de otros proveedores de alojamiento. Groq también destacó en otros indicadores clave de rendimiento, como latencia vs. rendimiento, tiempo total de respuesta y variación de rendimiento.
Para poner estos números en perspectiva, consideremos un escenario en el que un usuario interactúa con un chatbot impulsado por IA. Con el Motor de Inferencia LPU de Groq, el chatbot puede generar respuestas a una velocidad de 300 tokens por segundo, lo que permite conversaciones casi instantáneas. En comparación, un sistema basado en GPU puede lograr solo 50-100 tokens por segundo, lo que resulta en retrasos perceptibles y una experiencia de usuario menos atractiva.
Groq vs. otras tecnologías de IA

En comparación con las GPU de NVIDIA, la LPU de Groq demuestra una clara ventaja en el rendimiento de INT8, que es crucial para la inferencia de alta velocidad de LLM. En una evaluación comparativa de la LPU con la GPU A100 de NVIDIA, la LPU logró una mejora de velocidad de 3.5x en el modelo Llama-2 70B, procesando 300 tokens por segundo en comparación con los 85 tokens por segundo de la A100.
La tecnología de Groq también se destaca frente a otros modelos de IA como ChatGPT y Gemini de Google. Si bien no hay números de rendimiento específicos disponibles públicamente para estos modelos, la velocidad y eficiencia demostrada por Groq sugieren que tiene el potencial de superarlos en aplicaciones del mundo real.
Uso de Groq AI
Groq ofrece una amplia suite de herramientas y servicios para facilitar la implementación y utilización de su tecnología LPU. La suite GroqWare, que incluye el Compilador Groq, proporciona una experiencia de un solo clic para poner en marcha rápidamente los modelos. Aquí tienes un ejemplo de cómo compilar y ejecutar un modelo usando el Compilador Groq:
# Compilar el modelo
groq compile model.onnx -o model.groq
# Ejecutar el modelo en la LPU
groq run model.groq -i input.bin -o output.binPara aquellos que buscan una mayor personalización, Groq también permite la codificación manual de la arquitectura Groq, lo que permite el desarrollo de aplicaciones personalizadas y la optimización máxima del rendimiento. Aquí tienes un ejemplo de un ensamblador codificado manualmente para una multiplicación de matrices simple:
; Multiplicación de matrices en la LPU de Groq
; Se asume que las matrices A y B están cargadas en la memoria
; Cargar dimensiones de las matrices
ld r0, [n]
ld r1, [m]
ld r2, [k]
; Inicializar la matriz de resultados C
mov r3, 0
; Bucle externo sobre las filas de A
mov r4, 0
loop_i:
; Bucle interno sobre las columnas de B
mov r5, 0
loop_j:
; Acumular el producto escalar
mov r6, 0
mov r7, 0
loop_k:
ld r8, [A + r4 * m + r7]
ld r9, [B + r7 * k + r5]
mul r10, r8, r9
add r6, r6, r10
add r7, r7, 1
cmp r7, r2
jlt loop_k
; Almacenar el resultado en C
st [C + r4 * k + r5], r6
add r5, r5, 1
cmp r5, r2
jlt loop_j
add r4, r4, 1
cmp r4, r0
jlt loop_iLos desarrolladores e investigadores también pueden aprovechar la potente tecnología de Groq a través de la API de Groq, que proporciona acceso a capacidades de inferencia en tiempo real. Aquí tienes un ejemplo de cómo utilizar la API de Groq para generar texto utilizando el modelo Llama-2 70B:
import groq
# Inicializar el cliente de Groq
client = groq.Client(api_key="tu_clave_de_api")
# Configurar el modelo y los parámetros
modelo = "llama-2-70b"
prompt = "Érase una vez, en un lugar lejano..."
max_tokens = 100
# Generar texto
respuesta = client.generate(model=modelo, prompt=prompt, max_tokens=max_tokens)
# Imprimir el texto generado
print(respuesta.text)Aplicaciones potenciales e impacto
Los tiempos de respuesta casi instantáneos habilitados por el Motor de Inferencia LPU de Groq están desbloqueando nuevas posibilidades en diversas industrias. En el sector financiero, la tecnología de Groq puede ser aprovechada para la detección de fraudes en tiempo real y la evaluación de riesgos. Al procesar grandes cantidades de datos de transacciones e identificar anomalías en milisegundos, las instituciones financieras pueden prevenir actividades fraudulentas y proteger los activos de sus clientes.
En el ámbito de la salud, la LPU de Groq puede revolucionar la atención médica al permitir el análisis en tiempo real de datos médicos. Desde el procesamiento de imágenes médicas hasta el análisis de registros electrónicos de salud, la tecnología de Groq puede ayudar a los profesionales de la salud a realizar diagnósticos rápidos y precisos, mejorando así los resultados de los pacientes.
Los vehículos autónomos también pueden beneficiarse enormemente de las capacidades de inferencia de alta velocidad de Groq. Al procesar datos de sensores y tomar decisiones en fracciones de segundo, los sistemas de IA impulsados por Groq pueden mejorar la seguridad y confiabilidad de los coches autónomos, allanando el camino para un futuro de transporte inteligente.
Conclusión
El Motor de Inferencia LPU de Groq representa un avance significativo en el campo de la aceleración de IA. Con su arquitectura innovadora, impresionantes puntos de referencia y completa suite de herramientas y servicios, Groq capacita a los desarrolladores y organizaciones para empujar los límites de lo posible con los modelos de lenguaje grandes.
A medida que la demanda de inferencia de IA en tiempo real sigue creciendo, Groq está bien posicionado para liderar el avance al permitir la próxima generación de soluciones impulsadas por IA. Desde chatbots y asistentes virtuales hasta sistemas autónomos y más allá, las aplicaciones potenciales de la tecnología de Groq son vastas y transformadoras.
Con su compromiso de democratizar el acceso a la IA y fomentar la innovación, Groq no solo está revolucionando el panorama técnico, sino también dando forma al futuro de cómo interactuamos y nos beneficiamos de la inteligencia artificial. A medida que nos encontramos en el umbral de una era impulsada por la IA, la tecnología innovadora de Groq está preparada para ser un catalizador de avances y descubrimientos sin precedentes en los próximos años.
¿Quieres conocer las últimas noticias de LLM? ¡Echa un vistazo a la última tabla de clasificación de LLM!