Cómo ejecutar modelos de Mistral localmente: una guía completa

En el mundo en constante evolución de la inteligencia artificial, Mistral AI ha surgido como un faro de innovación, explorando nuevos territorios en el ámbito de los modelos de lenguaje grandes (LLMs). Con la introducción de sus modelos revolucionarios, Mistral AI no solo avanza en la frontera del aprendizaje automático, sino que también democratiza el acceso a tecnología de vanguardia. Esta guía tiene como objetivo aclarar las complejidades de las ofertas de Mistral AI y proporcionar un mapa completo para aprovechar sus capacidades de forma local.
¿Qué son estos modelos de Mistral AI?
Mistral AI ha revelado una serie de modelos de lenguaje que no son solo iteraciones, sino saltos en lingüística computacional. En el corazón de esta serie se encuentran Mistral 7B y Mixtral 8x7B, cada uno diseñado para satisfacer necesidades y capacidades computacionales diversas.
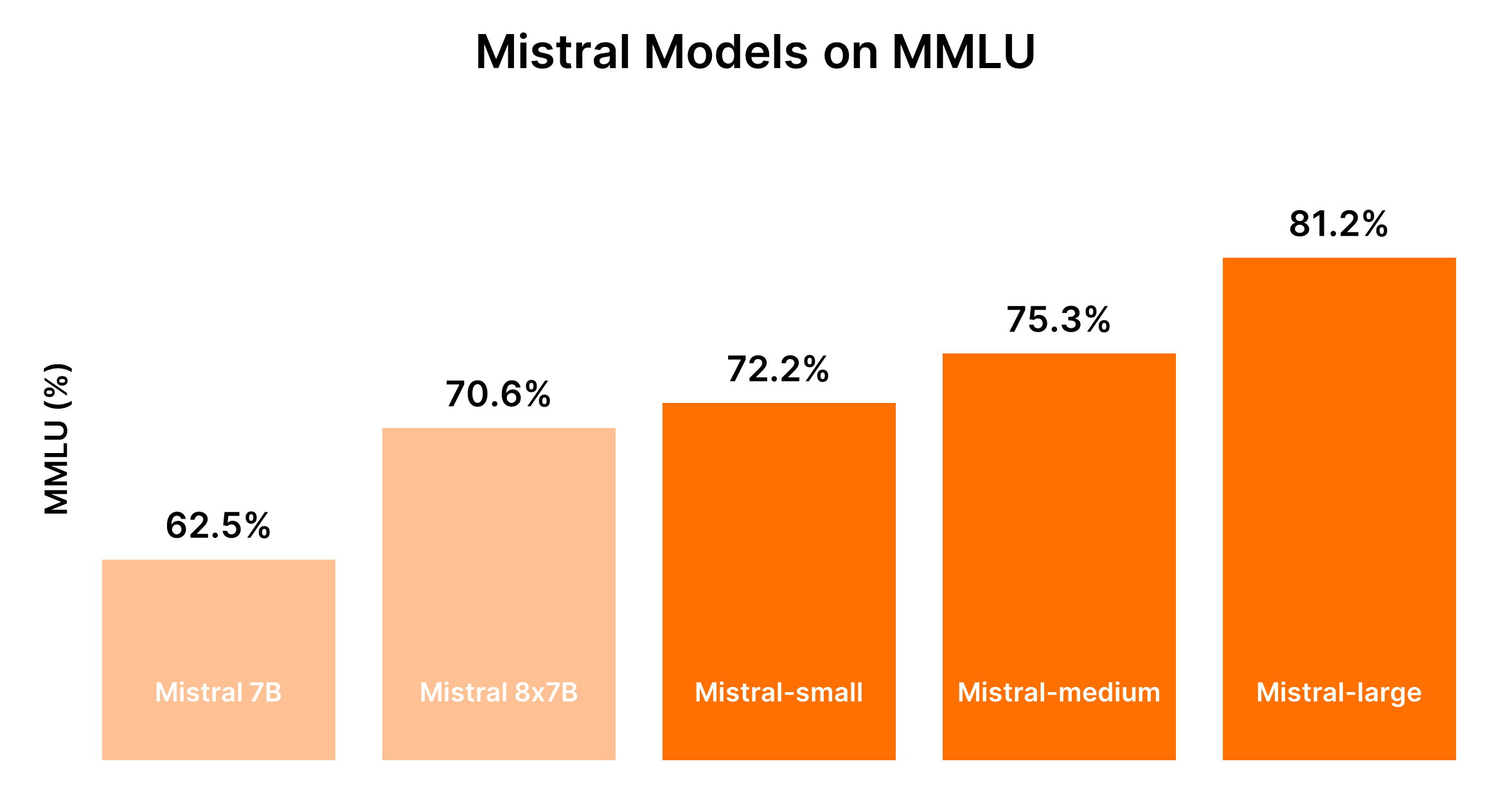
Comparación de modelos de Mistral AI (Mistral 7B vs Mistral 8x7b vs Mistral Small vs Mistral Medium vs Mistral Large)
Entendido. Basándonos en la entrada proporcionada y centrándonos en crear tablas en formato markdown para una comparación directa, estructuraremos el análisis comparativo de los modelos de Mistral AI.
Análisis comparativo de los modelos de Mistral AI
Mistral AI ofrece una variedad de modelos, cada uno adaptado para diferentes casos de uso, desde tareas bulk simples hasta capacidades de razonamiento complejo. A continuación se presentan análisis comparativos y resultados de rendimiento en formato markdown para una comprensión clara.
Descripción general del modelo y casos de uso
| Modelo ID | Alias | Casos de Uso |
|---|---|---|
| open-mistral-7b | mistral-tiny-2312 | Tareas bulk simples, como clasificación, soporte al cliente o generación de texto |
| open-mixtral-8x7b | mistral-small-2312 | Similar a open-mistral-7b, adecuado para tareas bulk simples |
| mistral-small-latest | mistral-small-2402 | Tareas ligeramente avanzadas que requieren razonamiento mínimo |
| mistral-medium-latest | mistral-medium-2312 | Tareas intermedias como extracción de datos, resumen de documentos, redacción de correos electrónicos |
| mistral-large-latest | mistral-large-2402 | Tareas complejas que requieren capacidades de razonamiento elevadas, como generación de texto sintético, generación de código |
Rendimiento y compensación de costos
El rendimiento de los modelos de Mistral generalmente es proporcional a su tamaño, siendo los modelos más grandes los que ofrecen capacidades mejoradas pero a un mayor costo. La siguiente tabla resume las clasificaciones de rendimiento basadas en el benchmark MMLU y consideraciones generales de costo.
| Modelo | Clasificación de rendimiento | Consideración de costos |
|---|---|---|
| Mistral 7B (tiny-2312) | 5to | La más rentable para tareas simples |
| Mixtral 8x7B (small-2312) | 4to | Rentable para tareas simples en bulk |
| Mistral Small (small-2402) | 3ro | Costo moderado, adecuado para tareas con razonamiento mínimo |
| Mistral Medium (medium-2312) | 2do | Costo más alto, rendimiento equilibrado para tareas intermedias |
| Mistral Large (large-2402) | 1ro | Costo más alto, rendimiento sin igual para tareas complejas |
Dado el carácter dinámico del rendimiento de LLM y los costos asociados, se recomienda consultar los benchmarks y precios actuales para una comparación más precisa. Plataformas como el Chatbot Arena Leaderboard (opens in a new tab) de Hugging Face y Artificial Analysis (opens in a new tab) pueden proporcionar información valiosa sobre benchmarks y rendimiento actualizados.
Orientación para la toma de decisiones: ¿Qué modelo de Mistral AI debes elegir?
La elección del modelo adecuado depende de equilibrar las necesidades de rendimiento con las restricciones de costos, teniendo en cuenta la complejidad de las tareas que tu aplicación pretende manejar.
- Para tareas simples: Comienza con Mistral Small o Mistral 7B para ser rentable.
- Para tareas intermedias o complejas: Evalúa si el rendimiento mejorado de Mistral Medium o Mistral Large justifica el gasto adicional según las necesidades específicas de tu aplicación.
Esta comparación estructurada tiene como objetivo facilitar la toma de decisiones informadas al seleccionar entre las ofertas de modelos de Mistral AI, asegurando que el modelo elegido se alinee tanto con los requisitos funcionales como con las limitaciones presupuestarias de tu proyecto.

Parte 1. Cómo ejecutar Mistral localmente con Ollama (la forma fácil)
Ejecutar los modelos de Mistral AI localmente con Ollama proporciona una forma accesible de aprovechar el poder de estos LLMs avanzados directamente en tu máquina. Este enfoque es ideal para desarrolladores, investigadores y entusiastas que deseen experimentar con análisis de texto impulsados por IA, generación de texto y más, sin depender de servicios en la nube. Aquí tienes una guía concisa para comenzar:
Paso 1: Descargar Ollama
- Visita la página de descarga de Ollama y elige la versión adecuada para tu sistema operativo. Para usuarios de macOS, descargarás un archivo
.dmg. - Instala Ollama arrastrando el archivo descargado a tu directorio
/Applications.
Paso 2: Explora los comandos de Ollama
Abre tu terminal e ingresa ollama para ver la lista de comandos disponibles. Verás opciones como serve, create, show, run, pull y más.
Paso 3: Instalar Mistral AI
Para instalar un modelo de Mistral AI, primero debes encontrar el modelo que deseas instalar. Si estás interesado en la versión Mistral:instruct, puedes instalarlo directamente o descargarlo si aún no está en tu máquina.
- Para ejecutar directamente (y descargar si es necesario):
ollama run mistral:instruct - Para pre-descargar el modelo:
ollama pull mistral:instruct
Paso 4: Interactuar con Mistral AI
Una vez instalado el modelo, puedes interactuar con él en modo interactivo o pasando inputs directamente.
-
Para modo interactivo:
ollama run mistral --verboseLuego sigue las indicaciones para ingresar tus consultas.
-
Para modo no interactivo (input directo): Supongamos que tienes un artículo que deseas resumir guardado en
bbc.txt. Puedes pasar el contenido del artículo directamente a Mistral para que lo resuma:ollama run mistral --verbose "Por favor, ¿puedes resumir este artículo: $(cat bbc.txt)"Reemplaza
"Por favor, ¿puedes resumir este artículo: $(cat bbc.txt)"con cualquier indicación relevante para tu tarea.
Análisis de la Salida de Ejemplo
Tu terminal mostrará la salida del modelo, incluyendo el resumen o la respuesta a tu consulta. Es fascinante ver cómo Mistral procesa y comprende consultas complejas, incluso ofreciendo correcciones cuando se le solicita sobre inexactitudes.
Ejecución de Mistral AI desde la API HTTP
Ollama también admite una API HTTP, lo que permite la interacción programática con los modelos.
- Ejemplo de solicitud
curl:curl -X POST http://localhost:11434/api/generate -d '{ "model": "mistral", "prompt": "¿Cuál es el sentimiento de esta oración: La situación en torno al video arbitraje asistido está en un punto de crisis." }'
Este método devuelve respuestas en formato JSON que se pueden analizar programáticamente, ofreciendo una forma flexible de integrar las capacidades de Mistral AI en aplicaciones.
Ejecutar Mistral AI con Ollama en una máquina local abre vastas posibilidades para aprovechar la IA en proyectos personales, desarrollo e investigación. La facilidad de instalación y uso, combinada con el poder de los LLMs de Mistral, hace que esta sea una opción atractiva para cualquier persona interesada en explorar las fronteras de la tecnología de IA.
Parte 2. Cómo ejecutar Mistral 7B Localmente en Windows
Mistral 7B se puede acceder a través de múltiples plataformas, incluyendo HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart y Baseten. La funcionalidad "Modelos" de Kaggle también ofrece un enfoque simplificado, que te permite comenzar con inferencia o ajuste fino en cuestión de minutos sin necesidad de descargar el modelo o el conjunto de datos.
Preliminares para acceder a Mistral 7B
Antes de empezar, asegúrate de que tu entorno esté actualizado para evitar errores comunes como KeyError: 'mistral':
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytesImplementación de Quantización de 4 bits
Para acelerar la carga del modelo y reducir el uso de memoria, se utiliza la quantización de 4 bits:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Carga de Mistral 7B en Cuadernos de Kaggle
Cuadernos de Kaggle facilita la adición de Mistral 7B a través de una interacción simple de interfaz de usuario. Después de seleccionar la variación y versión del modelo apropiado, puedes cargar fácilmente el modelo y el tokenizer para su uso:
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)El uso de la función pipeline simplifica el proceso de generación de respuestas basadas en la indicación dada.
Inferencia de Ejemplo
Configurando una indicación e invocando el pipeline, Mistral 7B genera respuestas coherentes y contextualmente relevantes, ilustrando su comprensión de conceptos complejos como la regularización en el aprendizaje automático:
indicacion = "Como científico de datos, ¿puedes explicar el concepto de regularización en el aprendizaje automático?"
secuencias = pipe(
indicacion,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(secuencias[0]['generated_text'])Cómo hacer Ajuste Fino a Mistral 7B
El proceso de ajuste fino implica actualizar bibliotecas, configurar módulos y adaptar el modelo a tu conjunto de datos. Usando Cuadernos de Kaggle, las claves de API para servicios como Hugging Face y Weights & Biases se almacenan y acceden de forma segura. Esta sección detalla los pasos y configuraciones esenciales para un ajuste fino efectivo, asegurando que maximices el potencial del modelo en tu conjunto de datos específico.
- Actualizar e Instalar Bibliotecas Necesarias: Asegura la compatibilidad y el acceso a las últimas funciones para el ajuste fino.
- Cargar Módulos y Configurar Acceso a la API: Facilita la interacción con servicios externos y repositorios de modelos.
- Configurar y Entrenar el Modelo: Adapta el modelo para ajustarse a las particularidades de tu conjunto de datos, aprovechando el poder de PEFT (Parameter-efficient Fine-tuning) para un entrenamiento eficiente.
- Evaluar y Guardar Tu Modelo: Evalúa el rendimiento del modelo y guarda el ajuste fino.
La guía detallada tiene como objetivo proporcionarte las herramientas y el conocimiento para aprovechar las capacidades del modelo de Mistral 7B de manera efectiva. Desde el acceso al modelo hasta el ajuste fino en un conjunto de datos específico, cada paso está diseñado para mejorar las capacidades de procesamiento del lenguaje natural de tu proyecto.
Parte 3. Cómo ejecutar Mixtral 8x7b Localmente con LlamaIndex y Ollama
Por favor, proporcione la traducción al español de este archivo de marcado. Si hay un "frontmatter", asegúrese de traducir el parámetro "language" al es correspondiente. Para el código, no traduzca el código, solo traduzca los comentarios. No traduzca el contenido del ejemplo de muestra. Aquí está el archivo: 
El potente Mistral AI europeo presentó recientemente su modelo "mixture of experts" llamado Mixtral 8x7b. Este modelo, que cuenta con ocho expertos cada uno entrenado con 7 mil millones de parámetros, ha despertado un gran interés por igualar o incluso superar el rendimiento de GPT-3.5 y Llama2 70b en varias pruebas.
Paso 1: Instalar Ollama
Ollama, una herramienta de código abierto disponible para MacOS, Linux y Windows (a través de Windows Subsystem For Linux), simplifica el proceso de ejecución de modelos locales. Con Ollama, puedes iniciar Mixtral con un solo comando:
ollama run mixtralEste comando descarga el modelo (lo cual puede llevar algo de tiempo) y requiere una cantidad significativa de RAM (48 GB) para funcionar sin problemas. Para sistemas con especificaciones más bajas, Mistral 7b es una alternativa viable.
Paso 2: Instalar dependencias
Para integrar Mixtral con LlamaIndex, necesitarás varias dependencias. Instálalas mediante pip:
pip install llama-index qdrant_client torch transformersPaso 3: Prueba de humo
Verifica la configuración con una "prueba de humo" utilizando Ollama y LlamaIndex:
from llama_index.llms import Ollama
llm = Ollama(model="mixtral")
response = llm.complete("¿Quién es Laurie Voss?")
print(response)Paso 4: Cargar datos e indexarlos
Preparación de datos:
Utiliza cualquier conjunto de datos para este ejemplo; aquí, utilizamos una colección de tweets. Qdrant, una base de datos de vectores de código abierto, almacena los datos. Los siguientes fragmentos de código muestran el proceso de carga e indexación de los datos con Qdrant y LlamaIndex:
from pathlib import Path
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext, download_loader
from llama_index.llms import Ollama
from llama_index.storage.storage_context import StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Inicialización de Qdrant y carga de tweets
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
## Configuración del contexto de servicio con Mixtral y embebido local
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## Indexación y consulta de datos
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("¿Qué piensa el autor sobre Star Trek? Proporcione detalles.")
print(response)Verificación del índice:
El último paso implica utilizar el índice preconstruido para responder a consultas. Este proceso no requiere volver a cargar los datos, ya que están indexados en Qdrant:
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import Ollama
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Cargar el vector store y Mixtral
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## Cargar el índice y realizar una consulta
index = VectorStoreIndex.from_vector_store(vector_store=vector_store, service_context=service_context)
query_engine = index.as_query_engine(similarity_top_k=20)
response = query_engine.query("¿Le gusta al autor SQL? Proporcione detalles.")
print(response)Parte 4. Cómo ejecutar Mistral 8x7B localmente con llama.cpp
La ejecución de modelos de Mistral AI localmente se ha vuelto más accesible gracias a herramientas como llama.cpp y el complemento llm-llama-cpp. El lanzamiento del modelo Mixtral 8x7B, un modelo de mezcla de expertos (SMoE) de alta calidad y disperso, marcó un avance significativo en el panorama de IA con licencia abierta. Aquí tienes una breve guía sobre cómo ejecutar Mixtral 8x7B localmente utilizando llama.cpp y las herramientas relacionadas.
Instalación y ejecución local de Mixtral 8x7B
-
Instalar la herramienta LLM: Primero, asegúrate de tener LLM instalado en tu máquina. LLM actúa como puente para la ejecución de varios modelos de IA localmente.
pipx install llm -
Instalar el complemento
llm-llama-cpp: Este complemento es necesario para ejecutar Mixtral y otros modelos compatibles conllama.cpp.llm install llm-llama-cpp -
Configurar
llama-cpp-python: Para las Mac con Apple Silicon, la configuración puede incluir la activación del soporte para Metal:CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 llm install llama-cpp-pythonLas instrucciones detalladas pueden variar según tu plataforma, así que consulta el README de
llm-llama-cpppara obtener orientación. -
Descargar el modelo Mixtral: Necesitarás el archivo GGUF para Mixtral 8x7B. Elige un tamaño de archivo adecuado para tus necesidades; por ejemplo, la variante de 36 GB para la versión Instruct del modelo:
curl -LO 'https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf?download=true' -
Ejecutar el modelo: Con el modelo descargado, puedes ejecutar Mixtral 8x7B utilizando la herramienta
llm:llm -m gguf -o path mixtral-8x7b-instruct-v0.1.Q6_K.gguf '[INST] Escribe una función de Python que descargue un archivo desde una URL[/INST]'Este comando especifica usar el modelo GGUF con la opción
-m ggufy proporciona la ruta al archivo GGUF descargado con-o path.
Consideraciones adicionales
-
Modo interactivo: Si deseas interactuar con el modelo de manera más conversacional, considera ejecutar
llmen modo interactivo. Este modo permite un diálogo de ida y vuelta con el modelo de IA. -
Construcción de la consulta: El prefijo
[INST]en el ejemplo de comando anterior indica la naturaleza basada en instrucciones de la consulta, adecuada para las versiones Instruct de los modelos. Personaliza tus consultas para que se ajusten al formato de entrada esperado por el modelo para obtener resultados óptimos.
Parte 5. Ejecutar Mistral 7B Localmente en un iPhone

Ejecutar el modelo Mistral 7B en un iPhone implica algunos pasos técnicos, ya que los dispositivos iOS suelen tener más restricciones que los entornos de escritorio. Aquí tienes una guía paso a paso simplificada:
-
Requisitos previos:
- Asegúrate de que tu iPhone esté ejecutando la última versión de iOS para evitar problemas de compatibilidad.
- Instala un entorno de desarrollo de aplicaciones iOS, como Xcode, en tu Mac, para compilar y ejecutar la aplicación personalizada que utilizará Mistral 7B.
-
Elegir la opción de ejecución: Para implementar en iPhone,
llm-llama-cpppodría ser la más adecuada debido a su compatibilidad con entornos de C++, que se pueden integrar en proyectos de iOS. -
Configurar el entorno de desarrollo:
- Descarga el archivo GGUF para
llm-llama-cppdesde el repositorio oficial. - Abre Xcode y crea un nuevo proyecto iOS.
- Integra la biblioteca
llm-llama-cppen tu proyecto. Esto podría requerir dependencias adicionales, así que consulta la documentación.
- Descarga el archivo GGUF para
-
Codificación:
- Escribe código Swift o Objective-C para interactuar con la biblioteca de C++. Esto podría implicar crear un encabezado de puente para usar código de C++ en proyectos Swift.
- Inicializa el modelo dentro de tu aplicación, manejando cualquier configuración requerida, como la ruta del modelo y los parámetros.
-
Pruebas e implementación:
- Prueba la aplicación en tu iPhone, asegurándote de que el modelo se ejecute sin problemas y funcione como se espera.
- Implementa la aplicación a través de Xcode, ya sea para uso personal o, si cumple con las pautas de Apple, envíala a la App Store.
Parte 6. Ejecutar Mistral AI Localmente con la API

Para ejecutar Mistral AI localmente utilizando su API, sigue estos pasos, asegurándote de tener un entorno capaz de realizar solicitudes HTTP, como Postman para pruebas o lenguajes de programación con capacidades de solicitudes HTTP (por ejemplo, Python con la biblioteca requests).
Requisitos previos:
- Obtener una clave de API (opens in a new tab) al registrarte para obtener acceso a la API de Mistral.
- Asegúrate de que tu entorno local tenga acceso a Internet para comunicarse con los servidores de la API de Mistral.
- Instala el complemento
llm-mistralpara tu entorno local. Esto podría implicar agregarlo a las dependencias de tu proyecto en caso de un proyecto de programación. - Configura tu proyecto o herramienta para utilizar tu clave de API de Mistral. Por lo general, esto implica establecer la clave en un archivo de configuración o como una variable de entorno.
Crear Completados de Chat
Este punto final de la API te permite generar completados de texto basados en un prompt. La solicitud requiere especificar el modelo, los mensajes (prompts) y varios parámetros para controlar el proceso de generación como la temperatura, top_p y max_tokens.
Ejemplo de código Python para Completados de Chat:
import requests
url = "https://api.mistral.ai/chat/completions"
payload = {
"model": "mistral-small-latest",
"messages": [{"role": "user", "content": "¿Cómo empiezo a usar Mistral AI?"}],
"temperature": 0.7,
"top_p": 1,
"max_tokens": 512,
"stream": False,
"safe_prompt": False,
"random_seed": 1337
}
headers = {
"Authorization": "Bearer TU_CLAVE_DE_API",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Error:", response.text)Crear Embeddings
El punto final de la API de embeddings se utiliza para convertir texto en vectores de alta dimensión. Esto puede ser útil para tareas como búsqueda semántica, agrupamiento o encontrar textos similares.
Ejemplo de código Python para Crear Embeddings:
import requests
url = "https://api.mistral.ai/embeddings"
payload = {
"model": "mistral-embed",
"input": ["Hola", "mundo"],
"encoding_format": "float"
}
headers = {
"Authorization": "Bearer TU_CLAVE_DE_API",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Error:", response.text)Listar Modelos Disponibles
Esta llamada a la API es sencilla y te permite obtener una lista de todos los modelos accesibles para ti. Esto puede ayudar a seleccionar dinámicamente modelos para diversas tareas en función de sus capacidades o tus requisitos.
Ejemplo de código Python para Listar Modelos Disponibles:
import requests
url = "https://api.mistral.ai/models"
headers = {
"Authorization": "Bearer TU_CLAVE_DE_API"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Error:", response.text)Estos ejemplos proporcionan una base para interactuar con la API de Mistral AI, lo que permite la creación de aplicaciones sofisticadas impulsadas por IA. Recuerda reemplazar "TU_CLAVE_DE_API" con tu API key real.
Estos pasos ofrecen un esquema básico para integrar y utilizar el modelo de IA de Mistral 7B localmente en un iPhone y a través de su API. Pueden ser necesarias adaptaciones según los requisitos específicos del proyecto o las actualizaciones de la plataforma.