Introducción a Jamba, el innovador modelo SSM-Transformer

AI21 Labs se enorgullece en presentar Jamba, el primer modelo de grado de producción basado en la revolucionaria arquitectura Mamba. Al integrar de manera fluida la tecnología de Espacio de Estado Estructurado de Mamba (SSM, por sus siglas en inglés) con elementos de la arquitectura tradicional de Transformer, Jamba supera las limitaciones de los modelos SSM puros, brindando un rendimiento y eficiencia excepcionales.
Con su impresionante ventana de contexto de 256K y notables ganancias de rendimiento, Jamba está listo para transformar el panorama de la IA, abriendo nuevas posibilidades para investigadores, desarrolladores y empresas por igual. Jamba ya ha demostrado resultados sobresalientes en una amplia gama de referencias, igualando o superando a otros modelos de última generación en su clase de tamaño.
TLDR: Jamba no tiene mecanismos de moderación de seguridad y utiliza la licencia de código abierto Apache-2.0.

Características clave de Jamba
- Primer modelo basado en Mamba de grado de producción: Jamba pionero en el uso de la arquitectura híbrida SSM-Transformer a escala y calidad de grado de producción.
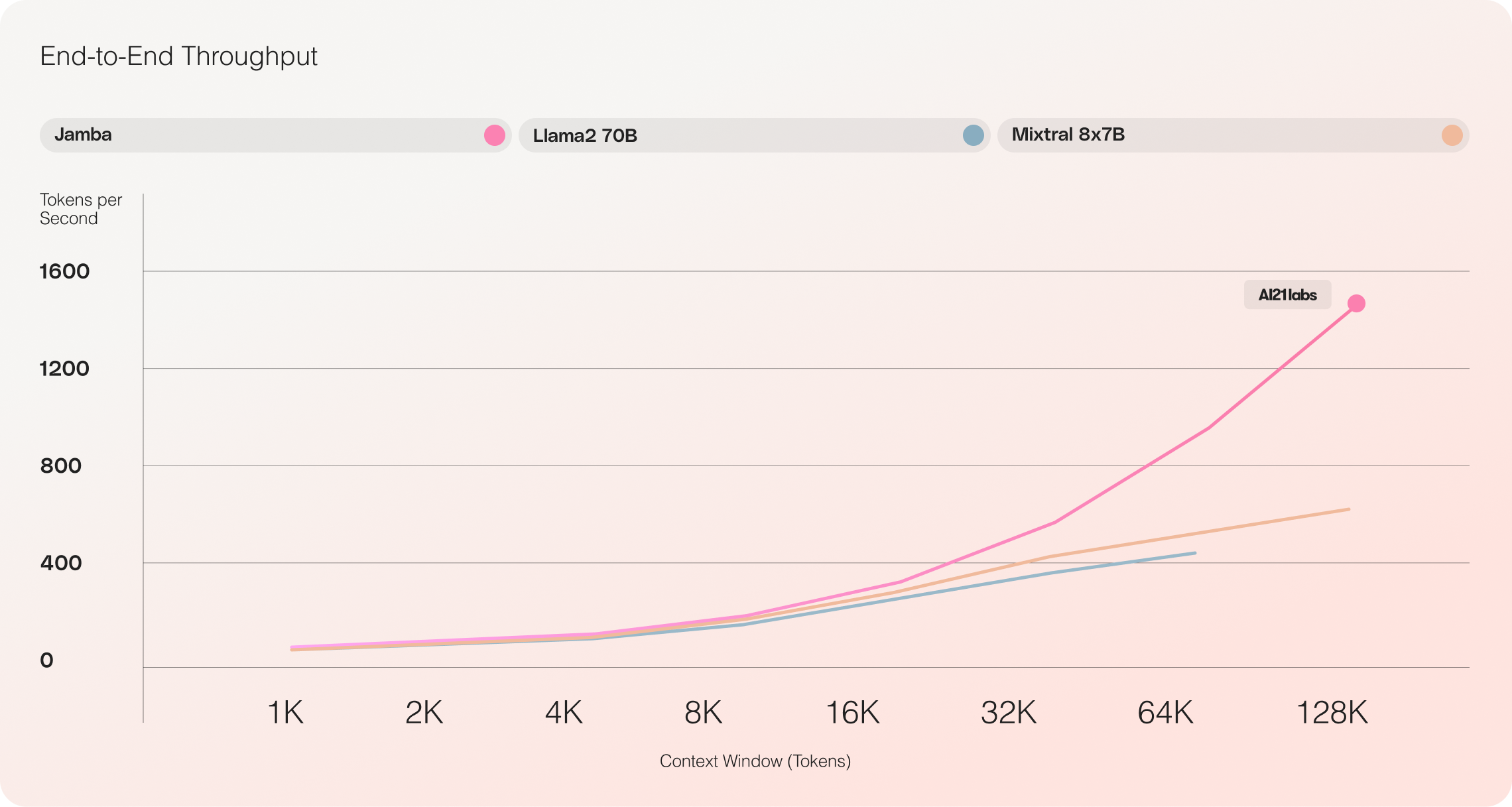
- Rendimiento sin igual: Jamba logra una velocidad tres veces mayor en contextos largos en comparación con Mixtral 8x7B, estableciendo nuevos estándares de eficiencia.
- Ventana de contexto masiva: Con una ventana de contexto de 256K, Jamba democratiza el acceso a las capacidades de manejo de contexto extensas.
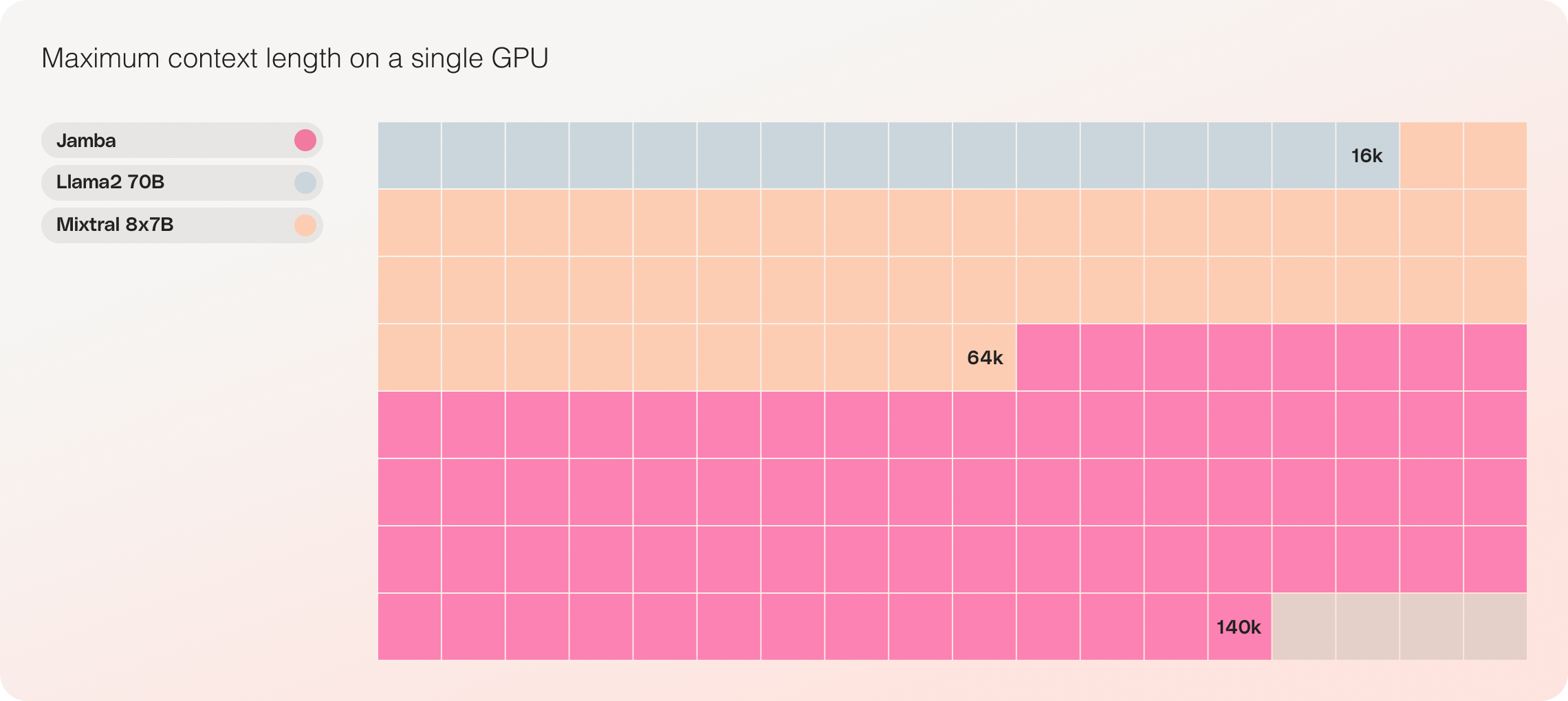
- Compatibilidad con una sola GPU: Jamba es el único modelo en su clase de tamaño que puede alojar hasta 140K de contexto en una sola GPU, lo que lo hace más accesible para implementación y experimentación.
- Disponibilidad de código abierto: Lanzado con pesos abiertos bajo la licencia Apache 2.0, Jamba invita a optimizaciones y descubrimientos adicionales por parte de la comunidad de IA.
- Próxima integración en el catálogo de API de NVIDIA: Jamba estará pronto disponible en el catálogo de API de NVIDIA como un microservicio de inferencia NVIDIA NIM, lo que permitirá a los desarrolladores de aplicaciones empresariales implementarlo utilizando la plataforma de software NVIDIA AI Enterprise.
Jamba: Combinando lo mejor de las arquitecturas Mamba y Transformer
Jamba representa un hito significativo en la innovación de LLM al incorporar exitosamente a Mamba junto con la arquitectura de Transformer y escalar el modelo híbrido SSM-Transformer a una calidad de grado de producción.
Los LLM basados en Transformer tradicionales enfrentan dos desafíos principales:
- Gran huella de memoria: La huella de memoria de Transformer aumenta con la longitud del contexto, lo que dificulta la ejecución de ventanas de contexto largas o lotes paralelos numerosos sin recursos de hardware extensos.
- Inferencia lenta en contextos largos: El mecanismo de atención en los Transformers escala de forma cuadrática con la longitud de la secuencia, lo que ralentiza el rendimiento a medida que cada token depende de toda la secuencia precedente.
Mamba, propuesto por investigadores de las universidades de Carnegie Mellon y Princeton, aborda estas deficiencias. Sin embargo, sin atención en todo el contexto, Mamba tiene dificultades para igualar la calidad de salida de los mejores modelos existentes, especialmente en tareas relacionadas con el recuerdo.

Jamba vs Mamba vs Transformer
La arquitectura híbrida de Jamba, compuesta por capas de Transformer, Mamba y mezcla de expertos (MoE), se optimiza para memoria, rendimiento y eficiencia al mismo tiempo. Las capas de MoE permiten que Jamba utilice solo 12B de sus 52B de parámetros durante la inferencia, lo que hace que esos parámetros activos sean más eficientes que un modelo solo de Transformer de tamaño equivalente.
Escalando la arquitectura híbrida de Jamba
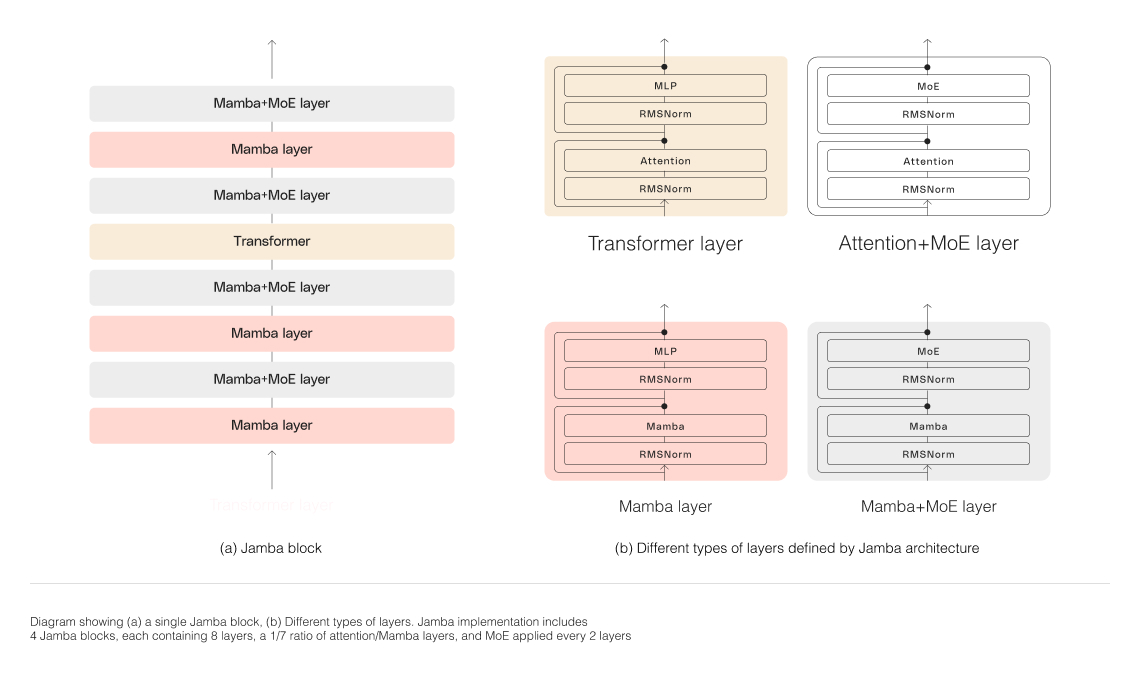
Para escalar con éxito la estructura híbrida de Jamba, AI21 Labs implementó varias innovaciones arquitectónicas fundamentales:
-
Enfoque de bloques y capas: La arquitectura de Jamba cuenta con un enfoque de bloques y capas, lo que permite la integración fluida de las arquitecturas de Transformer y Mamba. Cada bloque de Jamba contiene una capa de atención o una capa de Mamba, seguida de un perceptrón multicapa (MLP), lo que resulta en una proporción general de una capa de Transformer por cada ocho capas.
-
Utilización de mezcla de expertos (MoE): Al emplear capas de MoE, Jamba aumenta el número total de parámetros del modelo mientras simplifica el número de parámetros activos utilizados durante la inferencia. Esto resulta en una mayor capacidad del modelo sin un aumento correspondiente en los requisitos de cómputo. El número de capas y expertos de MoE se ha optimizado para maximizar la calidad y el rendimiento del modelo en una sola GPU de 80 GB, dejando suficiente memoria para tareas de inferencia comunes.
El impresionante rendimiento y eficiencia de Jamba
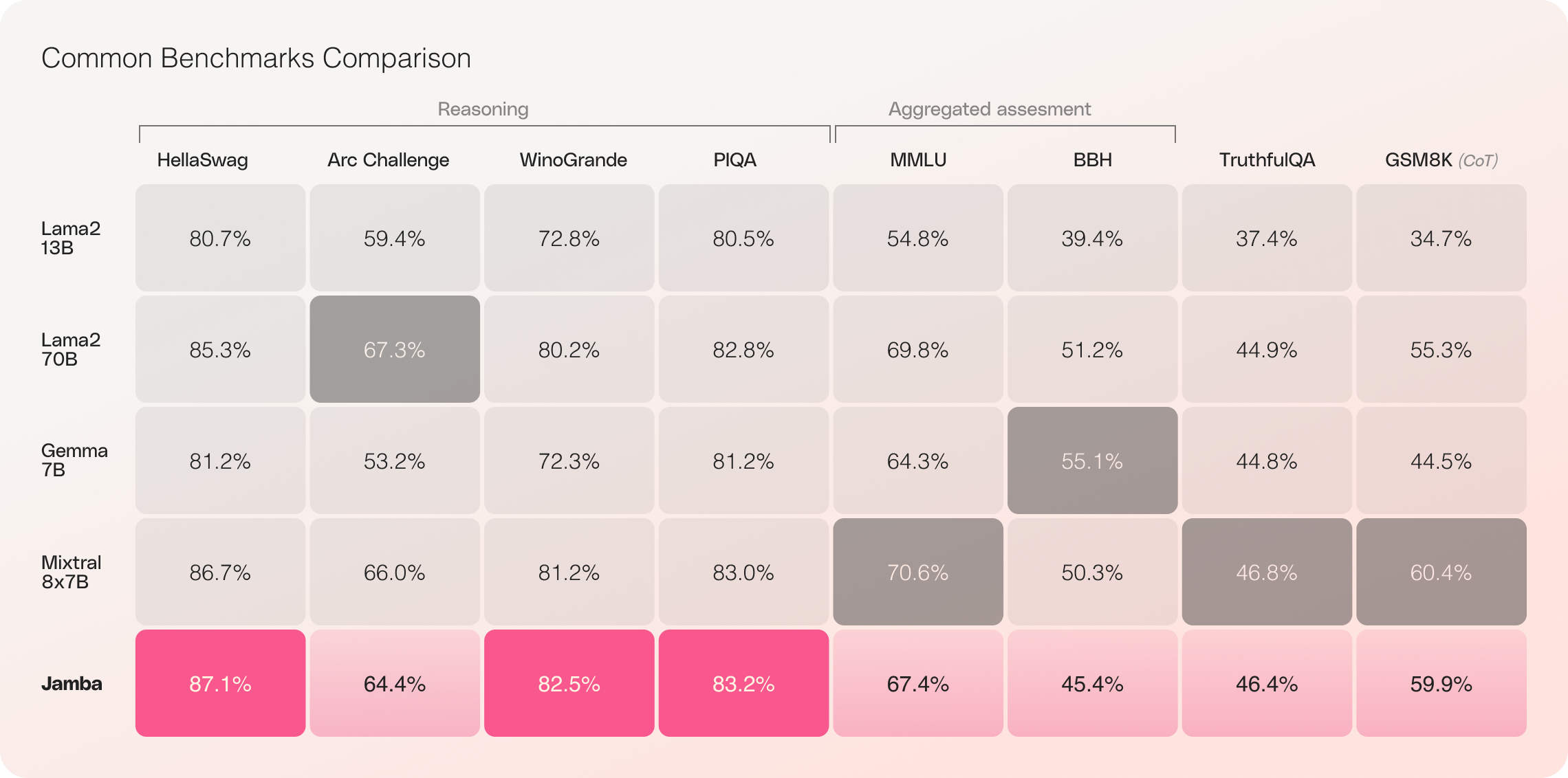
Jamba vs Llama 70B vs Mixtral 8x7B
Las evaluaciones iniciales de Jamba han brindado resultados impresionantes en métricas clave como el rendimiento y la eficiencia. Se espera que estos puntos de referencia mejoren aún más a medida que la comunidad continúe experimentando y optimizando esta tecnología innovadora.
- Eficiencia: Jamba ofrece un rendimiento 3 veces mayor en contextos largos, lo que lo hace más eficiente que modelos basados en Transformer comparables como Mixtral 8x7B.
- Rentabilidad: Con la capacidad de almacenar 140K contextos en una sola GPU, Jamba permite una implementación más accesible y oportunidades de experimentación en comparación con otros modelos de código abierto de tamaño similar.
Se espera que optimizaciones futuras, como una paralelización mejorada de MoE e implementaciones más rápidas de Mamba, impulsen aún más estas ganancias impresionantes.
Comienza a construir con Jamba
Jamba ahora está disponible en Hugging Face, liberado con pesos abiertos bajo la licencia Apache 2.0. Como modelo base, Jamba está destinado a servir como fundamento para el ajuste fino, entrenamiento y desarrollo de soluciones personalizadas. Es esencial agregar salvaguardias apropiadas para un uso responsable y seguro.
Una versión instructiva de Jamba estará disponible próximamente en beta a través de la Plataforma AI21. Para compartir tus proyectos, proporcionar feedback o hacer preguntas, únete a la conversación en Discord.
Conclusión
La introducción de Jamba marca un gran avance en la tecnología de IA, mostrando el inmenso potencial de las arquitecturas híbridas SSM-Transformer. Al combinar las fortalezas de Mamba y Transformer mientras se optimiza la eficiencia y el rendimiento, Jamba establece nuevos estándares para los modelos de IA en su clase de tamaño.
Con su impresionante manejo de contextos, rendimiento y rentabilidad, Jamba está listo para revolucionar el panorama de la IA, permitiendo a investigadores, desarrolladores y empresas ampliar los límites de lo posible. A medida que la comunidad continúa explorando y construyendo sobre las innovaciones de Jamba, podemos anticipar una nueva ola de aplicaciones de IA que darán forma al futuro de la inteligencia artificial.