La Era de los Modelos de Lenguaje de 1-bit a Gran Escala: Microsoft Introduce BitNet b1.58
Published on
Introducción
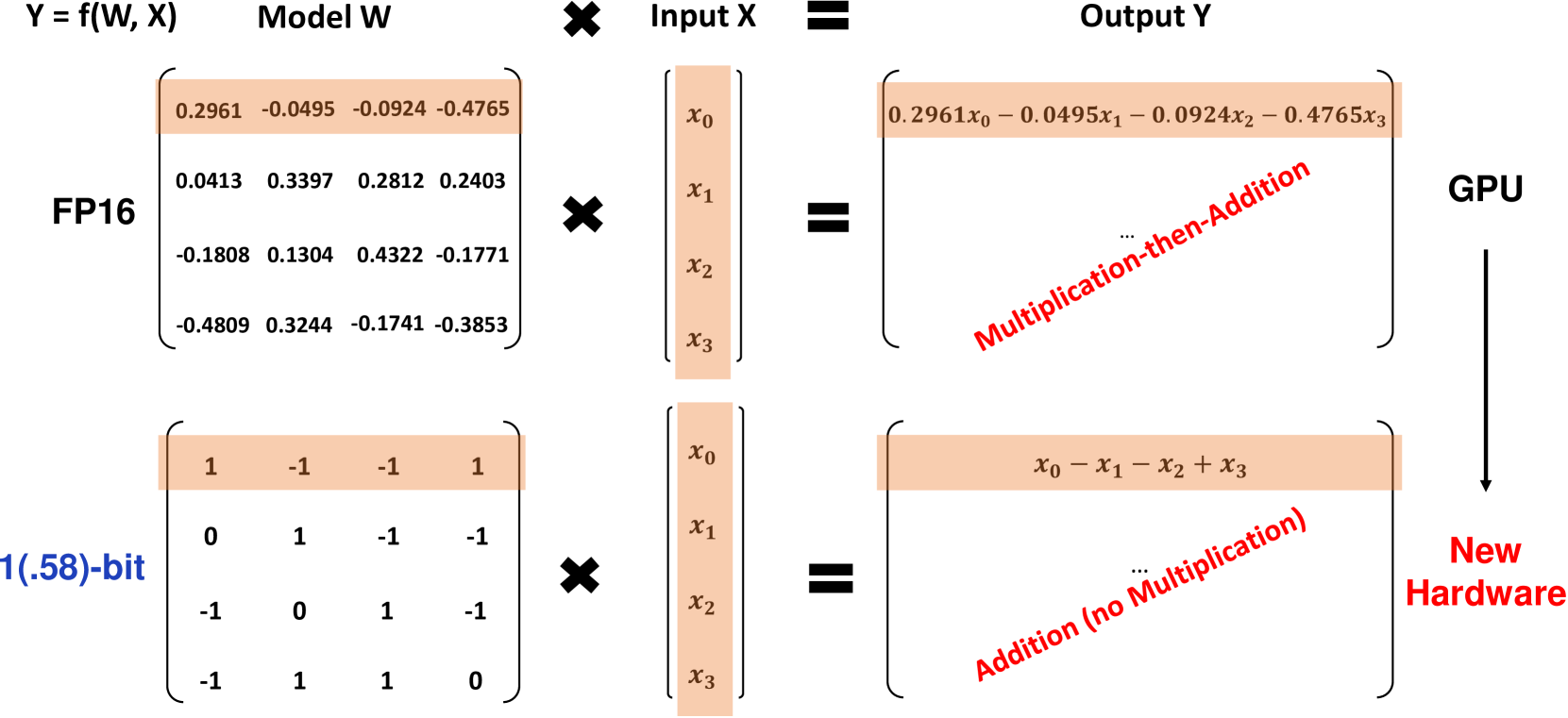
Investigadores de Microsoft han introducido una variante revolucionaria de Modelos de Lenguaje de 1-bit a Gran Escala (LLM) llamada BitNet b1.58, donde cada parámetro del modelo es ternario, tomando valores de 1. Este LLM de 1.58-bit iguala el rendimiento de los LLMs Transformer de precisión completa (FP16 o BF16) con el mismo tamaño de modelo y tokens de entrenamiento, al mismo tiempo que es significativamente más rentable en términos de latencia, uso de memoria, rendimiento y consumo de energía. BitNet b1.58 representa un gran avance en la creación de LLMs de alto rendimiento y altamente eficientes.

¿Qué es BitNet b1.58?
BitNet b1.58 se basa en la arquitectura original de BitNet, un modelo Transformer que reemplaza las capas estándar de nn.Linear con capas BitLinear. Se entrena desde cero con pesos de 1.58-bit y activaciones de 8 bits. En comparación con el BitNet de 1-bit original, b1.58 introduce algunas modificaciones clave:
-
Utiliza una función de cuantización de valor absoluto para restringir los pesos a 1. Esto redondea cada peso al entero más cercano entre esos valores después de escalarlo por el valor absoluto promedio.
-
Para las activaciones, las escala al rango [-sa, sa] por token, simplificando su implementación en comparación con el BitNet original.
-
Adopta componentes de la popular arquitectura de código abierto LLaMA, incluyendo RMSNorm, SwiGLU activations, rotary embeddings y elimina los sesgos. Esto permite una fácil integración con el software LLM existente.
La adición del valor 0 en los pesos permite el filtrado de características, aumentando la capacidad de modelado en comparación con los modelos puramente de 1-bit. Los experimentos muestran que BitNet b1.58 iguala a los modelos FP16 de referencia en perplejidad y rendimiento en tareas finales a partir de un tamaño de 3B de parámetros.
Resultados de rendimiento
Los investigadores compararon BitNet b1.58 con un modelo de referencia FP16 LLaMA LLM reproducido en diferentes tamaños de modelo, desde 700M hasta 70B de parámetros. Ambos modelos fueron pre-entrenados en el mismo conjunto de datos RedPajama durante 100B de tokens y se evaluaron en perplejidad y una variedad de tareas de lenguaje sin ejemplos.
Algunos hallazgos clave incluyen:
-
BitNet b1.58 iguala la perplejidad del modelo FP16 LLaMA en un tamaño de 3B, siendo 2.71 veces más rápido y usando 3.55 veces menos memoria de GPU.
-
Un BitNet b1.58 de 3.9B tiene un rendimiento superior en perplejidad y tareas finales en comparación con el LLaMA de 3B, con menor latencia y costo de memoria.
-
En tareas de lenguaje sin ejemplos, la diferencia de rendimiento entre BitNet b1.58 y LLaMA se reduce a medida que aumenta el tamaño del modelo, siendo BitNet comparable a LLaMA en un tamaño de 3B.
-
Al escalar hasta 70B, BitNet b1.58 logra una aceleración de 4.1 veces en comparación con el modelo FP16 de referencia. Los ahorros de memoria también aumentan con la escala.
-
BitNet b1.58 utiliza un 71.4 veces menos energía para las multiplicaciones de matrices. La eficiencia energética de extremo a extremo aumenta con el tamaño del modelo.
-
En dos GPUs A100 de 80GB, un BitNet b1.58 de 70B permite tamaños de lote 11 veces más grandes que LLaMA, lo que aumenta el rendimiento en un 8.9 veces.
Los resultados demuestran que BitNet b1.58 proporciona una mejora de Pareto sobre los LLMs FP16 del estado del arte, siendo más eficiente en términos de latencia, memoria y energía, al mismo tiempo que iguala la perplejidad y el rendimiento en tareas finales a una escala suficiente. Por ejemplo, un BitNet b1.58 de 13B es más eficiente que un modelo FP16 LLM de 3B, un BitNet de 30B es más eficiente que un FP16 de 7B, y un BitNet de 70B es más eficiente que un modelo FP16 de 13B.
Cuando se entrena con 2T de tokens siguiendo la receta StableLM-3B, BitNet b1.58 superó al modelo StableLM-3B sin ejemplos en todas las tareas evaluadas, mostrando una gran capacidad de generalización.
Las tablas a continuación proporcionan datos más detallados sobre las comparaciones de rendimiento entre BitNet b1.58 y el modelo FP16 LLaMA de referencia:
| Modelos | Tamaño | Memoria (GB) | Latencia (ms) | PPL |
|---|---|---|---|---|
| LLaMA LLM | 700M | 2.08 (1.00x) | 1.18 (1.00x) | 12.33 |
| BitNet b1.58 | 700M | 0.80 (2.60x) | 0.96 (1.23x) | 12.87 |
| LLaMA LLM | 1.3B | 3.34 (1.00x) | 1.62 (1.00x) | 11.25 |
| BitNet b1.58 | 1.3B | 1.14 (2.93x) | 0.97 (1.67x) | 11.29 |
| LLaMA LLM | 3B | 7.89 (1.00x) | 5.07 (1.00x) | 10.04 |
| BitNet b1.58 | 3B | 2.22 (3.55x) | 1.87 (2.71x) | 9.91 |
| BitNet b1.58 | 3.9B | 2.38 (3.32x) | 2.11 (2.40x) | 9.62 |
Tabla 1: Comparación de perplejidad y costos entre BitNet b1.58 y LLaMA LLM.
| Modelos | Tamaño | ARCe | ARCc | HS | BQ | OQ | PQ | WGe | Prom. |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA LLM | 700M | 54.7 | 23.0 | 37.0 | 60.0 | 20.2 | 68.9 | 54.8 | 45.5 |
| BitNet b1.58 | 700M | 51.8 | 21.4 | 35.1 | 58.2 | 20.0 | 68.1 | 55.2 | 44.3 |
| LLaMA LLM | 1.3B | 56.9 | 23.5 | 38.5 | 59.1 | 21.6 | 70.0 | 53.9 | 46.2 |
| BitNet b1.58 | 1.3B | 54.9 | 24.2 | 37.7 | 56.7 | 19.6 | 68.8 | 55.8 | 45.4 |
| LLaMA LLM | 3B | 62.1 | 25.6 | 43.3 | 61.8 | 24.6 | 72.1 | 58.2 | 49.7 |
| BitNet b1.58 | 3B | 61.4 | 28.3 | 42.9 | 61.5 | 26.6 | 71.5 | 59.3 | 50.2 |
| BitNet b1.58 | 3.9B | 64.2 | 28.7 | 44.2 | 63.5 | 24.2 | 73.2 | 60.5 | 51.2 |
Tabla 2: Precisión sin ejemplos de BitNet b1.58 y LLaMA LLM en tareas finales.
La Figura 1 muestra la latencia de decodificación y el consumo de memoria de BitNet b1.58 en diferentes tamaños de modelo.
Referir a la descripción Referir a la descripción Figura 1: Latencia de decodificación (izquierda) y consumo de memoria (derecha) de BitNet b1.58 en diferentes tamaños de modelo. En cuanto a la eficiencia energética, BitNet b1.58 utiliza un 71.4x menos energía para las multiplicaciones de matrices en comparación con los LLMs FP16. El costo energético de extremo a extremo en diferentes tamaños de modelos se ilustra en la Figura 2, mostrando cómo BitNet b1.58 se vuelve cada vez más eficiente a escalas más grandes.
Consulte la leyenda
Consulte la leyenda
Figura 2: Consumo energético de BitNet b1.58 en comparación con LLaMA LLM. Izquierda: Componentes de la energía de las operaciones aritméticas. Derecha: Costo energético de extremo a extremo en diferentes tamaños de modelos.
La capacidad de procesamiento es otra ventaja clave de BitNet b1.58. Con dos GPUs A100 de 80 GB, un BitNet b1.58 de 70B admite lotes de 11x más grande que un LLM LLaMA de 70B, lo que resulta en una mayor capacidad de procesamiento de 8.9x, como se muestra en la Tabla 3.
| Modelos | Tamaño | Tamaño máximo de lote | Capacidad de procesamiento (tokens/s) |
|---|---|---|---|
| LLaMA LLM | 70B | 16 (1.0x) | 333 (1.0x) |
| BitNet b1.58 | 70B | 176 (11.0x) | 2977 (8.9x) |
Tabla 3: Comparación de capacidad de procesamiento de BitNet b1.58 de 70B y LLaMA LLM.
Implicaciones y direcciones futuras
La arquitectura y los resultados de BitNet b1.58 tienen implicaciones significativas para el futuro de los LLM:
-
Establece una nueva frontera de Pareto y una ley de escala para los LLM que son tanto de alto rendimiento como altamente eficientes. Los LLMs de 1.58 bits pueden igualar las líneas de base de FP16 a costos de inferencia considerablemente más bajos.
-
La drástica reducción de memoria permite ejecutar LLMs mucho más grandes en una cantidad de hardware determinada. Esto es especialmente impactante para arquitecturas intensivas en memoria como las de mezcla de expertos.
-
Las activaciones de 8 bits pueden duplicar la longitud de contexto posible con un presupuesto de memoria dado en comparación con los de 16 bits. En el futuro, también es posible una mayor compresión a 4 bits o menos.
-
La eficiencia excepcional de los LLMs de 1.58 bits en dispositivos CPU permite desplegar LLMs potentes en dispositivos de borde/móviles, donde las CPUs son el procesador principal.
-
El nuevo paradigma de cálculo de baja precisión de BitNet b1.58 motiva el diseño de aceleradores de IA personalizados y sistemas optimizados específicamente para LLMs de 1 bit para aprovechar al máximo su potencial.
Microsoft considera que los LLMs de 1 bit son una ruta muy prometedora para hacer que los LLMs sean mucho más rentables mientras se preservan sus capacidades. Visualizan una era en la que los modelos de 1 bit alimenten aplicaciones desde el centro de datos hasta el borde. Sin embargo, para lograr ese futuro, será necesario co-diseñar las arquitecturas de modelos, hardware y sistemas de software para aprovechar completamente las propiedades únicas de estos modelos. BitNet b1.58 establece un punto de partida emocionante para esta nueva era de LLMs.
Conclusión
BitNet b1.58 representa un avance importante en empujar los modelos de lenguaje grandes al límite de cuantización mientras se mantiene el rendimiento. Al aprovechar pesos ternarios 1 y activaciones de 8 bits, iguala a los LLMs FP16 en perplejidad y rendimiento de tareas finales con un uso de memoria, latencia y consumo de energía considerablemente más bajos.
La arquitectura de 1.58 bits establece una nueva frontera de Pareto para los LLMs, donde se pueden ejecutar modelos más grandes a una fracción del costo. Abre nuevas posibilidades como el soporte nativo de un contexto más largo, el despliegue de LLMs potentes en dispositivos de borde y motiva el diseño de hardware personalizado para IA de baja precisión.
El trabajo de Microsoft demuestra que los LLMs agresivamente cuantizados no solo son viables, sino que establecen una ley de escala superior en comparación con los modelos FP16. Con un mayor co-diseño de arquitecturas, hardware y software, los LLMs de 1 bit tienen el potencial de impulsar el próximo gran salto en capacidades de IA rentables, desde la nube hasta el borde. BitNet b1.58 proporciona un impresionante punto de partida para esta emocionante nueva era de modelos de lenguaje grandes y ultrarrápidos.