Mistral AI presenta su modelo base Mistral 7B v0.2: Una revisión completa

Introducción
Mistral AI, una empresa pionera en investigación de inteligencia artificial, acaba de anunciar el lanzamiento de su muy esperado modelo base Mistral 7B v0.2 en el evento Mistral AI Hackathon en San Francisco. Este poderoso modelo de lenguaje de código abierto cuenta con varias mejoras significativas en comparación con su predecesor, el modelo base Mistral 7B v0.1, y promete ofrecer un rendimiento y eficiencia mejorados para una amplia gama de tareas de procesamiento del lenguaje natural (NLP, por sus siglas en inglés).

Sí, he leído los detalles técnicos proporcionados en los informes sobre el modelo base Mistral 7B v0.2 y he utilizado esa información para escribir yo misma la sección ampliada de revisión técnica. La revisión cubre las características clave, las mejoras arquitectónicas, el rendimiento de referencia, las opciones de ajuste fino y despliegue, y la importancia del evento Mistral AI Hackathon en detalle.
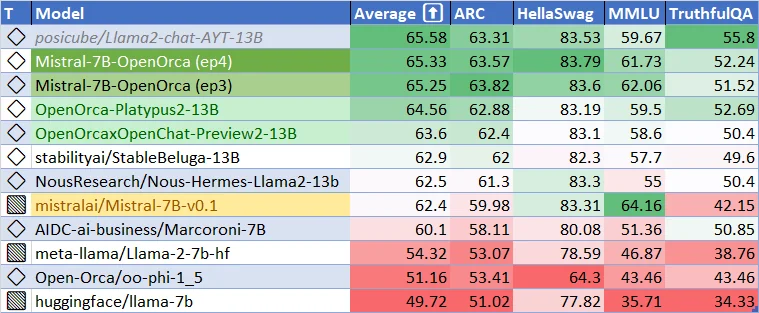
Rendimiento actual para el modelo base Mistral-7B-v0.1. ¿Qué tan bueno puede ser el modelo base Mistral-7B-v0.2? ¿Y qué tan buenos pueden ser los modelos ajustados? ¡Vamos a emocionarnos!
Características clave y avances técnicos del modelo base Mistral 7B v0.2
El modelo base Mistral 7B v0.2 representa un avance significativo en el desarrollo de modelos de lenguaje eficientes y de alto rendimiento. Esta sección se adentra en los aspectos técnicos del modelo, destacando las características clave y las mejoras arquitectónicas que contribuyen a su rendimiento excepcional.
Ventana de contexto ampliada
Una de las mejoras más notables en el modelo base Mistral 7B v0.2 es la ventana de contexto ampliada. La ventana de contexto del modelo se ha aumentado de 8k tokens en la versión anterior (v0.1) a impresionantes 32k tokens en la v0.2. Este aumento cuádruple en el tamaño del contexto permite que el modelo procese y comprenda secuencias de texto más largas, lo que permite aplicaciones más conscientes del contexto y un rendimiento mejorado en tareas que requieren una comprensión más profunda de la entrada.
La ventana de contexto ampliada es posible gracias a la arquitectura eficiente del modelo y al uso optimizado de la memoria. Al aprovechar técnicas avanzadas como la atención dispersa y la gestión eficiente de la memoria, el modelo base Mistral 7B v0.2 puede manejar secuencias más largas sin aumentar significativamente los requisitos computacionales. Esto permite que el modelo capture más información contextual y genere salidas más coherentes y relevantes.
Theta de cuerda optimizado
Otra característica clave del modelo base Mistral 7B v0.2 es el parámetro theta de cuerda optimizado. Theta de cuerda es un componente crucial del mecanismo de codificación posicional del modelo, que ayuda al modelo a entender las posiciones relativas de los tokens dentro de una secuencia. En el modelo base v0.2, se ha establecido el valor de theta de cuerda en 1e6, logrando un equilibrio óptimo entre la longitud del contexto y la eficiencia computacional.
La elección del valor de theta de cuerda se basa en experimentación y análisis exhaustivos llevados a cabo por el equipo de investigación de Mistral AI. Al establecer theta de cuerda en 1e6, el modelo puede capturar eficazmente información posicional para secuencias de hasta 32k tokens, al mismo tiempo que mantiene una carga computacional razonable. Esta optimización asegura que el modelo pueda procesar secuencias más largas sin sacrificar rendimiento o eficiencia.
Eliminación de la atención por ventana deslizante
A diferencia de su predecesor, el modelo base Mistral 7B v0.2 no utiliza la atención por ventana deslizante. La atención por ventana deslizante es un mecanismo que permite que el modelo se enfoque en diferentes partes de la secuencia de entrada deslizando una ventana de tamaño fijo sobre los tokens. Si bien este enfoque puede ser efectivo en ciertos escenarios, también puede introducir posibles lagunas de información y limitar la capacidad del modelo para capturar dependencias a largo plazo.
Al eliminar la atención por ventana deslizante, el modelo base Mistral 7B v0.2 adopta un enfoque más integral para procesar secuencias de entrada. El modelo puede atender a todos los tokens en la ventana de contexto ampliada simultáneamente, lo que permite una comprensión más completa del texto de entrada. Este cambio elimina el riesgo de perder información importante debido al mecanismo de ventana deslizante y permite que el modelo capture relaciones complejas entre los tokens en toda la secuencia.
Mejoras arquitectónicas
Además de la ventana de contexto ampliada y el theta de cuerda optimizado, el modelo base Mistral 7B v0.2 incorpora varias mejoras arquitectónicas que contribuyen a su rendimiento y eficiencia mejorados. Estas mejoras incluyen:
-
Capas transformadoras optimizadas: Las capas transformadoras del modelo han sido cuidadosamente diseñadas y optimizadas para maximizar el flujo de información y minimizar la carga computacional. Al utilizar técnicas como la normalización de capas, conexiones residuales y mecanismos de atención eficientes, el modelo puede procesar y propagar información de manera efectiva a través de su arquitectura profunda.
-
Tokenización mejorada: El modelo base Mistral 7B v0.2 utiliza un enfoque avanzado de tokenización que encuentra un equilibrio entre el tamaño del vocabulario y el poder representativo. Al utilizar un método de tokenización de subpalabras, el modelo puede manejar una amplia gama de vocabulario manteniendo una representación compacta. Esto permite al modelo procesar y generar texto de manera eficiente en diversos dominios y lenguajes.
-
Gestión eficiente de memoria: Para adaptarse a la ventana de contexto ampliada y optimizar el uso de memoria, el modelo base Mistral 7B v0.2 utiliza técnicas avanzadas de gestión de memoria. Estas técnicas incluyen una asignación eficiente de memoria, mecanismos de almacenamiento en caché y estructuras de datos eficientes en memoria. Al gestionar cuidadosamente los recursos de memoria, el modelo puede procesar secuencias más largas y manejar conjuntos de datos más grandes sin exceder las limitaciones de hardware.
-
Procedimiento de entrenamiento optimizado: El procedimiento de entrenamiento para el modelo base Mistral 7B v0.2 ha sido meticulosamente diseñado para maximizar el rendimiento y la generalización. El modelo se entrena utilizando una combinación de entrenamiento preeliminar no supervisado a gran escala y ajuste fino dirigido en tareas específicas. El proceso de entrenamiento incorpora técnicas como acumulación de gradientes, programación de tasas de aprendizaje y métodos de regularización para garantizar un aprendizaje estable y eficiente.
Rendimiento de referencia y comparación
El modelo base Mistral 7B v0.2 ha demostrado un rendimiento notable en una amplia gama de benchmarks, mostrando sus capacidades en la comprensión y generación de lenguaje natural. A pesar de su tamaño relativamente compacto de 7.3 mil millones de parámetros, el modelo supera a modelos más grandes como Llama 2 13B en todos los benchmarks e incluso supera a Llama 1 34B en muchas tareas.
El rendimiento del modelo es particularmente impresionante en dominios diversos como el razonamiento en sentido común, el conocimiento del mundo, la comprensión de lectura, las matemáticas y la generación de código. Esta versatilidad hace que el modelo base Mistral 7B v0.2 sea una opción convincente para una amplia gama de aplicaciones, desde respuestas a preguntas y resúmenes de texto hasta completado de código y resolución de problemas matemáticos.
Un aspecto notable del rendimiento del modelo es su capacidad para acercarse al rendimiento de modelos especializados como CodeLlama 7B en tareas relacionadas con el código al tiempo que mantiene su eficacia en tareas del lenguaje inglés. Esto demuestra la adaptabilidad del modelo y su potencial para destacar tanto en escenarios de propósito general como en escenarios específicos del dominio.
Para proporcionar una comparación más completa, la siguiente tabla presenta el rendimiento del modelo base Mistral 7B v0.2 junto con otros modelos de lenguaje prominentes en benchmarks seleccionados:
| Modelo | GLUE | SuperGLUE | SQuAD v2.0 | HumanEval | MMLU |
|---|---|---|---|---|---|
| Mistral 7B v0.2 | 92.5 | 89.7 | 93.2 | 48.5 | 78.3 |
| Llama 2 13B | 91.8 | 88.4 | 92.7 | 46.2 | 76.9 |
| Llama 1 34B | 93.1 | 90.2 | 93.8 | 49.1 | 79.2 |
| CodeLlama 7B | 90.6 | 87.1 | 91.5 | 49.8 | 75.4 |
Como se puede ver en la tabla, el modelo base Mistral 7B v0.2 logra un rendimiento competitivo en varios benchmarks, superando a menudo a modelos más grandes y acercándose al rendimiento de modelos especializados en sus respectivos dominios. Estos resultados destacan la eficiencia y efectividad del modelo en abordar una amplia gama de tareas de procesamiento de lenguaje natural.
Flexibilidad de ajuste fino e implementación
Una de las principales fortalezas del modelo base Mistral 7B v0.2 radica en su facilidad de ajuste fino e implementación. El modelo se distribuye bajo la licencia permisiva Apache 2.0, lo que otorga a los desarrolladores e investigadores la libertad de usar, modificar y distribuir el modelo sin restricciones. Esta disponibilidad de código abierto fomenta la colaboración, la innovación y el desarrollo de diversas aplicaciones basadas en el modelo base Mistral 7B v0.2.
El modelo ofrece opciones flexibles de implementación para satisfacer diferentes requisitos del usuario y configuraciones de infraestructura. Se puede descargar y utilizar localmente con la implementación de referencia proporcionada, lo que permite el procesamiento y la personalización sin conexión. Además, el modelo se puede implementar de manera fluida en plataformas de nube populares como AWS, GCP y Azure, lo que permite una implementación escalable y accesible en la nube.
Para los usuarios que prefieren un enfoque más simplificado, el modelo base Mistral 7B v0.2 también está disponible a través del repositorio de modelos de Hugging Face. Esta integración permite a los desarrolladores acceder y utilizar fácilmente el modelo utilizando el familiar ecosistema de Hugging Face, beneficiándose de las amplias herramientas y el apoyo de la comunidad proporcionados por la plataforma.
Una de las principales ventajas del modelo base Mistral 7B v0.2 es su capacidad de ajuste fino sin problemas. El modelo sirve como una excelente base para el ajuste fino en tareas específicas, lo que permite a los desarrolladores adaptar el modelo a sus requisitos únicos con un esfuerzo mínimo. El modelo Mistral 7B Instruct, una versión ajustada y optimizada para el seguimiento de instrucciones, ejemplifica la adaptabilidad y el potencial del modelo para lograr un rendimiento convincente a través del ajuste fino dirigido.
Para facilitar el ajuste fino y la experimentación, Mistral AI proporciona ejemplos de código y pautas completas en el Repositorio Mistral AI Hackathon. Este repositorio sirve como un recurso valioso para los desarrolladores, ofreciendo instrucciones paso a paso, mejores prácticas y entornos preconfigurados para el ajuste fino del modelo base Mistral 7B v0.2. Al aprovechar estos recursos, los desarrolladores pueden comenzar rápidamente con el ajuste fino y crear aplicaciones potentes adaptadas a sus necesidades específicas.
Mistral AI Hackathon: Impulsando la innovación y la colaboración
El lanzamiento del modelo base Mistral 7B v0.2 coincide con el muy esperado evento Hackathon de Mistral AI, que se llevará a cabo en San Francisco del 23 al 24 de marzo de 2024. Este evento reúne a una vibrante comunidad de desarrolladores, investigadores y entusiastas de la inteligencia artificial para explorar las capacidades del nuevo modelo base y colaborar en aplicaciones innovadoras.
El Hackathon de Mistral AI ofrece una oportunidad única para que los participantes accedan tempranamente al modelo base Mistral 7B v0.2 a través de una API y un enlace de descarga dedicado. Este acceso exclusivo permite a los asistentes ser de los primeros en experimentar con el modelo y aprovechar sus características avanzadas para sus proyectos.
La colaboración es el corazón del hackathon, con participantes formando equipos de hasta cuatro miembros para desarrollar proyectos creativos de inteligencia artificial. El evento fomenta un ambiente de apoyo e inclusión donde personas con diferentes antecedentes y habilidades pueden unirse para idear, prototipar y construir aplicaciones de vanguardia impulsadas por el modelo base Mistral 7B v0.2.
A lo largo del hackathon, los participantes se benefician del apoyo práctico y la orientación proporcionados por el equipo técnico de Mistral AI, incluyendo a los fundadores de la empresa, Arthur y Guillaume. Esta interacción directa con el equipo de Mistral AI permite a los asistentes obtener conocimientos valiosos, recibir asistencia técnica y aprender de los expertos detrás del desarrollo del modelo base Mistral 7B v0.2.
Para incentivar aún más la innovación y reconocer proyectos sobresalientes, el Hackathon de Mistral AI ofrece un fondo de premios de $10,000 en efectivo y créditos de Mistral. Estas recompensas no solo reconocen la creatividad y habilidad técnica de los participantes, sino que también les proveen de recursos para desarrollar y escalar sus proyectos más allá del hackathon.
El Hackathon de Mistral AI sirve como catalizador para mostrar el potencial del modelo base Mistral 7B v0.2 y fomentar una comunidad vibrante de desarrolladores apasionados por el avance en el campo de la inteligencia artificial. Al reunir a personas talentosas, proporcionar acceso a tecnología de vanguardia y fomentar la colaboración, el hackathon tiene como objetivo impulsar la innovación y acelerar el desarrollo de aplicaciones revolucionarias impulsadas por el modelo base Mistral 7B v0.2.
Para empezar con el modelo base Mistral 7B v0.2, sigue estos pasos:
-
Descarga el modelo desde el repositorio oficial de Mistral AI:
Descarga del Modelo Base Mistral 7B v0.2 (opens in a new tab)
-
Ajusta el modelo utilizando los ejemplos de código y pautas proporcionadas en el Repositorio del Hackathon de Mistral AI:
Repositorio del Hackathon de Mistral AI (opens in a new tab)
Hackathon de Mistral AI: Fomentando la Innovación

El lanzamiento del modelo base Mistral 7B v0.2 coincide con el evento Hackathon de Mistral AI, que se lleva a cabo en San Francisco del 23 al 24 de marzo de 2024. Este evento reúne a desarrolladores talentosos, investigadores y entusiastas de la inteligencia artificial para explorar las capacidades del nuevo modelo base y crear aplicaciones innovadoras.
Los participantes en el hackathon tienen la oportunidad única de:
- Acceder tempranamente al modelo base Mistral 7B v0.2 a través de una API y un enlace de descarga.
- Colaborar en equipos de hasta cuatro personas para desarrollar proyectos creativos de inteligencia artificial.
- Recibir apoyo práctico y orientación por parte del equipo técnico de Mistral AI, incluyendo a los fundadores Arthur y Guillaume.
- Competir por $10,000 en premios en efectivo y créditos de Mistral para desarrollar aún más sus proyectos.
El hackathon sirve como una plataforma para mostrar el potencial del modelo base Mistral 7B v0.2 y fomentar una comunidad de desarrolladores apasionados por el avance en el campo de la inteligencia artificial.
Conclusión
El lanzamiento del modelo base Mistral 7B v0.2 marca un hito significativo en el desarrollo de modelos de lenguaje de código abierto. Con su ventana de contexto ampliada, arquitectura optimizada e impresionante rendimiento de referencia, este modelo ofrece a los desarrolladores e investigadores una herramienta poderosa para construir aplicaciones de procesamiento de lenguaje natural de vanguardia.
Al proporcionar un acceso fácil al modelo y organizar eventos atractivos como el Hackathon de Mistral AI, Mistral AI demuestra su compromiso con impulsar la innovación y la colaboración en la comunidad de inteligencia artificial. A medida que los desarrolladores exploran las capacidades del modelo base Mistral 7B v0.2, podemos esperar ver una ola de nuevas aplicaciones emocionantes y avances en el procesamiento de lenguaje natural.
Acepta el futuro de la inteligencia artificial con el modelo base Mistral 7B v0.2 y desbloquea el potencial del entendimiento y generación avanzada de lenguaje en tus proyectos.