Recuperación-Aumentada Generación (RAG): Explicado Claramente
- Name
- Jennie Rose
Published on
Si estás navegando por el intrincado paisaje de los Modelos de Aprendizaje de Lenguaje (LLMs), no puedes pasar por alto a RAG, abreviatura de Recuperación-Aumentada Generación. Esta técnica es un cambio de juego, ofreciendo un enfoque matizado para el aprendizaje automático y el procesamiento del lenguaje natural. Esta guía tiene como objetivo ser tu recurso definitivo para comprender e implementar RAG en LLMs.
Desde científicos de datos hasta principiantes en el aprendizaje automático, dominar RAG puede ser tu arma secreta. Cubriremos su arquitectura, su integración en LLMs, su comparación con la afinación y su aplicación en plataformas como langChain. ¡Así que empecemos!
¿Qué es RAG?
Definición de RAG
Recuperación-Aumentada Generación (RAG) es un modelo avanzado de aprendizaje automático que combina las capacidades de dos tipos distintos de modelos: un recuperador y un generador. En esencia, el recuperador escanea un conjunto de datos para encontrar información relevante, que el generador luego utiliza para construir una respuesta detallada y coherente.
- Recuperador: Utiliza algoritmos como BM25 o Recuperador Denso para revisar un corpus y encontrar documentos relevantes.
- Generador: Normalmente es un modelo basado en transformers como BERT, GPT-2 o GPT-3 que genera texto similar al humano basándose en los documentos recuperados.
Cómo Funciona RAG: Una Inmersión Técnica Profunda
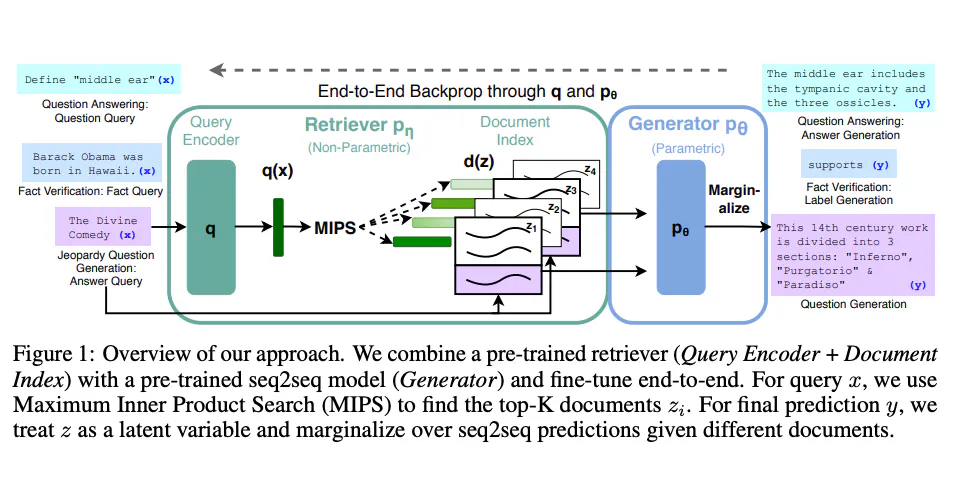
El modelo de RAG opera en un proceso de dos pasos:
- Paso de Recuperación: Dada una consulta, el recuperador escanea el corpus y recupera los
Ndocumentos más relevantes. Esto se hace a menudo utilizando una métrica de similitud como la similitud del coseno.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
vectorizador = TfidfVectorizer()
matriz_tfidf = vectorizador.fit_transform(corpus)
vector_consulta = vectorizador.transform([consulta])
puntuaciones_similitud = cosine_similarity(vector_consulta, matriz_tfidf)- Paso de Generación: El generador toma estos
Ndocumentos y la consulta original para generar una respuesta coherente.
from transformers import TokenizadorRag, RecuperadorRag, TokenParaGeneraciónRag
tokenizador = TokenizadorRag.from_pretrained("facebook/rag-token-base")
recuperador = RecuperadorRag.from_pretrained("facebook/rag-token-base", nombre_índice="exacto", utilizar_conjunto_datos_falso=True)
modelo = TokenParaGeneraciónRag.from_pretrained("facebook/rag-token-base", recuperador=recuperador)
ids_entrada = tokenizador(consulta, return_tensors="pt").input_ids
resultados = modelo.generate(ids_entrada)
generado = tokenizador.decode(resultados[0], saltar_tokens_especiales=True)Al combinar estos dos pasos, RAG puede responder a consultas complejas con respuestas detalladas y contextualmente relevantes.
Cómo Usar RAG para LLMs
Configurando RAG para LLMs
Para implementar RAG en LLMs, necesitarás:
- Un corpus: Esto puede estar en forma de una base de datos SQL, Elasticsearch o un simple archivo JSON.
- Un marco de aprendizaje automático: TensorFlow o PyTorch se suelen utilizar.
- Recursos informáticos: Suficiente CPU/GPU para entrenamiento e inferencia.
Pasos para Implementar RAG en LLMs
Aquí tienes una guía paso a paso para implementar RAG en tu LLM:
- Preparación de Datos: Tu corpus debe estar en un formato que se pueda buscar. Si estás utilizando Elasticsearch, asegúrate de indexar tus datos.
curl -X PUT "localhost:9200/mi_índice"-
Selección de Modelo: Elige tus modelos de recuperador y generador. Puedes utilizar modelos pre-entrenados o entrenar los tuyos propios.
-
Entrenamiento: Entrena los modelos de recuperador y generador. Esto se hace a menudo por separado.
recuperador.entrenar()
generador.entrenar()- Integración: Combina el recuperador y el generador entrenados en un solo modelo de RAG.
modelo_rag = ModeloRag(recuperador, generador)- Pruebas: Valida el rendimiento del modelo utilizando varias métricas como BLEU para la calidad de generación de texto y recall@k para la precisión de recuperación.
Siguiendo estos pasos, tendrás un modelo de RAG robusto que se puede integrar en varios LLMs para un rendimiento superior.
Funciones de Utilidad en RAG para LLMs
Para evaluar tu modelo de RAG, puedes utilizar funciones de utilidad como obtener_puntuación_recuperación() que evalúan el rendimiento del recuperador. Esta función utiliza métricas como Precisión@k o NDCG para la evaluación.
from sklearn.metrics import puntuación_ndcg
ndcg = puntuación_ndcg(y_verdadero, y_puntuación)Esta función puede ser invaluable para afinar el rendimiento de tu recuperador, asegurándote de que recupere los documentos más relevantes del corpus.
RAG vs Afinación
¿Qué Hace Diferente a RAG y la Afinación?
Si bien tanto RAG como la afinación tienen como objetivo mejorar el rendimiento de los Modelos de Aprendizaje de Lenguaje (LLMs), abordan la tarea de manera diferente. La afinación modifica un modelo pre-entrenado existente para adaptarlo mejor a una tarea o conjunto de datos específico. RAG, por otro lado, combina mecanismos de recuperación y generación para responder a consultas complejas.
- Afinación: Implica ajustar los pesos de un modelo pre-entrenado durante la fase de entrenamiento en un conjunto de datos específico.
- RAG: Combina un recuperador y un generador para extraer información relevante de un corpus y luego generar una respuesta coherente.
Comparación Técnica: RAG vs Afinación
- Carga Computacional:
- RAG: Requiere más recursos computacionales ya que involucra dos modelos separados.
- Afinación: Generalmente menos intensiva computacionalmente.
- Flexibilidad:
- RAG: Altamente flexible, puede adaptarse a varios tipos de consultas.
- Fine-Tuning: Limitado a la tarea específica para la que se ajustó.
- Requisitos de datos:
- RAG: Requiere un corpus grande y bien estructurado para la recuperación.
- Fine-Tuning: Necesita un conjunto de datos específico de la tarea para el entrenamiento.
- Complejidad de implementación:
- RAG: Más complejo debido a la integración de dos modelos.
- Fine-Tuning: Relativamente sencillo.
Código de ejemplo: RAG vs Fine-Tuning
Para RAG:
# Usando la biblioteca Transformers de Hugging Face
from transformers import RagModel
rag_model = RagModel.from_pretrained("facebook/rag-token-nq")Para Fine-Tuning:
# Ajustando un modelo BERT usando PyTorch
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
model.train()Al comprender estas diferencias, puede tomar una decisión informada sobre qué enfoque se adapta mejor a su proyecto LLM.
Cómo utilizar RAG para aplicaciones de LLM
Incorporar RAG en LLM existentes
Si ya tiene un LLM y desea incorporar RAG, siga estos pasos:
-
Identificar el caso de uso: Determine qué desea lograr con RAG, ya sea una mejor respuesta a preguntas, resúmenes u otra cosa.
-
Alineación de datos: Asegúrese de que su corpus existente sea compatible con el recuperador que planea utilizar en RAG.
-
Integración del modelo: Integre el modelo RAG en la arquitectura de su LLM existente.
# Ejemplo utilizando PyTorch
class MyLLMWithRAG(nn.Module):
def __init__(self, my_llm, rag_model):
super(MyLLMWithRAG, self).__init__()
self.my_llm = my_llm
self.rag_model = rag_model- Pruebas y validación: Ejecute pruebas para validar que el modelo RAG esté mejorando el rendimiento de su LLM.
Problemas comunes y cómo evitarlos
- Corpus inadecuado: Asegúrese de que su corpus sea lo suficientemente grande y diverso como para que el recuperador encuentre documentos relevantes.
- Modelos incompatibles: El recuperador y el generador deben ser compatibles en términos de tipos y dimensiones de datos.
Al integrar cuidadosamente RAG en sus aplicaciones de LLM, puede mejorar significativamente sus capacidades y rendimiento.
Cómo utilizar RAG con langChain
¿Qué es langChain?
langChain es una plataforma descentralizada para modelos de lenguaje. Permite la integración de varios modelos de aprendizaje automático, incluyendo RAG, para ofrecer servicios de procesamiento de lenguaje natural mejorados.
Pasos para implementar RAG en langChain
-
Instalación: Instale el SDK de langChain y configure su entorno de desarrollo.
-
Subir modelo: Suba su modelo RAG preentrenado a la plataforma de langChain.
langChain upload --model my_rag_model- Integración con API: Utilice la API de langChain para integrar el modelo RAG en su aplicación.
from langChain import RagService
rag_service = RagService(api_key="your_api_key")- Ejecución de consultas: Ejecute consultas a través de la plataforma de langChain, que utilizará su modelo RAG para generar respuestas.
response = rag_service.query("¿Cuál es el significado de la vida?")Siguiendo estos pasos, puede integrar sin problemas RAG en langChain, aprovechando la arquitectura descentralizada de la plataforma para un rendimiento y escalabilidad mejorados.
Conclusion
RAG es una herramienta poderosa que puede elevar significativamente las capacidades de los Modelos de Aprendizaje de Lenguaje (LLM). Ya sea que esté buscando integrarlo en LLM existentes, compararlo con métodos de ajuste fino o incluso usarlo en plataformas descentralizadas como langChain, comprender RAG puede brindarle una ventaja distintiva. Con sus mecanismos duales de recuperación y generación, RAG ofrece un enfoque matizado para consultas complejas, lo que lo convierte en un activo invaluable en el campo del aprendizaje automático y el procesamiento de lenguaje natural.
Preguntas frecuentes
¿Qué es RAG en LLM?
RAG, o Retrieval-Augmented Generation, es una técnica que combina un recuperador y un generador para responder consultas complejas en Modelos de Aprendizaje de Lenguaje.
¿Cuál es la diferencia entre rag y LLM?
RAG es una técnica específica utilizada para mejorar las capacidades de los Modelos de Aprendizaje de Lenguaje. No es un modelo independiente, sino un componente que se puede integrar en LLM existentes.
¿Cómo se evalúa un LLM de rag?
Se utilizan métricas de evaluación como BLEU para la calidad de generación de texto y recall@k para la precisión de recuperación.
¿Qué es rag vs fine-tuning?
RAG combina mecanismos de recuperación y generación, mientras que el ajuste fino implica modificar un modelo existente para adaptarlo a una tarea específica.
¿Cuáles son los beneficios de rag LLM?
RAG permite respuestas más matizadas y contextualmente relevantes, lo que lo hace altamente efectivo para consultas complejas.
