Les 10 meilleures bases de données vectorielles en 2023 : Une revue complète

Les bases de données vectorielles ne sont plus un sujet de niche discuté uniquement entre les scientifiques des données et les administrateurs de bases de données. Alors que nous entrons dans l'année 2023, elles sont devenues un point central pour quiconque traite des types de données complexes tels que les images, le son et le texte. Mais qu'est-ce exactement qu'une base de données vectorielle et pourquoi suscitent-elles autant d'attention ?
Dans cet article, nous démystifierons les bases de données vectorielles, nous passerons en revue leurs avantages et inconvénients, et nous dévoilerons l'engouement qui les entoure. Nous vous présenterons également un aperçu exclusif des 9 meilleures bases de données vectorielles de 2023, en mettant l'accent sur les options open-source. Alors, plongeons !
Vous voulez connaître les dernières actualités de LLM ? Consultez le dernier classement LLM !
Qu'est-ce qu'une base de données vectorielle ?
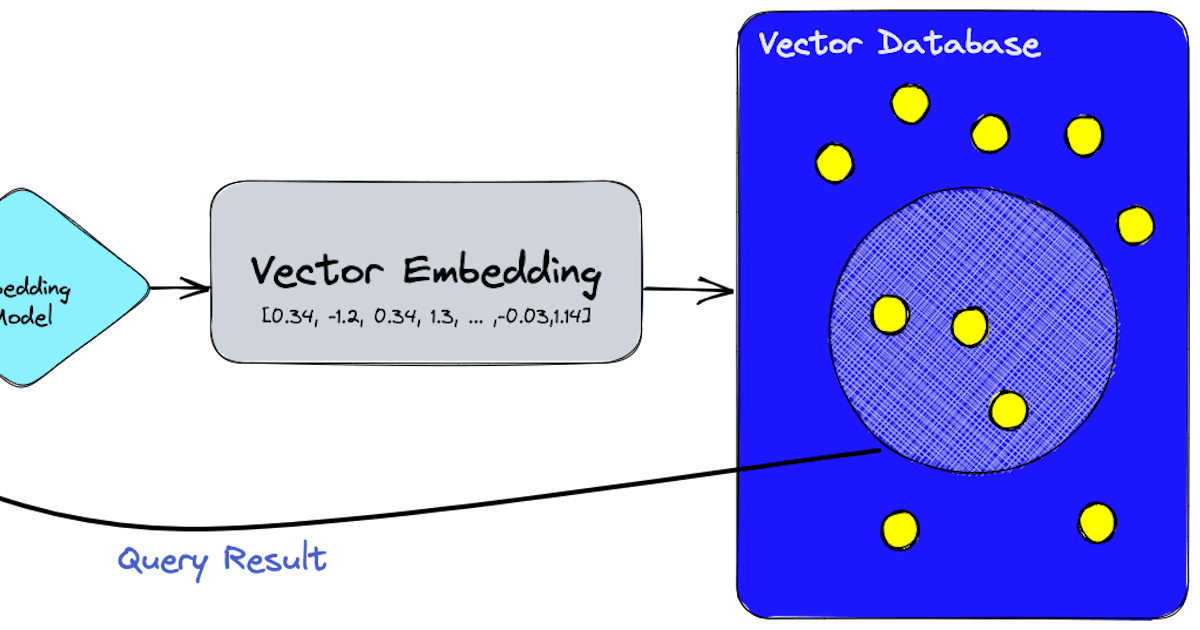
Une base de données vectorielle est un type spécialisé de base de données conçu pour gérer des types de données complexes avec lesquels les bases de données traditionnelles luttent. Contrairement aux bases de données relationnelles standard qui stockent les données dans des tables, les bases de données vectorielles utilisent des vecteurs mathématiques pour représenter les données. Cela leur permet de gérer et de rechercher efficacement des données de grande dimension telles que des images, des fichiers audio et du contenu textuel.
Les bases de données vectorielles utilisent des algorithmes tels que k-NN (k plus proches voisins) pour rechercher des données de grande dimension. Elles utilisent également des techniques de quantification et de partitionnement pour optimiser les performances de recherche. Voici un exemple de requête pour rechercher des images similaires dans une base de données vectorielle :
SELECT * FROM images WHERE VECTOR_SEARCH(image_vector, target_vector) < 0.2;Dans cet exemple de requête, VECTOR_SEARCH est une fonction qui calcule la similarité entre image_vector et target_vector. Le < 0.2 spécifie le seuil de similarité.
Pourquoi les bases de données vectorielles sont-elles différentes ?
-
Traitement de données de grande dimension : Les bases de données traditionnelles ne sont pas équipées pour gérer des données de grande dimension. Les bases de données vectorielles comblent cette lacune en utilisant des vecteurs mathématiques pour la représentation, ce qui facilite le traitement des types de données complexes.
-
Capacités de recherche rapide : L'un des avantages significatifs des bases de données vectorielles est leur capacité à effectuer des recherches de similarité rapides. Par exemple, si vous avez une image, une base de données vectorielle peut rapidement trouver des images similaires dans la base de données sans avoir à parcourir chaque entrée.
-
Scalabilité : Avec la croissance des données, la nécessité de bases de données capables de s'adapter sans dégradation des performances devient cruciale. Les bases de données vectorielles sont conçues en gardant à l'esprit la scalabilité, ce qui leur permet de gérer efficacement de grandes quantités de données.
Revue des bases de données vectorielles : Conformité à l'engouement ?
Comme pour toute technologie émergente, les bases de données vectorielles ont été entourées d'une quantité considérable d'engouement. Beaucoup affirment qu'elles sont la prochaine grande révolution dans la technologie des bases de données, en établissant des parallèles avec le mouvement NoSQL qui a bouleversé le paysage des bases de données il y a une décennie. Mais dans quelle mesure cela est-il vrai, et quels sont les éléments dont il faut se méfier ?
La dure vérité des bases de données vectorielles : Faut-il s'adapter ?
L'engouement n'est pas totalement infondé. Les bases de données vectorielles offrent en effet des fonctionnalités uniques que les bases de données traditionnelles n'ont pas, surtout lorsqu'il s'agit de gérer des données complexes de grande dimension. Cependant, il est essentiel de distinguer le bon grain de l'ivraie. Toutes les bases de données vectorielles ne sont pas à la hauteur de l'engouement, et certaines sont plus axées sur le marketing que sur la fourniture de fonctionnalités robustes.
Ce qu'il faut surveiller lors du choix des bases de données vectorielles :
-
Promesses exagérées et absence de résultats : Certaines bases de données vectorielles promettent monts et merveilles, mais échouent à fournir des fonctionnalités essentielles telles que la haute disponibilité, les systèmes de sauvegarde et les types de données avancés tels que les données géospatiales et les données temporelles.
-
Complexité : Bien que les bases de données vectorielles soient puissantes, elles peuvent également être complexes à mettre en place et à gérer. Assurez-vous d'avoir l'expertise technique nécessaire pour les manipuler, ou soyez prêt à investir dans une formation.
-
Coûts : Méfiez-vous des coûts cachés, en particulier avec les bases de données propriétaires. Les frais de licence peuvent s'accumuler, et vous devrez peut-être également investir dans du matériel spécialisé.
En étant conscient de ces points, vous pouvez naviguer dans l'engouement et prendre une décision plus éclairée. Souvenez-vous toujours de regarder au-delà des mots à la mode du marketing et plongez profondément dans les fonctionnalités et les limitations réelles de la base de données.
Avantages vs Inconvénients des bases de données vectorielles
Les bases de données vectorielles gagnent en popularité en raison de leur capacité à gérer des types de données complexes tels que les images, le son et le texte. Cependant, il est essentiel de comprendre à la fois leurs avantages et leurs limitations.
Avantages des bases de données vectorielles :
-
Recherche de similarité efficace : Les bases de données vectorielles excellent pour trouver les voisins les plus proches dans des espaces de grande dimension, ce qui est essentiel pour les systèmes de recommandation, la reconnaissance d'images et le traitement du langage naturel.
-
Scalabilité : De nombreuses bases de données vectorielles sont conçues pour gérer des données à grande échelle, certaines offrant même des architectures distribuées pour une scalabilité horizontale.
-
Flexibilité : Avec une prise en charge de diverses mesures de distance et d'algorithmes d'indexation, les bases de données vectorielles peuvent s'adapter très bien à des cas d'utilisation spécifiques.
-
Consommation de ressources élevée : Une recherche rapide s'accompagne souvent d'une consommation importante de ressources informatiques. Certaines bases de données nécessitent du matériel spécialisé pour des performances optimales.
Inconvénients des bases de données vectorielles :
- Complexité : La pléthore d'options algorithmiques et de configurations peut rendre les bases de données vectorielles difficiles à mettre en place et à maintenir.
- Coût: Bien qu'il existe des options open-source, les bases de données de vecteurs commerciaux peuvent être coûteuses, en particulier pour des déploiements à grande échelle.
Top 10 bases de données de vecteurs à considérer en 2023
Principales bases de données de vecteurs open-source en 2023
1. Faiss
- Prix de départ: Gratuit (Open-Source)
- Note: 4,7/5
- Avantages:
- Accélération GPU exceptionnelle via CUDA
- Supporte des milliards de vecteurs
- Nombreuses options algorithmiques telles que IVFADC, PQ et HNSW
- Inconvénients:
- Nécessite une expertise en quantification vectorielle
- Limité aux déploiements sur un seul nœud
Détails techniques: Faiss (opens in a new tab) utilise diverses techniques d'indexation, y compris l'Inverted File Segmenter (IVF) et le Scalar Quantizer (SQ) pour des recherches de similarité efficaces. Il prend également en charge le traitement de requêtes par lots et la parallélisation sur plusieurs GPU. La bibliothèque est optimisée tant pour la distance L2 que pour la similarité de produit intérieur, ce qui la rend polyvalente pour différents cas d'utilisation.
Faiss Vector Database GitHub: https://github.com/facebookresearch/faiss (opens in a new tab)

2. Annoy (Approximate Nearest Neighbors Oh Yeah)
- Prix de départ: Gratuit (Open-Source)
- Note: 4,5/5
- Avantages:
- Utilise une forêt d'arbres pour partitionner l'espace vectoriel
- Prise en charge des fichiers mappés en mémoire pour les données à grande échelle
- Complexité asymptotique des requêtes de l'ordre de (O(\log N))
- Inconvénients:
- Limité aux distances angulaires, euclidiennes, de Manhattan et de Hamming
- Pas de prise en charge native du calcul distribué
Détails techniques: Annoy Vector Database (opens in a new tab) construit un arbre binaire pour chaque vecteur, partitionnant ainsi l'espace en demi-espaces. Les arbres sont ensuite utilisés pour une recherche efficace des voisins les plus proches. Il prend également en charge des temps de construction multithreadés et permet de sauvegarder les index sur disque, qui peuvent être mappés en mémoire ultérieurement pour des recherches de similarité à grande échelle.
Annoy Vector Database GitHub: https://github.com/spotify/annoy (opens in a new tab)
3. NMSLIB (Bibliothèque d'espaces non métriques)
- Prix de départ: Gratuit (Open-Source)
- Note: 4,6/5
- Avantages:
- Prend en charge de nombreux mesures de distance, telles que la similarité cosinus, Jaccard et Levenshtein
- Utilise des graphes hiérarchiques navigables de petite taille (HNSW) pour une recherche efficace
- Optimisé pour les vecteurs de données denses et peu denses
- Inconvénients:
- Courbe d'apprentissage abrupte en raison des nombreuses options algorithmiques
- Support communautaire et documentation limités
Détails techniques: NMSLIB Vector Database (opens in a new tab) utilise des algorithmes avancés tels que les VP-trees, les SW-graphs et le HNSW pour l'indexation. Il prend également en charge la recherche des voisins les plus proches approximatifs (ANN), permettant un équilibre entre les performances de requête et la précision. La bibliothèque est optimisée pour des performances à faible latence et à haut débit, ce qui la rend adaptée aux applications en temps réel.
NMSLIB Vector Database GitHub: https://github.com/nmslib/nmslib (opens in a new tab)
Bases de données de vecteurs commerciales : en valent-elles la peine ?
4. Milvus
- Prix de départ: Gratuit (Open-Source)
- Note: 4,2/5
- Avantages:
- Scalabilité: Gère jusqu'à 100 milliards de vecteurs avec une latence sub-seconde.
- Mesures de distance: Prise en charge des mesures de distance euclidienne, cosinus et Jaccard. Prise en charge des types d'index tels que IVF_FLAT, IVF_PQ et HNSW.
- Inconvénients:
- Types de données: Pas de prise en charge des types géospatiaux et datetime.
- Sauvegarde: Pas de système de sauvegarde intégré.
- Authentification: Fonctionnalités de sécurité incohérentes.
- Nécessite des composants supplémentaires tels que MySQL ou SQLite pour le stockage des métadonnées
- Support limité des transactions, peu adapté aux applications conformes ACID
Avantages de Milvus: Milvus est conçu pour les environnements cloud-native et prend en charge la mise à l'échelle horizontale. Il utilise un système d'index hybride, combinant des méthodes d'indexation basées sur des arbres et des hachages pour une récupération efficace des données. Le système prend également en charge la taille des vecteurs et le filtrage des requêtes pour des conditions de recherche plus complexes.
Inconvénients de Milvus: Bien que Milvus soit open-source et scalable, il présente des limites. Il ne prend pas en charge les types de données avancés tels que les types géospatiaux et datetime. Il s'agit d'une lacune importante pour les applications en SIG et en analyse de séries temporelles. Il n'y a pas non plus de système de sauvegarde intégré, ce qui constitue un défaut critique. La mise en œuvre incohérente de fonctionnalités de sécurité telles que OAuth et LDAP est une autre préoccupation.

5. Pinecone
- Prix de départ: À partir de 30 $/mois
- Note: 3,9/5
- Avantages:
- Service entièrement géré
- Fonctionnalités intégrées de versioning et de rollback des données
- Prise en charge de la multi-tenance
- Inconvénients:
- Coût: Le coût peut rapidement augmenter pour les déploiements plus importants, ce qui peut être exponentiel avec la taille des données.
- Fonctionnalités limitées: Pas de jointures, de transactions ou d'indexation avancée.
- Documentation: Documentation technique limitée.
- Personnalisation limitée en raison de la nature gérée
Avantages de Pinecone: Pinecone utilise un algorithme propriétaire d'indexation vectorielle optimisé pour les vecteurs denses et peu denses. Il utilise une architecture distribuée et partitionnée pour la mise à l'échelle et offre des API RESTful pour une intégration facile. Cependant, le manque d'accès au code source peut limiter les personnes souhaitant étendre ou personnaliser ses fonctionnalités.
Inconvénients de Pinecone: La nature commerciale de Pinecone a un coût élevé, en particulier pour les grands ensembles de données. Il ne prend pas en charge les jointures et les transactions, qui sont essentielles pour les opérations complexes sur les données. La documentation technique limitée est un signal d'alarme, suggérant que le produit pourrait ne pas être à la hauteur de sa promotion.

6. Zilliz
- Prix de départ: Tarification sur mesure
- Note: 3,7/5
- Avantages:
- API REST : Intégration facile avec les applications existantes.
- Recherche d'attributs : Opérations de recherche d'attributs de base prises en charge.
- Basé sur le cloud : Évolutivité sans surcharge opérationnelle.
- Inconvénients :
- Coût : Tarification exponentielle en fonction de la taille des données.
- Fonctionnalités limitées : Pas de jointures, de transactions ou d'indexation avancée.
- Documentation : Documentation technique limitée.
- Absence de types de données avancés comme les données géospatiales et les dates.
Avantages de Zilliz : Zilliz utilise divers algorithmes d'indexation, notamment IVF_SQ8 et NSG, et prend en charge l'accélération GPU pour un traitement plus rapide des requêtes. Il offre également un langage de requête similaire à SQL, permettant des conditions de recherche plus complexes. Cependant, le manque de transparence de ses fonctionnalités de haute disponibilité soulève des questions sur sa pertinence pour les applications critiques.
Inconvénients de Zilliz : Zilliz manque de fonctionnalités essentielles telles que les jointures et les transactions, ce qui le rend peu fiable pour les applications sérieuses. L'absence de fonctionnalités de haute disponibilité, telles que la réplication des données et la bascule automatique, est un risque. Le système de sauvegarde est insuffisant, nécessitant des ressources supplémentaires pour la récupération des données.

Comment évaluer les bases de données vectorielles
Lors de l'évaluation des bases de données vectorielles, prenez en compte les aspects techniques suivants :
- Ensemble de fonctionnalités : Prise en charge des jointures, des transactions et des types de données avancés.
- Évolutivité : Peut-il gérer efficacement des données à grande échelle ?
- Coût : Comment évolue la tarification en fonction des fonctionnalités offertes ?
- Support de la communauté : Y a-t-il un soutien actif de la communauté et une documentation étendue ?
- Benchmarks : Utilisez des benchmarks de performance tels que les requêtes par seconde (QPS), la latence et le débit pour la comparaison.
Pour plus de détails, vous pouvez exécuter les outils fournis par ce dépôt GitHub (opens in a new tab) comme référence pour les bases de données vectorielles.
Les meilleures alternatives de bases de données vectorielles open-source en 2023
7. Qdrant : Le choix de la communauté
- Prix de départ : Gratuit (Open Source)
- Évaluation : 4,5/5
Avantages :
- Local et basé sur le cloud : Offre les deux options de déploiement, vous offrant ainsi une flexibilité.
- Mode In-Memory : Permet de tester sans lancement de conteneur.
- Facilité de migration : Experiencing a lot of migrations from other tools.
Inconvénients :
- Documentation : Pourrait bénéficier de guides plus complets.
- Taille de la communauté : Communauté plus petite par rapport à d'autres options open-source.
- Ensemble de fonctionnalités : En pleine croissance et peut manquer de certaines fonctionnalités avancées.
Détails techniques : Qdrant (opens in a new tab) offre à la fois des options locales et basées sur le cloud, ce qui en fait un choix flexible. Cependant, il a une communauté plus petite et pourrait bénéficier d'une documentation plus complète. Bien qu'il gagne en popularité, l'ensemble de fonctionnalités est encore en cours de développement et peut manquer de certaines options avancées.
Lien Qdrant : https://qdrant.tech/ (opens in a new tab)

8. Cassandra/AstraDB : Le roi de la scalabilité
Prix de départ : Niveau gratuit disponible Évaluation : 4,3/5
Avantages :
- Scalabilité : Réputation de gérer un débit massif sans s'effondrer.
- Local et basé sur le cloud : Les deux options de déploiement sont disponibles.
- Reconnaissance de l'industrie : A conservé sa position dans l'industrie pendant des années.
Inconvénients :
- Complexité : Courbe d'apprentissage plus abrupte pour les nouveaux utilisateurs.
- Coût : La version gratuite a ses limitations et la tarification peut augmenter.
- Support vectoriel : Pas initialement conçu pour les données vectorielles, donc certaines fonctionnalités peuvent manquer.
Détails techniques : Apache Cassandra (opens in a new tab)/DataStax AstraDB (opens in a new tab) est excellent pour la scalabilité, mais présente une courbe d'apprentissage plus abrupte. Bien qu'il propose une version gratuite, les limitations peuvent être rapidement atteintes, entraînant des coûts en hausse. Il n'a pas été initialement conçu pour les données vectorielles, donc il peut manquer de certaines fonctionnalités spécialisées.
Apache Cassandra : https://cassandra.apache.org (opens in a new tab) DataStax AstraDB : https://www.datastax.com/products/datastax-astra (opens in a new tab)

9. MyScale DB : La compilation SQL comme alternative à Pinecone
Prix de départ : Généreuse version gratuite Évaluation : 4,1/5
Avantages :
- Prise en charge SQL : Prise en charge SQL complète et étendue pour toutes les opérations de données.
- Vitesse : Architecture de base de données OLAP native du cloud pour des opérations rapides.
- Données structurées et vectorisées : Gère les deux dans une seule base de données.
Inconvénients :
- Nouveau venu : Relativement nouveau et peut manquer de soutien de la communauté.
- Documentation : Pourrait bénéficier de guides techniques supplémentaires.
- Complexité : La connaissance de SQL est indispensable, ce qui peut ne pas convenir à tous les utilisateurs.
Détails techniques : MyScale DB (opens in a new tab) propose une version gratuite généreuse et une prise en charge SQL complète, ce qui en fait un choix solide pour ceux qui pratiquent SQL. Cependant, en tant que produit relativement nouveau, il peut manquer d'un soutien communautaire étendu et pourrait bénéficier de plus de documentation technique.
MyScale DB : https://myscale.com (opens in a new tab)
10. SPTAG (Space Partition Tree and Graph)
- Prix de départ : Gratuit (Open Source)
- Évaluation : 4,3/5
- Avantages :
- Développé par Microsoft, garantissant un certain niveau de fiabilité
- Capacités de recherche k-NN à grande vitesse
- Optimisé pour les bases de données à grande échelle avec des milliards de vecteurs
- Inconvénients :
- Support de la communauté limité
- Documentation pas aussi approfondie que d'autres options open-source Détails techniques : SPTAG (opens in a new tab) utilise des KD-trees et des Ball trees pour l'indexation, permettant des recherches k-NN rapides. Il est optimisé pour les bases de données à grande échelle et peut gérer efficacement des milliards de vecteurs. L'algorithme prend également en charge la recherche multi-thread et le traitement de requêtes par lots.
SPTAG GitHub : https://github.com/microsoft/SPTAG (opens in a new tab)
FAQ
Quelles sont les principales bases de données de vecteurs ?
Les principales bases de données de vecteurs en 2023 comprennent Faiss, Annoy, NMSLIB, Milvus, Pinecone, Zilliz, Elasticsearch, Weaviate, Jina et SPTAG.
Est-ce qu'il existe une base de données de vecteurs gratuite ?
Oui, il existe plusieurs bases de données de vecteurs gratuites et open source disponibles, telles que Faiss, Annoy, NMSLIB, Milvus, Weaviate, Jina et SPTAG.
Est-ce que Pinecone est la meilleure base de données de vecteurs ?
Bien que Pinecone offre un service entièrement géré et facile à utiliser, savoir si c'est la "meilleure" dépend de vos besoins spécifiques. Il n'est pas open source et peut être coûteux pour les déploiements plus importants.
Comment choisir une base de données de vecteurs ?
Le choix d'une base de données de vecteurs dépend de divers facteurs tels que le type de données avec lesquelles vous travaillez, l'échelle de votre projet et votre budget. Des options open source comme Faiss et Annoy sont excellentes pour ceux qui veulent plus de contrôle et de personnalisation, tandis que des services gérés comme Pinecone peuvent être plus adaptés à ceux qui recherchent une facilité d'utilisation.
Conclusion
Les bases de données de vecteurs sont un outil essentiel pour la manipulation de données complexes et de haute dimension. Bien qu'elles offrent de nombreux avantages tels qu'une recherche de similarité efficace et une mise à l'échelle, elles présentent également leurs propres limitations. Des options open source comme Faiss et Annoy offrent d'excellentes performances et une grande flexibilité, mais peuvent nécessiter une courbe d'apprentissage abrupte. En revanche, des options commerciales comme Pinecone offrent une facilité d'utilisation mais peuvent être coûteuses. Il est donc crucial de peser soigneusement les avantages et les inconvénients pour choisir la base de données de vecteurs qui convient le mieux à vos besoins.
Vous voulez connaître les dernières actualités de LLM ? Consultez le dernier classement LLM !
