OpenVoice: 로컬 및 클라우드 배포를 위한 즉시 음성 복제
- Name
- Jennie Rose
Published on
음성 합성 기술이 급속하게 발전하는 상황에서, OpenVoice는 다양한 응용 프로그램에 맞는 다용도의 즉시 음성 복제 기능을 제공하여 게임 체인저로 등장하였습니다. MyShell 팀에서 개발한 오픈소스 솔루션인 OpenVoice는 짧은 오디오 클립만으로 화자의 음성을 복제하여 다양한 언어로 현실적이고 사용자 정의 가능한 음성을 생성할 수 있습니다.
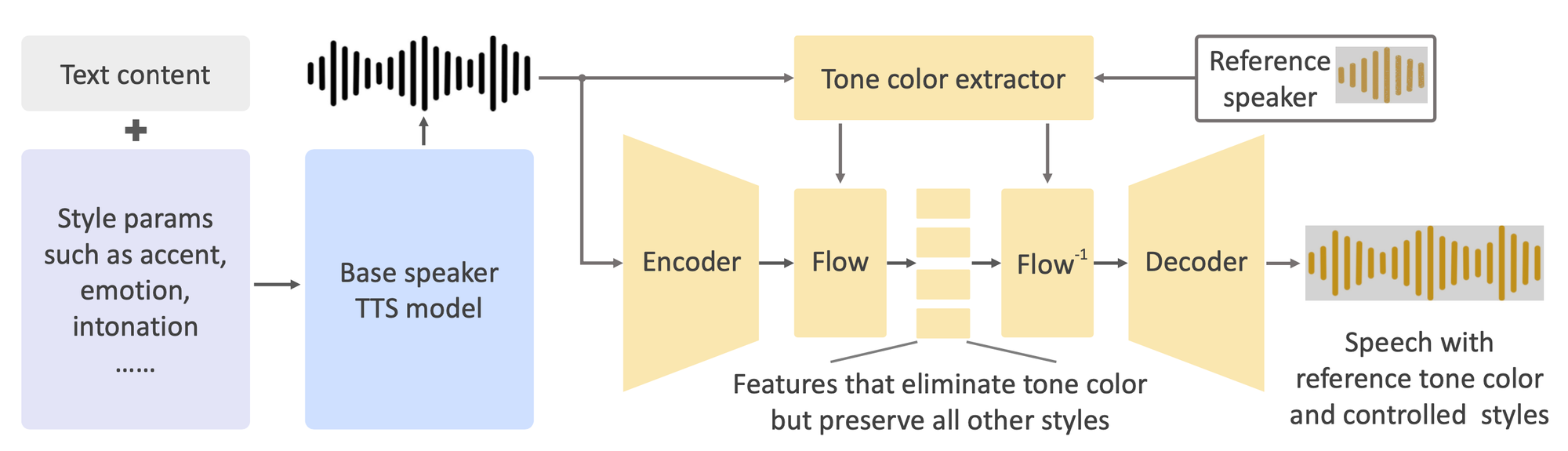
OpenVoice의 주요 기능
OpenVoice는 다른 음성 복제 솔루션과 구별되는 다양한 기능을 자랑합니다:
-
정확한 음색 복제 : OpenVoice는 참조 화자의 음색을 정확하게 복제하여 생성된 음성이 원본 음성과 유사하게 만듭니다. 이 기능은 오디오북 내레이션이나 개인화된 가상 어시스턴트와 같이 고도의 신뢰성이 필요한 응용 프로그램에 특히 유용합니다.
-
유연한 음성 스타일 제어 : OpenVoice의 가장 탁월한 기능 중 하나는 다양한 음성 스타일 매개변수를 미세하게 조정할 수 있는 능력입니다. 사용자는 감정, 사투리, 리듬, 일시정지 및 억양과 같은 속성을 조정하여 다양한 표현 가능성을 확보할 수 있습니다. 이 유연성은 생성된 음성을 특정 맥락이나 사용자 선호에 맞게 맞춤화할 수 있도록 지원합니다.
-
제로샷 다국어 음성 복제 : OpenVoice는 훈련 데이터셋에 없던 언어로 음성을 생성할 수 있는 놀라운 제로샷 다국어 음성 복제 기능을 구현합니다. 이 기능을 통해 로컬화된 콘텐츠를 작성하거나 광범위한 언어군에 속한 사용자에게 다국어 음성을 제공하는 흥미로운 기회가 열립니다.

성능 기준
OpenVoice의 성능을 평가하기 위해 MyShell 팀은 다양한 GPU 구성에서 포괄적인 벤치마크를 수행하였습니다. 결과는 기타 텍스트 음성 변환 API에 비해 OpenVoice의 효율성과 비용 효과를 입증해줍니다.
| GPU | 초당 단어 수 | 달러 당 단어 수 |
|---|---|---|
| RTX 2070 | 132.7 | 6.6 백만 |
| RTX 3080 Ti | 230.4 | 4.53 백만 |
이 벤치마크에서는 RTX 2070 GPU가 1달러당 6.6 백만 단어를 처리할 수 있어 대규모 음성 복제 프로젝트에 매우 효과적인 비용 효율적인 옵션임을 보여줍니다. 반면에, RTX 3080 Ti는 최고의 처리 속도를 제공하여 초당 약 230.4 단어를 처리함으로써 빠른 처리 시간을 우선시하는 응용 프로그램에 적합합니다.
이 벤치마크는 단일 스레드 작업에 초점을 맞추었으며, RTX 3080 Ti와 같은 더 강력한 GPU에서의 멀티 스레딩 잠재력은 성능을 향상시키고 비용 대비 성능 차이를 줄일 수 있습니다.
OpenVoice 로컬 실행하기
OpenVoice의 중요한 장점 중 하나는 로컬에서 실행할 수 있는 기능을 제공하므로 외부 API에만 의존하는 것보다 더 큰 제어력, 개인 정보 보호 및 비용 절감을 제공합니다. 로컬 컴퓨터에서 OpenVoice를 설정하고 실행하는 단계별 안내는 다음과 같습니다:
-
전제 조건: 호환되는 GPU(NVIDIA GPU with CUDA support)와 Python, PyTorch, CUDA toolkit을 포함한 필요한 종속성이 설치되어 있는지 확인합니다.
-
저장소 복제: 공식 GitHub 페이지에서 OpenVoice 저장소를 다음 명령을 사용하여 복제합니다:
git clone https://github.com/myshell-ai/OpenVoice.git -
종속성 설치: 복제한 저장소 디렉토리로 이동하여 pip를 사용하여 필요한 Python 패키지를 설치합니다:
cd OpenVoice pip install -r requirements.txt -
모델 준비: 사전 훈련된 모델 체크포인트를 다운로드하고 저장소 내 지정된 디렉토리에 놓습니다. 체크포인트를 가져오는 구체적인 지침은 OpenVoice 문서에서 확인할 수 있습니다.
-
설정 구성: 설정 파일(config.json 또는 config.yaml)을 수정하여 원하는 설정(입력 오디오 형식, 출력 디렉토리 및 음성 스타일 매개변수 등)을 지정합니다.
-
음성 복제 실행: 로컬 컴퓨터에서 음성 복제를 수행하기 위해 주요 스크립트를 실행합니다. 참조 오디오 클립의 경로와 대상 텍스트를 인수로 제공합니다:
python main.py --reference_audio path/to/reference.wav --text "안녕하세요, 이것은 테스트입니다." -
결과 평가: 생성된 음성은 지정된 출력 디렉토리에 저장됩니다. 합성된 오디오를 듣고 품질, 자연성 및 참조 음성과의 유사성을 평가하세요. 원하는 결과를 얻기 위해 설정을 정확하게 조정하고 다양한 음성 스타일 매개변수를 실험해보세요.
OpenVoice를 로컬로 실행함으로써 외부 API에 의존하지 않고도 즉시 음성 복제의 힘을 활용할 수 있으며, 지연 시간을 줄이고 데이터 개인 정보를 보호할 수 있습니다. 이러한 로컬 배포 옵션은 엄격한 보안 요구사항이 있는 응용 프로그램이나 사용자가 음성 합성 파이프라인을 완전히 제어하고 싶은 경우에 특히 유용합니다.
결론
layout: post title: OpenVoice 소개 language: ko
OpenVoice는 음성 합성 분야에서의 중요한 단계를 나타내며, 탁월한 음성 복제 솔루션을 제공하여 실시간 음성 복제를 가능하게 합니다. 정확한 음조 복제, 유연한 음성 스타일 제어 및 제로샷 교차언어 기능으로, OpenVoice는 다국어로 현실적이고 표현력 있는 음성을 만들 수 있도록 사용자에게 도구를 제공합니다.
놀라운 성능 벤치마크는 OpenVoice의 비용 효율성과 효율성을 보여주며, 오디오북 나레이션과 개인화된 가상 어시스턴트, 그리고 로컬화된 콘텐츠 작성 등 다양한 응용 분야에 매력적인 선택이 됩니다.
뿐만 아니라, OpenVoice를 로컬에서 실행할 수 있는 기능은 사용자에게 더 큰 제어력, 개인 정보 보호 및 비용 절감을 제공하여, 클라우드 기반 API에 완전히 의존하지 않고도 음성 복제의 힘을 이용할 수 있습니다.
오픈 소스 커뮤니티가 OpenVoice의 개발과 정제에 기여하면서 음성 합성 분야에서 더 많은 진보와 혁신을 기대할 수 있습니다. OpenVoice의 다재다능함, 접근성 및 놀라운 기능을 통해 우리는 음성 콘텐츠를 상호 작용하며 만드는 방식을 혁신할 수 있을 것이며, 창작자, 개발자 및 기업에게 흥미로운 가능성을 열어줄 것입니다.