2023년 최고의 10가지 벡터 데이터베이스: 완전한 검토

벡터 데이터베이스는 이제 더 이상 데이터 과학자나 데이터베이스 관리자 사이에서만 토론되는 특정 주제가 아닙니다. 2023년에 우리가 들어서면서, 이미지, 오디오, 텍스트와 같은 복잡한 데이터 유형을 다루는 사람들에게 초점이 된 상황입니다. 하지만, 정확히 벡터 데이터베이스란 무엇이며, 왜 그들은 이렇게 많은 관심을 받고 있는 걸까요?
이 기사에서는 벡터 데이터베이스를 해체하고, 그들의 장단점을 밝혀내며, 그 주변으로 펼쳐진 흥겨움을 공개합니다. 또한, 2023년 최고의 9개 벡터 데이터베이스를 독점적으로 살펴보고, 특히 오픈 소스 옵션에 중점을 둘 것입니다. 그러면, 시작해봅시다!
최신 LLM 뉴스를 배우고 싶으신가요? 최신 LLM 리더보드를 확인해보세요!
벡터 데이터베이스란 무엇인가요?
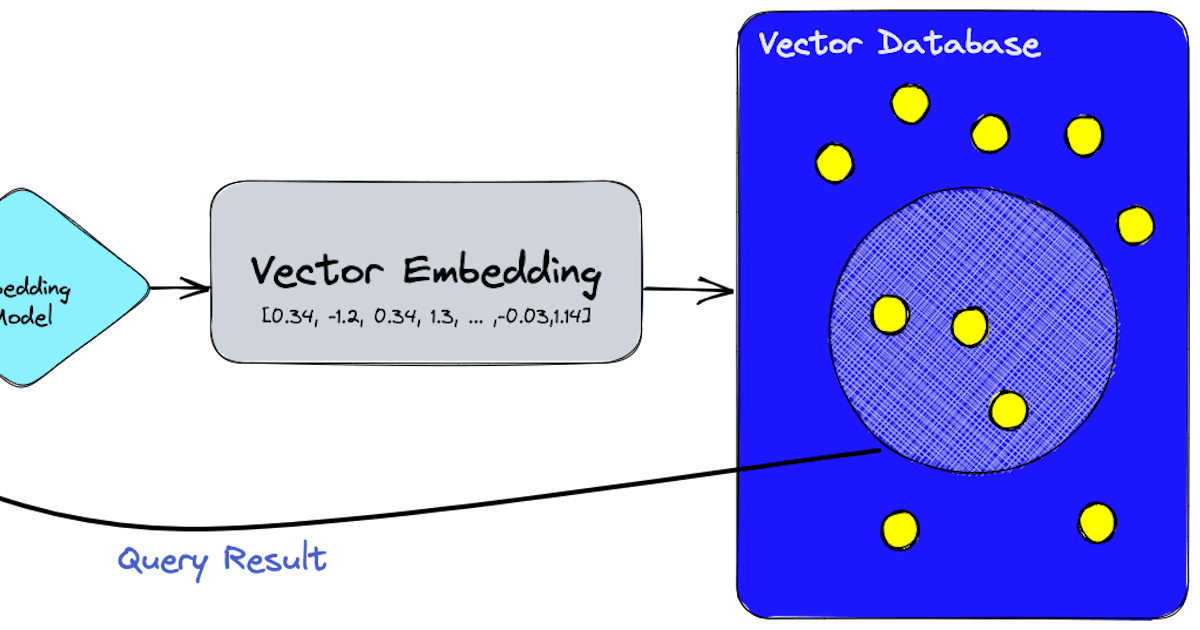
벡터 데이터베이스는 전통적인 데이터베이스가 어려움을 겪는 복잡한 데이터 유형을 처리하기 위해 특별히 설계된 특수한 유형의 데이터베이스입니다. 테이블에 데이터를 저장하는 기존의 관계형 데이터베이스와는 달리, 벡터 데이터베이스는 데이터를 표현하기 위해 수학적 벡터를 사용합니다. 이는 이미지, 오디오 파일, 텍스트 내용과 같은 고차원 데이터를 효율적으로 처리하고 검색할 수 있게 해줍니다.
벡터 데이터베이스는 k-NN (k-최근접 이웃)과 같은 알고리즘을 사용하여 고차원 데이터에서 검색을 수행합니다. 또한 양자화(quantization)와 파티셔닝(partitioning)과 같은 기법을 사용하여 검색 성능을 최적화합니다. 다음은 벡터 데이터베이스에서 유사한 이미지를 검색하기 위한 샘플 프롬프트입니다:
SELECT * FROM images WHERE VECTOR_SEARCH(image_vector, target_vector) < 0.2;이 샘플 프롬프트에서 VECTOR_SEARCH는 image_vector와 target_vector 사이의 유사도를 계산하는 함수입니다. < 0.2는 유사도 임계값을 지정합니다.
왜 벡터 데이터베이스가 다른가요?
-
고차원 데이터 처리: 전통적인 데이터베이스는 고차원 데이터를 처리하기에 적합하지 않습니다. 벡터 데이터베이스는 수학적 벡터를 사용하여 복잡한 데이터 유형을 다룸으로써 이 공백을 메꾸어 줍니다.
-
빠른 검색 기능: 벡터 데이터베이스의 중요한 특징 중 하나는 빠른 유사도 검색 기능입니다. 예를 들어, 이미지가 있는 경우 벡터 데이터베이스는 데이터베이스 내에서 각 항목을 스캔하지 않고도 유사한 이미지를 빠르게 찾아낼 수 있습니다.
-
확장성: 데이터가 증가함에 따라, 성능 저하 없이 확장할 수 있는 데이터베이스의 필요성이 중요해집니다. 벡터 데이터베이스는 확장성을 고려하여 설계되어 있으며, 대량의 데이터를 효율적으로 처리할 수 있습니다.
벡터 데이터베이스 검토: 흥이란 매칭되는가요?
모든 신흥 기술과 마찬가지로, 벡터 데이터베이스는 상당한 흥을 둘러싸고 있습니다. 많은 사람들은 그들이 데이터베이스 분야를 혼란스럽게 만들었던 NoSQL 움직임과 유사한 세대를 형성할 것이라 주장합니다. 하지만 이들 주장이 얼마나 사실일지, 어떤 점을 주의해야 할까요?
벡터 데이터베이스의 현실적인 진실: 적응해야 할까요?
흥은 완전히 근거가 있는 것은 아닙니다. 벡터 데이터베이스는 전통적인 데이터베이스와 비교하여 복잡한 고차원 데이터 처리와 같은 독특한 기능을 제공합니다. 하지만 보장되지 않은 것들과 구분하는 것이 중요합니다. 모든 벡터 데이터베이스가 흥에 부응하지는 않으며, 몇몇은 강력한 기능을 제공하는 것보다는 마케팅에 초점을 둔 경우도 있습니다.
벡터 데이터베이스 선택 시 주의해야 할 사항:
-
과대 광고와 미흡한 제공: 일부 벡터 데이터베이스는 고가용성, 백업 시스템, 지리적 공간 및 날짜 시간과 같은 고급 데이터 유형과 같은 중요한 기능을 충족시키지 못하고 있을 수 있습니다.
-
복잡성: 벡터 데이터베이스는 강력하지만 설정하고 관리하기에 복잡할 수도 있습니다. 기술적 전문성을 가지고 있다는 것을 확실히 하거나 교육에 투자할 준비를 해야합니다.
-
비용: 독자적인 데이터베이스의 경우, 숨겨진 비용에 유의해야 합니다. 라이선스 비용이 쌓일 수 있으며, 특수한 하드웨어에도 투자해야 할 수 있습니다.
이러한 사항을 인지함으로써, 흥을 탐색하고 더 자세한 결정을 내릴 수 있습니다. 마케팅 선동성을 뛰어넘고, 데이터베이스의 실제 기능과 제한 사항을 깊이 있게 탐구하는 것을 항상 기억하세요.
벡터 데이터베이스의 장점 대 단점
벡터 데이터베이스는 이미지, 오디오, 텍스트와 같은 복잡한 데이터 유형을 처리할 수 있는 능력으로 인해 인기를 얻고 있습니다. 그러나 그들의 장점과 한계를 모두 이해하는 것이 중요합니다.
벡터 데이터베이스의 장점:
-
효율적인 유사성 검색: 벡터 데이터베이스는 고차원 공간에서 최근접 이웃을 찾는 데 능숙하며, 이는 추천 시스템, 이미지 인식, 자연어 처리에 중요합니다.
-
확장성: 많은 벡터 데이터베이스는 대규모 데이터를 처리할 수 있도록 설계되었으며, 일부는 수평 확장을 위한 분산 아키텍처를 제공하기도 합니다.
-
유연성: 다양한 거리 측정 및 인덱싱 알고리즘을 지원함으로써, 벡터 데이터베이스는 특정한 유즈케이스에 매우 적응할 수 있습니다.
-
리소스 소비: 높은 속도의 검색은 종종 계산 리소스의 소비로 이어질 수 있습니다. 최적의 성능을 위해 일부 데이터베이스는 특수한 하드웨어가 필요할 수 있습니다.
벡터 데이터베이스의 단점:
- 복잡성: 다양한 알고리즘 옵션과 구성 때문에 벡터 데이터베이스는 설정 및 유지 관리가 어려울 수 있습니다.
- 비용: 오픈 소스 옵션이 있지만, 상용 벡터 데이터베이스는 특히 대규모 배포에 대해 비싸진다.
202년에 고려해야 할 상위 10개의 벡터 데이터베이스
2023년의 최고 오픈 소스 벡터 데이터베이스
1. Faiss
- 시작 가격: 무료 (오픈 소스)
- 평점: 4.7/5
- 장점:
- CUDA를 통한 뛰어난 GPU 가속화
- 수십억 개의 벡터 지원
- IVFADC, PQ, HNSW와 같은 다양한 알고리즘 옵션 제공
- 단점:
- 벡터 양자화에 대한 전문 지식 필요
- 단일 노드 배포에 제한적
기술적 세부 사항: Faiss (opens in a new tab)는 Inverted File Segmenter (IVF)와 Scalar Quantizer (SQ)를 포함한 다양한 인덱싱 기술을 사용하여 유사성 검색을 효율적으로 수행한다. 이는 배치 쿼리 처리와 다중 GPU 간 병렬화를 지원한다. 이 라이브러리는 L2 거리와 내적 유사성 모두에 최적화되어 있어 다양한 용도에 유연하게 사용할 수 있다.
Faiss 벡터 데이터베이스 GitHub: https://github.com/facebookresearch/faiss (opens in a new tab)

2. Annoy (근사 최근 이웃 좋지)
- 시작 가격: 무료 (오픈 소스)
- 평점: 4.5/5
- 장점:
- 벡터 공간을 분할하기 위해 트리 포레스트를 이용
- 대규모 데이터를 위한 메모리 맵 파일 지원
- 쿼리의 비용 복잡도는 O(log N)이다
- 단점:
- 각도, 유클리디안, 마하탄 및 해밍 거리 메트릭스에만 제한됨
- 분산 컴퓨팅을 위한 네이티브 지원이 없음
기술적 세부 사항: Annoy 벡터 데이터베이스 (opens in a new tab)는 각 벡터마다 이진 트리를 구축하여 공간을 절반으로 나누는 방식으로 사용되며, 효율적인 최근접 이웃 검색을 위해 트리를 활용한다. 또한 다중 스레드 빌드 시간을 지원하며, 대규모 유사성 검색을 위해 나중에 메모리 맵 파일로 로드할 수 있는 인덱스 저장 기능도 제공한다.
Annoy 벡터 데이터베이스 GitHub: https://github.com/spotify/annoy (opens in a new tab)
3. NMSLIB (비메트릭 공간 라이브러리)
- 시작 가격: 무료 (오픈 소스)
- 평점: 4.6/5
- 장점:
- 코사인, 자카드, 레벤슈타인과 같은 다양한 거리 메트릭스 지원
- 효율적인 검색을 위해 계층형 네비 검색을 활용
- 밀집 및 희박한 데이터 벡터 모두에 최적화
- 단점:
- 다양한 알고리즘 옵션으로 인해 학습 곡선이 가파름
- 제한된 커뮤니티 지원 및 문서화
기술적 세부 사항: NMSLIB 벡터 데이터베이스 (opens in a new tab)는 VP-트리, SW-그래프, HNSW와 같은 고급 알고리즘을 사용하여 인덱싱한다. 또한 근사 최근접 이웃 (ANN) 검색을 지원하여 쿼리 성능과 정확성 사이의 균형을 제공한다. 이 라이브러리는 실시간 애플리케이션에 적합한 저지연, 고처리량 성능을 최적화하였다.
NMSLIB 벡터 데이터베이스 GitHub: https://github.com/nmslib/nmslib (opens in a new tab)
상용 벡터 데이터베이스: 소문 값만 하는가?
4. Milvus
- 시작 가격: 무료 (오픈 소스)
- 평점: 4.2/5
- 장점:
- 확장성: 1000억 개의 벡터까지 초당 지연시간 안에 처리할 수 있다.
- 거리 메트릭스: 유클리디안, 코사인, 자카드 메트릭스를 지원한다. IVF_FLAT, IVF_PQ, HNSW와 같은 인덱스 유형을 지원한다.
- 단점:
- 데이터 유형: 지리 공간 및 일시 데이터 유형 지원이 없다.
- 백업: 내장된 백업 시스템 없음.
- 인증: 일관되지 않은 보안 기능.
- 메타데이터 저장을 위해 MySQL 또는 SQLite와 같은 추가 구성 요소가 필요함
- 트랜잭션 지원이 제한적으로 ACID 호환 애플리케이션에 적합하지 않음
Milvus의 장점: Milvus는 클라우드 원생 환경을 위해 설계되었으며 수평 확장을 지원한다. 효율적인 데이터 검색을 위해 트리 기반 및 해시 기반 인덱싱 방법을 결합한 하이브리드 인덱스 시스템을 채택하였다. 시스템은 벡터 가지치기와 쿼리 필터링을 지원하여 보다 복잡한 검색 조건을 처리할 수 있다.
Milvus의 단점: Milvus는 오픈 소스이면서 확장 가능하지만, 제약 사항도 있다. 지리 공간 및 일시와 같은 고급 데이터 유형을 지원하지 않는다. 이는 지리 정보 시스템(GIS) 및 시계열 분석과 같은 응용 프로그램에 있어서 큰 불편을 초래할 수 있다. 또한 내장된 백업 시스템이 없는 것은 중요한 결함이다. OAuth 및 LDAP와 같은 보안 기능구현의 일관성 또한 문제가 된다.

5. Pinecone
- 시작 가격: 30달러/월부터 시작
- 평점: 3.9/5
- 장점:
- 완전 관리형 서비스
- 내장된 데이터 버전 관리 및 롤백 기능
- 다중 테넌시 지원
- 단점:
- 비용: 대규모 배포에 비용이 빠르게 증가할 수 있으며, 데이터 크기에 따라 지수적으로 증가할 수 있다.
- 제한된 기능: 조인, 트랜잭션 또는 고급 인덱싱 지원이 없음.
- 문서화: 기술적 문서화가 부족함.
- 관리형 특성으로 인한 제한된 커스터마이징.
Pinecone의 장점: Pinecone은 밀집 및 희박한 벡터에 최적화된 독자적인 벡터 인덱싱 알고리즘을 사용한다. 확장성을 위해 분산 샤드 아키텍처를 사용하며, RESTful API를 제공하여 쉬운 통합을 지원한다. 하지만 소스 코드에 대한 접근이 없다는 점은 기능을 확장하거나 사용자 정의하는 데 제한이 될 수 있다.
Pinecone의 단점: Pinecone은 상용 제품이므로 대규모 데이터셋에 대해서는 높은 비용이 발생한다. 복잡한 데이터 작업을 위해 필수적인 조인과 트랜잭션을 지원하지 않는 점은 큰 제한이다. 기술적 문서화가 부족하므로 제품이 마케팅에 얼마나 잘 부응하는지를 알려주는 중요한 지표이다.

6. Zilliz
- 시작 가격: 맞춤 가격
- 평점: 3.7/5
- 장점:
- REST API: 기존 응용 프로그램과의 쉬운 통합이 가능합니다.
- 속성 검색: 기본 속성 검색 작업이 지원됩니다.
- 클라우드 기반: 운영 오버헤드 없이 확장성을 제공합니다.
- 단점:
- 비용: 데이터 크기에 따라 지수적인 가격이 책정됩니다.
- 기능 제한: 조인, 트랜잭션, 고급 인덱싱이 지원되지 않습니다.
- 문서: 기술 문서가 부족합니다.
- 지리 공간 및 날짜와 같은 고급 데이터 유형 부족이 있습니다.
Zilliz의 장점: Zilliz는 IVF_SQ8 및 NSG를 포함한 다양한 인덱싱 알고리즘을 사용하며, 더 빠른 쿼리 처리를 위해 GPU 가속화를 지원합니다. 또한 SQL과 유사한 쿼리 언어를 제공하여 복잡한 검색 조건을 지원합니다. 그러나 고가용성 기능의 투명성 부족으로 인해 미션 크리티컬 응용 프로그램에 적합한지에 대해 의문이 제기됩니다.
Zilliz의 단점: Zilliz는 조인과 트랜잭션이 없어 신뢰성이 없으므로 심각한 응용 프로그램에는 적합하지 않습니다. 데이터 복제와 자동 장애 조치와 같은 고가용성 기능이 없어 위험이 발생합니다. 백업 시스템이 부족하여 데이터 복구에 추가 리소스가 필요합니다.

벡터 데이터베이스 평가 방법
벡터 데이터베이스 평가 시 다음의 기술적 측면을 고려하세요:
- 기능 세트: 조인, 트랜잭션 및 고급 데이터 유형을 지원하는지 확인합니다.
- 확장성: 대규모 데이터를 효율적으로 처리할 수 있는지 확인합니다.
- 비용: 제공하는 기능에 따른 가격 책정 방식을 고려합니다.
- 커뮤니티 지원: 활발한 커뮤니티 지원과 포괄적인 문서가 있는지 확인합니다.
- 벤치마킹: 쿼리 수행량(QPS), 지연 시간 및 처리량과 같은 성능 벤치마크를 사용하여 비교합니다.
자세한 내용은 이 GitHub 저장소 (opens in a new tab)에서 제공하는 도구를 벡터 데이터베이스의 벤치마크로 사용할 수 있습니다.
2023년 최고의 오픈 소스 벡터 데이터베이스 대안
7. Qdrant: 커뮤니티의 선택
- 시작 가격: 무료 (오픈 소스)
- 평가: 4.5/5
장점:
- 로컬 및 클라우드 기반: 유연성을 제공하기 위해 두 가지 배포 옵션이 모두 제공됩니다.
- 인메모리 모드: 컨테이너를 생성하지 않고 테스트할 수 있습니다.
- 이전 도구로의 마이그레이션: 다른 도구에서의 다양한 이전 작업을 경험하고 있습니다.
단점:
- 문서: 보다 포괄적인 가이드가 필요할 수 있습니다.
- 커뮤니티 규모: 다른 오픈 소스 옵션에 비해 커뮤니티 규모가 작을 수 있습니다.
- 기능 세트: 계속 성장 중이며 일부 고급 기능이 부족할 수 있습니다.
기술 세부 사항: Qdrant (opens in a new tab)는 로컬 및 클라우드 기반 옵션을 모두 제공하여 유연한 선택이 가능합니다. 그러나 커뮤니티 규모가 상대적으로 작고, 보다 포괄적인 문서화가 필요할 수 있습니다. 인기를 얻고 있지만 기능 세트는 여전히 성장 중이며 일부 고급 옵션이 부족할 수 있습니다.
Qdrant 링크: https://qdrant.tech/ (opens in a new tab)

8. Cassandra/AstraDB: 확장성의 왕
시작 가격: 무료 티어 사용 가능 평가: 4.3/5
장점:
- 확장성: 높은 처리량을 유지하면서 확장성이 우수합니다.
- 로컬 및 클라우드 기반: 두 가지 배포 옵션이 모두 제공됩니다.
- 산업 인식: 여러 해 동안 산업에서 위치를 유지하고 있습니다.
단점:
- 복잡성: 새로운 사용자에게는 학습 곡선이 가파릅니다.
- 비용: 무료 티어에는 제한이 있으며, 가격이 상승할 수 있습니다.
- 벡터 지원: 원래 벡터 데이터를 위해 설계되지 않았으므로 일부 기능이 부족할 수 있습니다.
기술 세부 사항: Apache Cassandra (opens in a new tab)/DataStax AstraDB (opens in a new tab)는 확장성이 우수하지만 학습 곡선이 가파르게 나타납니다. 무료 티어를 제공하지만 제한에 빠르게 도달하여 비용이 상승할 수 있습니다. 또한 벡터 데이터를 위해 원래 설계되지 않았으므로 특화된 기능이 일부 부족할 수 있습니다.
Apache Cassandra: https://cassandra.apache.org (opens in a new tab) DataStax AstraDB: https://www.datastax.com/products/datastax-astra (opens in a new tab)

9. MyScale DB: Pinecone 대체제로서의 SQL 파워하우스
시작 가격: 대규모 무료 티어 제공 평가: 4.1/5
장점:
- SQL 지원: 모든 데이터 작업에 대한 완전하고 확장된 SQL 지원이 제공됩니다.
- 속도: 빠른 작업을 위한 클라우드 기반 OLAP 데이터베이스 구조입니다.
- 구조화된 및 벡터화된 데이터: 하나의 데이터베이스에서 둘 다 관리합니다.
단점:
- 신생 제품: 상대적으로 신제품이며 커뮤니티 지원이 부족할 수 있습니다.
- 문서: 더 많은 기술 가이드가 필요할 수 있습니다.
- 복잡성: 일부 사용자에게는 SQL 지식이 필요한데, 모든 사용자에게 적합하지 않을 수 있습니다.
기술 세부 사항: MyScale DB (opens in a new tab)는 대규모 무료 티어와 완전한 SQL 지원을 제공하여 SQL에 익숙한 사용자에게 강력한 선택지입니다. 그러나 상대적으로 신제품이며 커뮤니티 지원이 제한적일 수 있으며, 보다 기술적인 문서화가 필요할 수 있습니다.
MyScale DB: https://myscale.com (opens in a new tab)
10. SPTAG (Space Partition Tree and Graph)
- 시작 가격: 무료 (오픈 소스)
- 평가: 4.3/5
- 장점:
- Microsoft에서 개발하여 신뢰성이 보장됩니다.
- 빠른 k-NN 검색 기능을 제공합니다.
- 수십억 벡터로 대규모 데이터에 최적화되었습니다.
- 단점:
- 제한된 커뮤니티 지원
- 기타 오픈 소스 옵션보다 문서가 덜 다듬어졌습니다. 기술적 세부 정보: SPTAG (opens in a new tab)은 KD 트리 및 Ball 트리를 사용하여 인덱싱하여 고속 k-NN 검색을 가능하게 합니다. 대규모 데이터베이스에 최적화되어 있으며 수십억 개의 벡터도 효율적으로 처리할 수 있습니다. 이 알고리즘은 멀티 스레드 검색 및 일괄 쿼리 처리도 지원합니다.
SPTAG GitHub: https://github.com/microsoft/SPTAG (opens in a new tab)
자주하는 질문
주요 벡터 데이터베이스는 무엇인가요?
주요 벡터 데이터베이스는 2023년 기준으로 Faiss, Annoy, NMSLIB, Milvus, Pinecone, Zilliz, Elasticsearch, Weaviate, Jina 및 SPTAG가 포함됩니다.
무료 벡터 데이터베이스가 있나요?
네, Faiss, Annoy, NMSLIB, Milvus, Weaviate, Jina, SPTAG 등과 같은 몇 가지 무료 오픈 소스 벡터 데이터베이스가 있습니다.
Pinecone이 최고의 벡터 DB인가요?
Pinecone은 완전히 관리되는 서비스를 제공하고 사용이 쉽지만, "최고"인지는 특정 요구에 따라 다릅니다. Pinecone은 오픈 소스가 아니며 대규모 배포에는 비용이 많이 들 수 있습니다.
어떻게 벡터 데이터베이스를 선택하나요?
벡터 데이터베이스를 선택하는 것은 작업하는 데이터 유형, 프로젝트의 규모 및 예산과 같은 다양한 요인에 따라 달라집니다. Faiss 및 Annoy와 같은 오픈 소스 옵션은 더 많은 제어와 맞춤 설정이 필요한 경우에 훌륭한 선택지입니다. Pinecone과 같은 관리형 서비스는 사용이 간편하게 제공되지만, 사용 편의성을 원하는 경우에는 더 적합할 수 있습니다.
결론
벡터 데이터베이스는 복잡한 고차원 데이터를 처리하는 데 필수적인 도구입니다. 유사성 검색 및 확장성과 같은 여러 가지 이점을 제공하지만, 각각의 제약 사항도 있습니다. Faiss 및 Annoy와 같은 오픈 소스 옵션은 우수한 성능과 유연성을 제공하지만 높은 학습 곡선을 요구할 수 있습니다. 반면 Pinecone과 같은 상용 옵션은 사용이 간편하지만 비용이 발생할 수 있습니다. 따라서 필요에 가장 적합한 벡터 데이터베이스를 선택하기 위해 장단점을 신중하게 고려하는 것이 중요합니다.
최신 LLM 뉴스를 알고 싶나요? 최신 LLM 리더보드를 확인하세요!
