로컬에서 Mistral 모델 실행하는 방법 - 완전한 가이드

인공지능 (AI)의 변화가 빠르게 진전되는 이 시대에 Mistral AI는 대단원의 혁신을 이루며 대규모 언어 모델 (LLM)의 범주에서 새로운 영토를 개척하고 있습니다. Mistral AI의 혁신적인 모델을 소개함으로써 Mistral AI는 기계 학습의 한계를 뛰어넘을 뿐만 아니라 첨단 기술에 대한 접근성을 더욱 높였습니다. 본 가이드는 Mistral AI의 서비스의 복잡성을 명확히 하고 로컬에서 해당 기능을 활용하기 위한 포괄적인 로드맵을 제공하고 있습니다.
이 Mistral AI 모델들이란 무엇인가요?
Mistral AI는 단순한 개선이 아닌 계산 언어학의 큰 도약이라 할 수 있는 언어 모델을 공개하였습니다. 이 모델 집합의 핵심에는 다양한 요구와 계산 가능성에 대응하는 Mistral 7B 및 Mistral 8x7B가 있습니다.
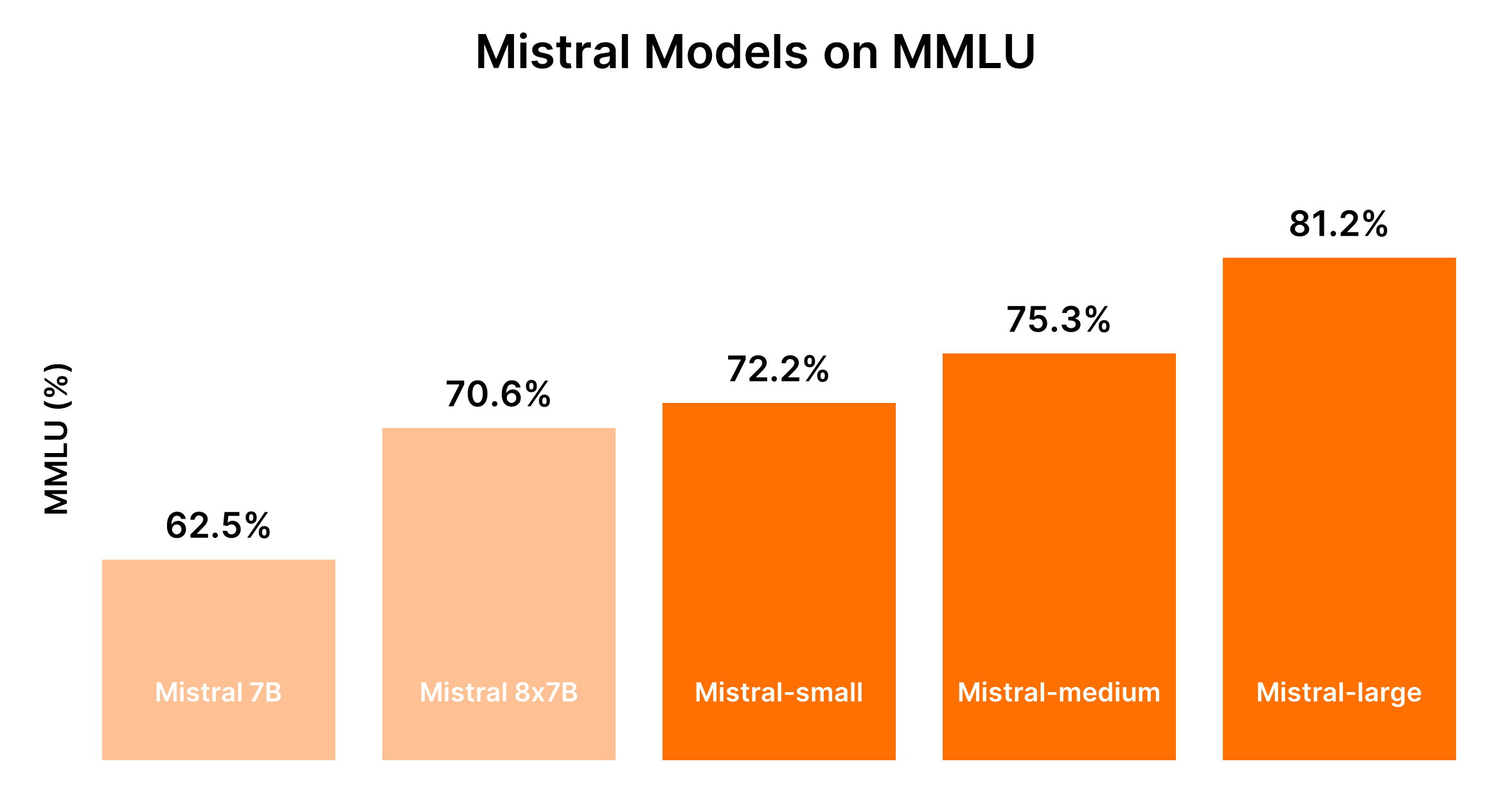
Mistral AI 모델 비교 (Mistral 7B vs Mistral 8x7b vs Mistral Small vs Mistral Medium vs Mistral Large)
알겠습니다. 제공된 입력을 기반으로 정리된 비교 분석을 위한 마크다운 형식의 표를 생성하기 위해, Mistral AI 모델들의 비교 분석을 구조화하는 방법에 대해 의논해 봅시다.
Mistral AI 모델의 비교 분석
Mistral AI는 간단한 대량 작업에서 복잡한 추론 기능까지 다양한 용도에 맞는 모델들을 제공하고 있습니다. 다음은 명확한 이해를 위해 마크다운 형식으로 작성된 비교 분석 및 성능 출력입니다.
모델 개요 및 사용 사례
| 모델 ID | Alias | 사용 사례 |
|---|---|---|
| open-mistral-7b | mistral-tiny-2312 | 분류, 고객 지원, 또는 텍스트 생성과 같은 간단한 대량 작업 |
| open-mixtral-8x7b | mistral-small-2312 | open-mistral-7b와 비슷하며 간단한 대량 작업에 적합합니다 |
| mistral-small-latest | mistral-small-2402 | 최소한의 추론 기능이 필요한 약간 복잡한 작업 |
| mistral-medium-latest | mistral-medium-2312 | 데이터 추출, 요약 문서, 이메일 작성과 같은 중간 작업 |
| mistral-large-latest | mistral-large-2402 | 합성 텍스트 생성, 코드 생성과 같이 큰 추론 능력이 필요한 복잡한 작업 |
성능과 비용의 대조
Mistral 모델의 성능은 일반적으로 모델의 크기와 비례적이며, 더 큰 모델은 향상된 기능을 제공하지만 더 높은 비용이 발생합니다. 다음 표는 MMLU 벤치마크와 일반적인 비용 고려사항을 기반으로 한 성능 순위를 요약한 것입니다.
| 모델 | 성능 순위 | 비용 고려사항 |
|---|---|---|
| Mistral 7B (tiny-2312) | 5위 | 간단한 작업에 가장 비용 효율적입니다 |
| Mixtral 8x7B (small-2312) | 4위 | 대량의 간단한 작업에 효율적인 비용입니다 |
| Mistral Small (small-2402) | 3위 | 약간의 추론이 필요한 작업에 적합한 비용입니다 |
| Mistral Medium (medium-2312) | 2위 | 중간 작업에 균형 잡힌 성능과 높은 비용입니다 |
| Mistral Large (large-2402) | 1위 | 복잡한 작업에 매우 높은 성능과 비용입니다 |
LLM 성능과 관련 비용의 동적인 특성을 감안하여 가장 정확한 비교를 위해 현재 벤치마크와 가격 정보를 참고하는 것이 좋습니다. 최신 벤치마크 및 성능 정보를 얻기 위해 Hugging Face의 Chatbot Arena Leaderboard (opens in a new tab) 및 Artificial Analysis (opens in a new tab)와 같은 플랫폼은 가치 있는 정보를 제공할 수 있습니다.
결정 가이드: 어떤 Mistral AI 모델을 선택해야 할까요?
적절한 모델을 선택하기 위해서는 성능 요구 사항을 비용 제약 조건과 균형을 이루는 것이 중요하며, 애플리케이션이 처리할 작업의 복잡성을 고려해야 합니다.
- 간단한 작업에 대해서: 비용 효과적인 Mistral Small 또는 Mistral 7B에서 시작하세요.
- 중간부터 복잡한 작업에 대해서: Mistral Medium 또는 Mistral Large의 성능 향상이 특정 애플리케이션 요구 사항에 따른 추가 비용을 보상하는지 평가하세요.
이 구조화된 비교는 Mistral AI의 모델 제공에서 기능 요구 사항과 예산 제약 사항을 모두 고려하여 결정을 내릴 때 도움을 주기 위해 제공됩니다.

파트 1. 편리한 방법으로 Ollama를 사용하여 로컬에서 Mistral 실행하는 방법
Ollama를 사용하여 로컬에서 Mistral AI 모델을 실행하는 것은 클라우드 서비스에 의존하지 않고도 고급 LLM의 능력을 자신의 기기에서 쉽게 사용할 수 있는 접근 가능한 방법입니다. 이 방법은 인공지능 기반 텍스트 분석, 생성 등을 실험하려는 개발자, 연구자 및 열정적인 사용자에게 이상적입니다. 아래는 시작하는 데 필요한 간결한 안내서입니다:
단계 1: Ollama 다운로드
- Ollama 다운로드 페이지를 방문하고 사용 중인 운영 체제에 해당하는 버전을 선택합니다. macOS 사용자는
.dmg파일을 다운로드합니다. - 다운로드한 파일을
/Applications디렉터리로 드래그하여 Ollama를 설치합니다.
단계 2: Ollama 명령 탐색
터미널을 열고 `ollama`를 입력하여 사용 가능한 명령어 목록을 확인합니다. `serve`, `create`, `show`, `run`, `pull` 등과 같은 옵션을 볼 수 있습니다.
### 3단계: Mistral AI 설치하기
Mistral AI 모델을 설치하려면 먼저 설치하려는 모델을 찾아야 합니다. Mistral:instruct 버전에 관심이 있다면 직접 설치하거나 이미 설치되어 있지 않다면 다운로드할 수 있습니다.
- 직접 실행하고 (필요한 경우 다운로드):
```bash
ollama run mistral:instruct- 모델 사전 다운로드하기:
ollama pull mistral:instruct
4단계: Mistral AI와 상호 작용하기
모델이 설치되면 대화형 모드나 직접 입력을 통해 모델과 상호 작용할 수 있습니다.
-
대화형 모드에서 실행하기:
ollama run mistral --verbose그런 다음 프롬프트에 따라 질의를 입력하세요.
-
비대화형 모드에서 실행하기 (직접 입력):
bbc.txt에 요약하려는 기사가 저장되어 있다고 가정해봅시다. 기사 내용을 바로 Mistral에 전달하여 요약할 수 있습니다:ollama run mistral --verbose "Please can you summarise this article: $(cat bbc.txt)""Please can you summarise this article: $(cat bbc.txt)"를 작업과 관련된 적절한 프롬프트로 바꿔주세요.
샘플 출력 분석
터미널에는 모델의 출력이 표시됩니다. 이는 요약이나 프롬프트에 대한 응답을 포함합니다. Mistral이 복잡한 질의를 처리하고 이해하며, 정확성에 관한 프롬프트에 응답할 때 수정 사항을 제안하는 방식은 매우 흥미로운 점입니다.
HTTP API를 통한 Mistral AI 실행하기
Ollama는 HTTP API도 지원하므로 모델과 프로그래밍 방식으로 상호 작용할 수 있습니다.
- 예시
curl요청:curl -X POST http://localhost:11434/api/generate -d '{ "model": "mistral", "prompt": "What is the sentiment of this sentence: The situation surrounding the video assistant referee is at crisis point." }'
이 방법은 JSON 응답을 출력하므로 프로그래밍 방식으로 파싱할 수 있으며, Mistral AI의 기능을 애플리케이션에 유연하게 통합하는 방법을 제공합니다.
로컬 머신에서 Ollama와 함께 Mistral AI를 실행하면 개인 프로젝트, 개발 및 연구에서 AI를 활용하는 데 많은 가능성이 열립니다. 설치와 사용의 편의성, Mistral의 LLM의 성능을 결합한 이 방법은 AI 기술의 최전선을 탐색하고자 하는 모든 분들에게 매력적인 선택지입니다.
2부. Windows에서 Mistral 7B를 로컬에서 실행하는 방법
Mistral 7B는 HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart 및 Baseten을 비롯한 여러 플랫폼을 통해 액세스할 수 있습니다. Kaggle의 "모델" 기능도 모델이나 데이터셋을 다운로드할 필요 없이 몇 분 내에 추론 또는 세부 조정으로 시작할 수 있는 간소화된 접근 방식을 제공합니다.
Mistral 7B 접근을 위한 전제 조건
시작하기 전에 환경이 최신 상태인지 확인하여 KeyError: 'mistral'과 같은 일반적인 오류를 피하십시오:
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytes4비트 양자화 구현
모델 로딩 속도를 빠르게 하고 메모리 사용량을 줄이기 위해 4비트 양자화를 사용합니다:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Kaggle 노트북에서 Mistral 7B 로드하기
Kaggle 노트북을 통해 Mistral 7B를 간단한 UI 상호 작용을 통해 추가할 수 있습니다. 적절한 모델 변형과 버전을 선택한 후, 모델과 토크나이저를 쉽게 로드할 수 있습니다:
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)pipeline 함수를 사용하면 주어진 프롬프트에 기반한 응답 생성 과정을 간소화할 수 있습니다.
샘플 추론
프롬프트를 설정하고 파이프라인을 호출하여 Mistral 7B는 머신러닝에서 정규화 개념을 설명하는 일련의 문장을 생성합니다:
prompt = "As a data scientist, can you explain the concept of regularization in machine learning?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])Mistral 7B 세밀 조정 방법
세밀 조정 과정은 라이브러리 업데이트, 모듈 설정 및 모델을 데이터셋에 맞게 적용하는 작업을 포함합니다. Kaggle 노트북을 사용하면 Hugging Face 및 Weights & Biases와 같은 서비스의 API 키를 안전하게 저장하고 액세스할 수 있습니다. 이 섹션에서는 효과적인 세밀 조정을 위한 필수 단계와 설정을 설명하며, 특정 데이터셋에 Mistral 7B 모델의 잠재력을 극대화하는 방법을 보여줍니다.
- 필요한 라이브러리 업데이트 및 설치: 세밀 조정에 필요한 최신 기능과 호환성 확보
- 모듈 로드 및 API 액세스 설정: 외부 서비스 및 모델 저장소와의 상호 작용을 용이하게 함
- 모델 구성 및 훈련: 데이터셋의 세부 사항에 맞게 모델 조정, Parameter-efficient Fine-tuning (PEFT)의 성능을 활용한 효율적 훈련
- 모델 평가 및 저장: 모델의 성능 평가 및 세밀 조정 결과 저장
세부적인 안내는 Mistral 7B 모델의 기능을 효과적으로 활용하기 위한 도구와 지식을 제공하기 위해 설계되었습니다. 모델 접근부터 특정 데이터셋에서의 세밀 조정까지 각 단계는 프로젝트의 자연어 처리 역량을 향상시키는데 도움이 될 것입니다.
3부. LlamaIndex와 Ollama를 사용하여 로컬에서 Mixtral 8x7b 실행하는 방법

유럽의 인공지능 강자 Mistral AI는 최근 "전문가의 혼합" 모델인 Mixtral 8x7b를 공개했습니다. 이 모델은 각각 7 billion 개의 매개변수로 교육된 8 명의 전문가를 특징으로 하며 GPT-3.5 및 Llama2 70b의 성능을 매칭하거나 뛰어넘는 것으로 주목받고 있습니다.
단계 1: Ollama 설치
MacOS, Linux 및 Windows (Windows Subsystem For Linux를 통해)에서 사용할 수 있는 오픈 소스 도구인 Ollama를 설치하면 로컬 모델 실행 프로세스를 간소화할 수 있습니다. Ollama를 사용하여 다음과 같이 단일 명령으로 Mixtral을 시작할 수 있습니다.
ollama run mixtral이 명령은 모델을 다운로드합니다(일정 시간이 소요될 수 있음) 및 원활히 실행되기 위해 상당한 양의 RAM(48GB)이 필요합니다. 스펙이 낮은 시스템의 경우 Mistral 7b가 대체 가능한 옵션입니다.
단계 2: 종속성 설치
Mixtral을 LlamaIndex와 통합하려면 여러 종속 항목이 필요합니다. 다음과 같이 pip를 사용하여 이를 설치하십시오.
pip install llama-index qdrant_client torch transformers단계 3: 스모크 테스트
Ollama와 LlamaIndex를 사용하여 "스모크 테스트"를 통해 설정을 확인합니다.
from llama_index.llms import Ollama
llm = Ollama(model="mixtral")
response = llm.complete("Who is Laurie Voss?")
print(response)단계 4: 데이터 로드 및 색인화
데이터 준비:
이 예제에는 데이터 세트를 사용할 수 있으며, 여기서는 트윗의 모음을 사용합니다. 데이터는 오픈 소스 벡터 데이터베이스인 Qdrant에 저장됩니다. 다음 코드 조각은 Qdrant 및 LlamaIndex를 사용하여 데이터를 로드하고 인덱싱하는 프로세스를 보여줍니다.
from pathlib import Path
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext, download_loader
from llama_index.llms import Ollama
from llama_index.storage.storage_context import StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Qdrant 초기화 및 트윗 로드
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
## Mixtral과 함께 서비스 컨텍스트 설정 및 로컬 삽입
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## 데이터 인덱싱 및 쿼리
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What does the author think about Star Trek? Give details.")
print(response)인덱스 확인:
마지막 단계는 사전 빌드된 인덱스를 사용하여 쿼리에 답변하는 것입니다. 이 프로세스에서는 데이터를 다시로드하지 않아도 되므로 이미 Qdrant에 인덱싱되어 있습니다.
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import Ollama
from llama_index.vector_stores.qdrant import QdrantVectorStore
## 벡터 저장소 및 Mixtral 로드
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## 인덱스 로드 및 쿼리
index = VectorStoreIndex.from_vector_store(vector_store=vector_store, service_context=service_context)
query_engine = index.as_query_engine(similarity_top_k=20)
response = query_engine.query("Does the author like SQL? Give details.")
print(response)Part 4. llama.cpp를 사용하여 Mistral 8x7B를 로컬에서 실행하는 방법
Mistral AI 모델을 로컬에서 실행하는 것은 llama.cpp 및 llm-llama-cpp 플러그인과 같은 도구로 인해 더욱 쉬워졌습니다. 고품질의 희박한 전문가 혼합 (SMoE) 모델인 Mixtral 8x7B 모델의 출시는 공개 라이선스된 AI 환경에서의 중요한 진보를 나타냈습니다. 이 가이드에서는 llama.cpp 및 관련 도구를 사용하여 Mixtral 8x7B를 로컬에서 실행하는 방법에 대해 간단히 안내합니다.
Mixtral 8x7B를 로컬에 설치 및 실행하기
-
LLM 도구 설치: 먼저, 컴퓨터에 LLM이 설치되어 있는지 확인하십시오. LLM은 로컬에서 다양한 AI 모델을 실행하기 위한 브릿지 역할을 합니다.
pipx install llm -
llm-llama-cpp플러그인 설치: 이 플러그인은llama.cpp에서 Mixtral 및 기타 지원되는 모델을 실행하는 데 필요합니다.llm install llm-llama-cpp -
llama-cpp-python설정: Apple Silicon Mac의 경우 설정에 Metal 지원을 활성화해야할 수 있습니다.CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 llm install llama-cpp-python자세한 지침은 플랫폼에 따라 다를 수 있으므로
llm-llama-cppREADME를 참조하십시오. -
Mixtral 모델 다운로드: Mixtral 8x7B에는 GGUF 파일이 필요합니다. 필요에 맞는 파일 크기를 선택하십시오. 예를 들어, Instruct 버전의 모델에 대해 36GB의 크기가 적합합니다.
curl -LO 'https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf?download=true' -
모델 실행: 모델을 다운로드 한 후,
llm도구를 사용하여 Mixtral 8x7B를 실행할 수 있습니다.llm -m gguf -o path mixtral-8x7b-instruct-v0.1.Q6_K.gguf '[INST] Write a Python function that downloads a file from a URL[/INST]'이 명령은
-m gguf옵션으로 GGUF 모델을 사용하고-o path로 다운로드한 GGUF 파일의 경로를 제공합니다.
추가적인 고려 사항
-
인터랙티브 모드: 대화 형식으로 모델과 상호 작용하려는 경우,
llm을 인터랙티브 모드에서 실행하는 것을 고려하십시오. 이 모드에서는 AI 모델과의 질의응답 대화가 가능합니다. -
프롬프트 구성: 위의 명령 예제에서
[INST]접두사는 프롬프트의 명령 기반 성격을 나타내며, Instruct 버전의 모델에 적합합니다. 최적의 결과를 얻으려면 모델이 기대하는 입력 형식에 맞게 프롬프트를 조정하십시오.
절차 5. 아이폰에서 Mistral 7B Locally 실행하기

Mistral 7B 모델을 아이폰에서 실행하는 것은 일반적으로 데스크톱 환경보다 더 많은 제한 사항을 가진 iOS 장치 때문에 몇 가지 기술적인 단계를 필요로 합니다. 다음은 단순화된 단계별 가이드입니다:
-
사전 준비 작업:
- 호환성 문제를 피하기 위해 iPhone이 최신 iOS 버전을 실행 중인지 확인합니다
- 컴파일 및 실행할 사용자 정의 앱에 Mistral 7B를 사용할 수 있는 Xcode와 같은 iOS 앱 개발 환경을 Mac에 설치합니다.
-
실행 옵션 선택: 아이폰 배포를 위해
llm-llama-cpp가 C++ 환경과 호환되기 때문에 가장 적합할 수 있습니다. 이는 iOS 프로젝트에 통합될 수 있습니다. -
개발 환경 설정:
- 공식 저장소에서
llm-llama-cpp를 위한 GGUF 파일을 다운로드합니다. - Xcode를 열고 새 iOS 프로젝트를 생성합니다.
llm-llama-cpp라이브러리를 프로젝트에 통합합니다. 이 작업은 추가적인 종속성을 필요로 할 수 있으므로 문서를 확인하십시오.
- 공식 저장소에서
-
코딩:
- Swift 또는 Objective-C 코드를 작성하여 C++ 라이브러리와 상호 작용합니다. 이는 Swift 프로젝트에서 C++ 코드를 사용하기 위해 bridging header를 생성하는 것을 포함할 수 있습니다.
- 앱 내에서 모델을 초기화하고 모델 경로 및 매개 변수와 같은 필요한 구성을 처리합니다.
-
테스트 및 배포:
- 모델을 원활하게 실행하고 예상대로 작동하는지 확인하기 위해 iPhone에서 앱을 테스트합니다.
- 만약 Apple 가이드라인을 준수한다면, 개인 사용 용도 또는 App Store에 제출하기 위해 Xcode를 통해 앱을 배포합니다.
절차 6. API를 사용하여 Mistral AI Locally 실행하기

Mistral AI를 로컬에서 API를 사용하여 실행하려면, HTTP 요청이 가능한 환경(테스트를 위한 Postman 또는 HTTP 요청 기능이 있는 프로그래밍 언어 등)이 있는지 확인한 후 다음 단계를 따르십시오.
사전 준비 작업:
- Mistral API 액세스를 위해 API 키를 얻으세요 (opens in a new tab)
- 로컬 환경이 Mistral API 서버와 통신할 수 있도록 인터넷 연결이 되어 있는지 확인합니다.
- 로컬 환경에
llm-mistral플러그인을 설치합니다. 프로그래밍 프로젝트의 경우, 프로젝트 종속성에 추가할 수 있습니다. - 프로젝트 또는 도구를 구성하여 Mistral API 키를 사용할 수 있도록 설정합니다. 보통 이는 설정 파일이나 환경 변수에 키를 설정하는 것을 포함합니다.
채팅 완성 생성하기
이 API 엔드포인트는 프롬프트를 기반으로 텍스트 완성을 생성할 수 있도록 합니다. 요청은 모델, 메시지(프롬프트) 및 템퍼러처(top_p), max_tokens과 같은 생성 프로세스를 제어하는 다양한 매개변수를 지정해야합니다.
채팅 완성을 위한 샘플 Python 코드:
import requests
url = "https://api.mistral.ai/chat/completions"
payload = {
"model": "mistral-small-latest",
"messages": [{"role": "user", "content": "Mistral AI를 사용하기 시작하는 방법은 무엇인가요?"}],
"temperature": 0.7,
"top_p": 1,
"max_tokens": 512,
"stream": False,
"safe_prompt": False,
"random_seed": 1337
}
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Error:", response.text)임베딩 생성하기
임베딩 API 엔드포인트는 텍스트를 고차원 벡터로 변환하는 데 사용됩니다. 이는 의미 검색, 클러스터링 또는 유사한 텍스트 찾기와 같은 작업에 유용할 수 있습니다.
임베딩 생성을 위한 샘플 Python 코드:
import requests
url = "https://api.mistral.ai/embeddings"
payload = {
"model": "mistral-embed",
"input": ["안녕하세요", "세계"],
"encoding_format": "float"
}
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Error:", response.text)사용 가능한 모델 목록 보기
이 API 호출은 단순하여 사용 가능한 모델 목록을 검색할 수 있습니다. 이를 통해 능력이나 요구 사항을 기반으로 다양한 작업에 대해 동적으로 모델을 선택하는 데 도움을 줄 수 있습니다.
사용 가능한 모델 목록 반환을 위한 샘플 Python 코드:
import requests
url = "https://api.mistral.ai/models"
headers = {
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Error:", response.text)이 샘플들은 Mistral AI의 API와의 상호작용을 위한 기반을 제공하여, 정교한 인공지능 애플리케이션을 생성할 수 있게 도와줍니다. 실제 API 키로 "YOUR_API_KEY"를 대체하는 것을 기억해 주세요.
이 절차들은 Mistral 7B AI 모델을 아이폰에서 로컬 환경 또는 API를 통해 실행하기 위한 기본 개요를 제공합니다. 구체적인 프로젝트 요구사항이나 플랫폼 업데이트에 따라 적응이 필요할 수 있습니다.