1-bit Large Language Model 시대: Microsoft, BitNet b1.58 소개
Published on
서론
Microsoft 연구자들은 1-bit Large Language Model (LLM)의 획기적인 변형인 BitNet b1.58을 소개했습니다. 이 모델은 각각의 파라미터가 삼진법으로 표현되며, 1 값 중 하나를 가집니다. 이 1.58-bit LLM은 모델 크기와 훈련 토큰 수에서 full-precision (FP16 또는 BF16) Transformer LLM과 동일한 성능을 발휘하며, 지연 시간, 메모리 사용량, 처리량 및 에너지 소비 측면에서 상당히 경제적입니다. BitNet b1.58은 LLM을 고성능이면서도 매우 효율적으로 만드는 중요한 발전입니다.

BitNet b1.58이란?
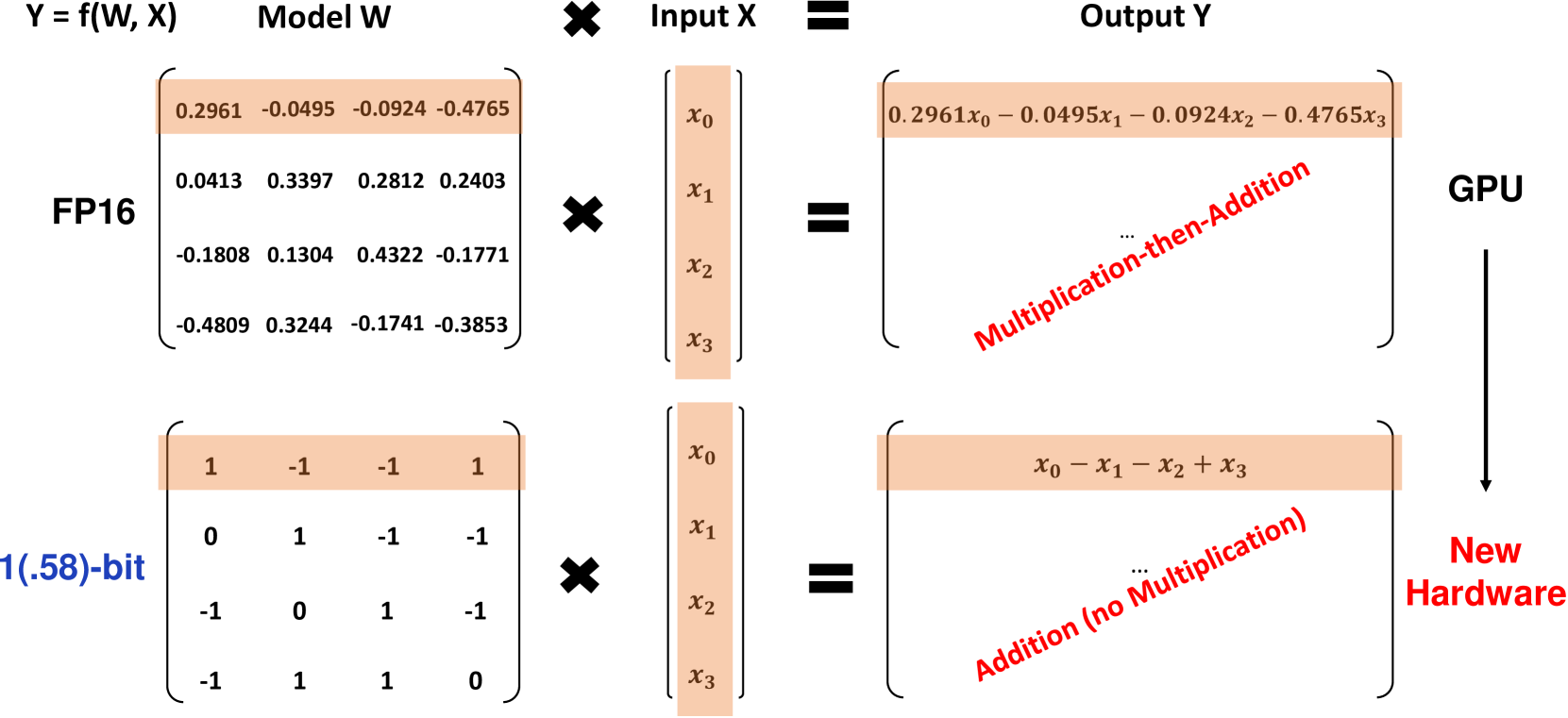
BitNet b1.58은 원래의 BitNet 아키텍처를 기반으로 한 Transformer 모델로, 기존의 nn.Linear 레이어를 BitLinear 레이어로 대체합니다. 이 모델은 1.58-bit 가중치와 8-bit 활성화 함수를 사용하여 처음부터 훈련됩니다. 원래 1-bit BitNet에 비해 b1.58은 몇 가지 중요한 수정 사항을 도입합니다:
-
가중치를 1로 제한하는 absmean 양자화 함수를 사용합니다. 이 함수는 각 가중치를 평균 절댓값으로 스케일링한 후 가장 가까운 정수값으로 반올림합니다.
-
활성화 함수는 토큰 당 [-sa, sa] 범위로 스케일링하여 원래 BitNet보다 구현이 간단해집니다.
-
이 모델은 RMSNorm, SwiGLU 활성화 함수, 로터리 임베딩 및 편향 제거 등 인기 있는 오픈 소스 LLaMA 아키텍처의 구성 요소를 사용합니다. 이로써 기존 LLM 소프트웨어와의 쉬운 통합이 가능해집니다.
가중치에 0 값을 추가함으로써, 이 모델은 순수한 1-bit 모델과 비교하여 특성 필터링을 가능하게 하여 모델링 능력을 향상시킵니다. 실험 결과, BitNet b1.58은 3B 파라미터 크기부터 perplexity와 엔드 태스크 성능에서 FP16 기준과 일치함을 보여줍니다.
성능 결과
연구진은 BitNet b1.58을 재현한 FP16 LLaMA LLM 기준과 모델 크기가 700M에서 70B 파라미터까지 비교했습니다. 두 모델은 동일한 RedPajama 데이터셋에서 100B 토큰으로 사전 훈련되었으며, perplexity와 다양한 zero-shot 언어 작업에서 평가되었습니다.
주요 결과는 다음과 같습니다:
-
BitNet b1.58은 3B 크기에서 FP16 LLaMA 기준의 perplexity와 2.71배 더 빠르며, GPU 메모리 사용량이 3.55배 적습니다.
-
3.9B 크기의 BitNet b1.58은 perplexity와 엔드 태스크에서 3B LLaMA를 능가하며, 지연 시간과 메모리 비용이 더 낮습니다.
-
zero-shot 언어 작업에서는 모델 크기가 커짐에 따라 BitNet b1.58과 LLaMA 간의 성능 차이가 줄어듭니다. 3B 크기에서 BitNet은 LLaMA와 일치합니다.
-
70B 크기로 확장하는 경우, BitNet b1.58은 FP16 기준과 비교하여 4.1배 빠른 속도를 달성합니다. 메모리 절약도 크기와 함께 증가합니다.
-
BitNet b1.58은 행렬 곱셈에 대해 71.4배 더 적은 에너지를 사용합니다. 모델 크기가 커질수록 전체적인 에너지 효율이 향상됩니다.
-
80GB A100 GPU 2개에서, 70B 크기의 BitNet b1.58은 LLaMA보다 11배 더 큰 배치 크기를 지원하여 처리량이 8.9배 더 높아집니다.
이 결과들은 BitNet b1.58이 최신 기술인 FP16 LLM에 비해 성능과 perplexity와 end-task 성능이 동일한 상태에서 지연 시간, 메모리 소비 및 에너지 측면에서 더 효율적임을 보여줍니다. 예를 들어, 13B 크기의 BitNet b1.58은 3B FP16 LLM보다 더 효율적이며, 30B 크기의 BitNet은 7B FP16보다 더 효율적이며, 70B 크기의 BitNet은 13B FP16 모델보다 더 효율적입니다.
StableLM-3B 레시피에 따라 2T 토큰으로 훈련시킨 경우, BitNet b1.58은 모든 평가 작업에서 StableLM-3B zero-shot 모델을 능가하는 강력한 일반화 능력을 보여줍니다.
아래 표는 BitNet b1.58과 FP16 LLaMA 기준 사이의 성능 비교에 대한 자세한 데이터를 제공합니다:
| 모델 | 크기 | 메모리 (GB) | 지연 시간 (ms) | PPL |
|---|---|---|---|---|
| LLaMA LLM | 700M | 2.08 (1.00x) | 1.18 (1.00x) | 12.33 |
| BitNet b1.58 | 700M | 0.80 (2.60x) | 0.96 (1.23x) | 12.87 |
| LLaMA LLM | 1.3B | 3.34 (1.00x) | 1.62 (1.00x) | 11.25 |
| BitNet b1.58 | 1.3B | 1.14 (2.93x) | 0.97 (1.67x) | 11.29 |
| LLaMA LLM | 3B | 7.89 (1.00x) | 5.07 (1.00x) | 10.04 |
| BitNet b1.58 | 3B | 2.22 (3.55x) | 1.87 (2.71x) | 9.91 |
| BitNet b1.58 | 3.9B | 2.38 (3.32x) | 2.11 (2.40x) | 9.62 |
표 1: BitNet b1.58과 LLaMA LLM의 perplexity 및 비용 비교
| 모델 | 크기 | ARCe | ARCc | HS | BQ | OQ | PQ | WGe | 평균 |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA LLM | 700M | 54.7 | 23.0 | 37.0 | 60.0 | 20.2 | 68.9 | 54.8 | 45.5 |
| BitNet b1.58 | 700M | 51.8 | 21.4 | 35.1 | 58.2 | 20.0 | 68.1 | 55.2 | 44.3 |
| LLaMA LLM | 1.3B | 56.9 | 23.5 | 38.5 | 59.1 | 21.6 | 70.0 | 53.9 | 46.2 |
| BitNet b1.58 | 1.3B | 54.9 | 24.2 | 37.7 | 56.7 | 19.6 | 68.8 | 55.8 | 45.4 |
| LLaMA LLM | 3B | 62.1 | 25.6 | 43.3 | 61.8 | 24.6 | 72.1 | 58.2 | 49.7 |
| BitNet b1.58 | 3B | 61.4 | 28.3 | 42.9 | 61.5 | 26.6 | 71.5 | 59.3 | 50.2 |
| BitNet b1.58 | 3.9B | 64.2 | 28.7 | 44.2 | 63.5 | 24.2 | 73.2 | 60.5 | 51.2 |
표 2: BitNet b1.58과 LLaMA LLM의 End Task에 대한 Zero-shot 정확도
다양한 모델 크기에서 BitNet b1.58의 디코딩 지연 시간과 메모리 사용량은 그림 1에 나타나 있습니다. 모델 크기가 커짐에 따라 속도 향상은 70B 파라미터에서 FP16 기준과 비교하여 4.1배까지 증가합니다. 메모리 절약도 크기와 함께 증가합니다.
캡션 참조 캡션 참조 그림 1: BitNet b1.58의 디코딩 지연 시간 (왼쪽)과 메모리 사용량 (오른쪽) - 모델 크기에 따른 변화 에너지 효율성 관점에서, BitNet b1.58은 FP16 LLM에 비해 행렬 곱셈을 위한 에너지를 71.4배 덜 사용합니다. 모델 크기에 따른 end-to-end 에너지 비용은 Figure 2에서 보여지며, BitNet b1.58은 더 큰 규모에서 점점 더 효율적입니다.
Caption 참조 Caption 참조 Figure 2: LLaMA LLM과 비교한 BitNet b1.58의 에너지 소비. 왼쪽: 산술 연산 에너지 구성 요소. 오른쪽: 모델 크기에 따른 end-to-end 에너지 비용.
BitNet b1.58의 또 다른 중요한 장점은 처리량입니다. 두 개의 80GB A100 GPU에서, 70B BitNet b1.58은 70B LLaMA LLM보다 11배 큰 배치 크기를 지원하여 처리량이 8.9배 높아집니다. Table 3에서 확인할 수 있습니다.
| 모델 | 크기 | 최대 배치 크기 | 처리량 (토큰/초) |
|---|---|---|---|
| LLaMA LLM | 70B | 16 (1.0x) | 333 (1.0x) |
| BitNet b1.58 | 70B | 176 (11.0x) | 2977 (8.9x) |
Table 3: 70B BitNet b1.58와 LLaMA LLM의 처리량 비교.
영향과 추후 방향
BitNet b1.58 아키텍처와 결과는 LLM의 미래에 중요한 영향을 미칩니다:
-
높은 성능과 높은 효율성을 모두 갖춘 LLM에 대한 새로운 Pareto frontier와 스케일링 법칙을 수립합니다. 1.58-bit LLM은 매우 낮은 추론 비용으로 FP16 기준을 충족할 수 있습니다.
-
극적인 메모리 감소는 주어진 하드웨어량에서 더 큰 LLM을 실행할 수 있게 합니다. 이는 특히 mixture-of-experts와 같은 메모리 집약적인 아키텍처에 매우 혁신적입니다.
-
8-bit 활성화는 16-bit와 비교하여 주어진 메모리 예산으로 가능한 컨텍스트 길이를 두 배로 늘릴 수 있습니다. 앞으로 4-bit 이하로 더 압축하는 것이 가능합니다.
-
1.58-bit LLM의 탁월한 효율성은 CPU 장치에서 강력한 LLM을 배포할 수 있도록 열어줍니다.
-
BitNet b1.58의 새로운 저비트 계산 패러다임은 1-bit LLM의 잠재력을 완전히 활용하기 위해 1-bit LLM에 최적화된 사용자 지정 AI 가속기와 시스템을 디자인하도록 독려합니다.
마이크로소프트는 1-bit LLM이 LLM을 비용 효율적으로 더욱 향상시키는 매우 유망한 방법으로 보고 있습니다. 그들은 1-bit 모델이 데이터 센터부터 엣지까지의 응용 프로그램을 구동하는 시대를 상상하고 있습니다. 그러나 그러한 미래를 이루기 위해서는 이러한 모델의 독특한 특성을 완전히 활용하기 위해 모델 아키텍처, 하드웨어 및 소프트웨어 시스템을 공동으로 설계해야 합니다. BitNet b1.58은 이러한 LLM의 새로운 시대에 화려한 시작점을 제공합니다.
결론
BitNet b1.58은 성능을 유지하면서 큰 언어 모델을 양자화의 한계까지 밀어넣는 중대한 업적입니다. 삼진수 1 가중치와 8-bit 활성화를 활용하여, 이는 FP16 LLM과 비교하여 퍼플렉서티와 최종 작업 성능에서 일치하면서도 메모리 사용량, 지연 시간 및 에너지 소비를 혁신적으로 낮출 수 있습니다.
1.58-bit 아키텍처는 LLM에 대한 새로운 Pareto frontier를 수립하며, 더 큰 모델을 일부 비용으로 실행할 수 있습니다. 이는 더 긴 컨텍스트를 기본적으로 지원하고, 엣지 장치에 강력한 LLM을 배포하는 것과 같은 새로운 가능성을 열어줍니다. 또한 저비트 AI를 위한 사용자 정의 하드웨어 설계를 독려합니다.
마이크로소프트의 연구는 공격적으로 양자화된 LLM이 FP16 모델과 비교하여 우수한 스케일링 법칙을 수립한다는 것을 보여줍니다. 아키텍처, 하드웨어 및 소프트웨어의 추가적인 공동 설계를 통해 1-bit LLM은 클라우드부터 엣지까지의 비용 효율적인 AI 기능에 대한 다음 주요 발전을 이끌 수 있습니다. BitNet b1.58은 이 흥미로운 초 효율적인 대형 언어 모델의 신규 기대 가능성에 대한 출발점을 제공합니다.