Zephyr-7b: 언어 모델의 새로운 선구자

인공지능의 발전에 관심을 가지고 있다면 Zephyr-7b에 대해 들어본 적이 있을 것입니다. 이것은 또 다른 언어 모델이 아니라 AI의 혁신적인 진보를 나타내는 것입니다. 일반적인 챗봇에 그치지 않고 성능, 효율성 및 유용성에서 새로운 기준을 제시하는 Zephyr-7b는 미래의 오픈 소스 인공지능의 가능성을 엿보입니다. 개발자, 기술 애호가 또는 AI 기술에 대해 궁금한 사람이라면 이 기사가 Zephyr-7b를 이해하는데 도움이 될 것입니다.
최신 LLM 뉴스를 알고 싶으신가요? LLM leaderboard를 확인해보세요!
Zephyr-7b란 무엇인가요?
Zephyr-7b는 그 전작인 Mistral-7B-v0.1에서 보완된 언어 모델입니다. 이 모델은 단순한 모델이 아닌 도움이 되는 어시스턴트 역할을 할 수 있도록 설계되었습니다. 그러나 다른 모델과 어떤 차이가 있을까요? 그 답은 훈련 방법론인 직접적인 선호도 최적화(DPO)에 있습니다. 이 기술은 Zephyr-7b에 성능의 우위를 부여하여 이전보다 더 도움이 되는 모델로 만들었습니다.
- 모델 유형: 7B 파라미터의 GPT 스타일 모델입니다.
- 언어: 주로 영어로 설계되었습니다.
- 라이선스: CC BY-NC 4.0 라이선스에 따라 작동합니다.
Zephyr-7b의 독특한 기능
Zephyr-7b를 독특하게 만드는 기능은 챗봇 이상의 역할을 할 수 있도록 설계되었다는 점입니다. 이 모델은 도움이 되고 효율적이며 매우 다재다능합니다.
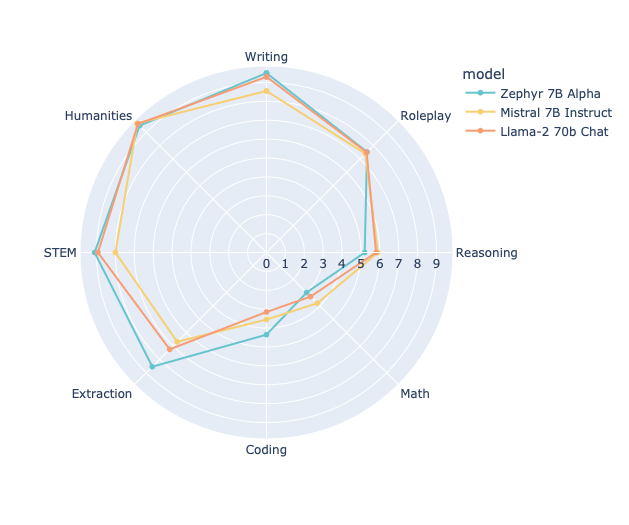
- MT 벤치에서의 성능: Zephyr-7b는 MT 벤치에서 탁월한 성능을 보여주어 llama2-70b와 같은 다른 모델들보다 우수한 성과를 얻었습니다.
- 훈련 데이터: 이 모델은 공개적으로 이용 가능한 데이터와 합성 데이터를 혼합하여 훈련되어 견고하고 다용도로 사용할 수 있습니다.
- 비용 효율성: 훈련을 위한 총 계산 비용이 약 500달러로, Zephyr-7b는 강력하기만 한뿐 아니라 경제적으로 효율적입니다.
직접적인 선호도 최적화(DPO)의 역할
DPO는 Zephyr-7b의 형성에 중요한 역할을 한 훈련 방법론입니다. 다른 훈련 방법과 달리 DPO는 모델의 응답을 인간의 선호도와 더 일치하도록 조정하는 데 초점을 맞추고 있습니다. 이는 벤치마크에서 우수한 성능뿐 아니라 실용적인 유용성에서도 뛰어난 성과를 냈습니다.
DPO가 Zephyr-7b에서 어떻게 작동하는지 감을 잡기 위해 다음은 예시 코드 스니펫입니다:
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-alpha", torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])Zephyr-7b의 기술적 사양: 알아두어야 할 사항
Zephyr-7b의 능력을 이해하기 위해 기술적 사양은 매우 중요합니다. 이 섹션에서는 언어 모델의 혼잡한 환경에서 이 모델을 특별하게 만드는 세부 사항에 대해 살펴보겠습니다.
모델 유형 및 파라미터
Zephyr-7b는 70억 개의 파라미터를 가진 GPT 스타일 모델입니다. 언어 모델의 세부 사항을 이해할 때 파라미터의 수는 종종 모델의 복잡성과 능력을 알 수 있는 좋은 지표입니다.
- 모델 유형: 70억 파라미터를 가진 GPT 스타일 모델입니다.
- 지원하는 언어: 주로 영어를 지원합니다.
- 라이선스: CC BY-NC 4.0
훈련 데이터 및 방법론: Zephyr-7b의 기반
Zephyr-7b의 가장 흥미로운 측면 중 하나는 훈련 데이터와 방법론입니다. 다른 모델이 주로 공개적으로 이용 가능한 데이터에만 의존하는 반면 Zephyr-7b는 공개 데이터와 합성된 데이터를 혼합하여 훈련되었습니다. 이 다양한 훈련 데이터는 견고성과 다재다능성에 기여했습니다.
- 훈련 데이터: 공개적으로 이용 가능한 데이터와 합성된 데이터의 조합입니다.
- 훈련 방법론: 직접적인 선호도 최적화(DPO)
다음은 사용된 일부 훈련 하이퍼파라미터의 간략한 설명입니다:
- 학습 속도: 5e-07
- 훈련 배치 크기: 2
- 평가 배치 크기: 4
- 시드: 42
- 옵티마이저: 베타값이 (0.9, 0.999)이고 입실론이 1e-08인 Adam
평가 지표: 수치가 말해주는 것들
Zephyr-7b는 능력을 시험하기 위해 엄격한 평가를 거쳤습니다. 모델은 다양한 평가 지표로 평가되었으며, 숫자들은 꽤 인상적입니다.
- 손실: 0.4605
- 보상/선택됨: -0.5053
- 보상/거부됨: -1.8752
- 보상/정확도: 0.7812
- 보상/마진: 1.3699
이러한 평가 지표는 모델의 성능을 검증할 뿐 아니라 강점과 개선의 여지가 있는 영역에 대한 통찰을 제공합니다.
Zephyr-7b 사용 시작하기: 단계별 안내
Zephyr-7b에 흥미를 느낀다면 어떻게 사용할 수 있는지 궁금할 것입니다. 운이 좋게도, 이 섹션에서는 이 혁신적인 모델을 사용하기 위한 단계별 안내를 제공합니다.
저장소와 데모: 시작점
먼저 공식 저장소와 데모를 확인하는 것이 가장 먼저해야 할 일입니다. 이 플랫폼은 Zephyr-7b에 대해 탐색하기 위해 필요한 모든 리소스를 제공합니다.
Zephyr-7b 실행하기: 필요한 코드
Zephyr-7b를 실행하는 것은 Transformers의 pipeline() 함수 덕분에 간단한 프로세스입니다. 아래는 모델을 실행하는 방법을 보여주는 샘플 코드입니다.
from transformers import pipeline
import torch
# 파이프라인 초기화
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-alpha", torch_dtype=torch.bfloat16, device_map="auto")
# 메시지 프롬프트 생성
messages = [
{"role": "system", "content": "You are a friendly chatbot."},
{"role": "user", "content": "Tell me a joke."},
]
# 응답 생성
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
# 생성된 텍스트 출력
print(outputs[0]["generated_text"])Zephyr-7b의 작동 방식: 실제 응용 및 제한 사항
기술적인 세부 사항에 빠져들기 쉬운 것은 사실이지만, 언어 모델의 실제 응용이 진정한 테스트입니다. Zephyr-7b는 이를 감안하여 실용성이 있는 디자인으로 개발되었습니다.
채팅 및 대화 인터페이스
Zephyr-7b의 주요 응용 분야 중 하나는 채팅과 대화형 인터페이스입니다. 이 모델은 UltraChat 데이터셋의 변형으로 fine-tune되었으며, 다양한 대화 시나리오를 처리하는 데 능숙합니다. 고객 서비스 봇이나 대화형 게임을 구축하든지, Zephyr-7b가 해결해드립니다.
텍스트 생성 및 콘텐츠 작성
Zephyr-7b가 빛나는 또 다른 영역은 텍스트 생성입니다. 기사 자동 생성, 웹사이트용 동적 응답 생성, 심지어 코드 작성을 위한 도구로 사용하든지, Zephyr-7b의 텍스트 생성 기능은 모든 작업에 적합합니다.
제한 사항: 주의해야 할 점
Zephyr-7b는 강력한 도구이지만, 제한 사항을 알고 있어야 합니다. RLHF와 같은 기법을 사용하여 인간의 선호도에 맞추어 조정하지 않았으므로, 적절하게 관리되지 않으면 문제가 있는 출력물을 생성할 수 있습니다. Zephyr-7b를 실제 응용에서 배포할 때 적절한 필터링 메커니즘이 구축되어 있는지 항상 확인하십시오.
Zephyr-7b의 미래: 앞으로 어떤 일이 있을까요?
미래를 바라보며, Zephyr-7b는 시작에 불과합니다. 계속되는 연구와 개발을 통해, 이 모델의 더 고급 버전을 기대할 수 있으며, 이를 통해 언어 모델의 가능성의 경계를 더욱 넓힐 것입니다.
다가오는 기능과 개선 사항
현재 버전의 Zephyr-7b는 인상적이지만, 여러 가지 기능과 개선 사항이 준비 중입니다. 이에는 다음과 같은 것들이 포함됩니다:
- 더 나은 인간과 같은 상호작용을 위한 개선된 정렬 기법
- 영어 이외의 여러 언어로의 확장
- 복잡한 쿼리와 작업을 더욱 견고하게 처리하는 기능
넓은 파급효과: 새로운 기준 설정
Zephyr-7b는 모델뿐만 아니라 오픈 소스 인공지능 분야에서 가능한 한계를 제시합니다. 성능, 효율성 및 유용성에서 새로운 기준을 설정함으로써, Zephyr-7b는 미래의 모델들을 위한 길을 열고 인공지능의 풍경을 조성하고 있습니다.
결론: Zephyr-7b의 중요성
언어 모델로 가득한 세상에서, Zephyr-7b는 혁신과 실용성의 신호탄으로 돋보입니다. 독특한 훈련 방법론부터 다양한 응용 분야까지, 이 모델은 AI 분야에서의 게임 체인저입니다.
고급 AI를 프로젝트에 통합하려는 개발자이거나 최신 기술에 대한 탐구에 열광하는 기술 애호가라면, Zephyr-7b는 여러분에게 맞는 모델을 제공합니다. 기술적인 능력, 실제 응용 분야 및 미래 잠재력은 Zephyr-7b가 탐색할 가치가 있는 모델로 만듭니다.
그러니 공개 소스 AI의 미래에 뛰어들 준비가 되었다면, Zephyr-7b가 여러분의 입장권입니다. 혁명을 놓치지 마세요. Zephyr-7b로 오늘 출발하세요!
최신 LLM 뉴스를 알고 싶으신가요? 최신 LLM 리더보드를 확인해보세요!
