검색 증강 생성 (RAG): 명확히 설명함
- Name
- Jennie Rose
Published on
언어 학습 모델 (LLM)의 복잡한 현장에서 RAG(검색 증강 생성)를 무시할 수 없습니다. 이 기법은 머신 러닝과 자연어 처리에 대한 정교한 접근법을 제공하는 차세대 기술입니다. 이 안내서에서는 LLM에서 RAG를 이해하고 구현하기 위한 궁극적인 자료를 제공합니다.
데이터 과학자부터 머신 러닝 초보자에 이르기까지 RAG를 마스터하는 것은 당신의 비밀 무기가 될 수 있습니다. 우리는 RAG의 아키텍처, LLM으로의 통합, 파인 튜닝과의 비교, langChain과 같은 플랫폼에서의 응용 등을 다룰 것입니다. 그러면 시작해봅시다!
RAG란 무엇인가요?
RAG의 정의
검색 증강 생성 (RAG)은 두 가지 다른 유형의 모델인 리트리버와 제너레이터의 능력을 결합한 고급 머신 러닝 모델입니다. 본질적으로 리트리버는 데이터 세트를 스캔하여 관련 정보를 찾고, 제너레이터는 이러한 정보를 사용하여 상세하고 일관된 응답을 생성합니다.
- 리트리버: BM25 또는 Dense Retriever와 같은 알고리즘을 사용하여 말뭉치를 검색하고 관련 문서를 찾습니다.
- 제너레이터: 일반적으로 BERT, GPT-2 또는 GPT-3와 같은 변환 기반 모델로, 검색한 문서를 기반으로 인간과 유사한 텍스트를 생성합니다.
RAG의 작동 방식: 기술적인 심층 해설
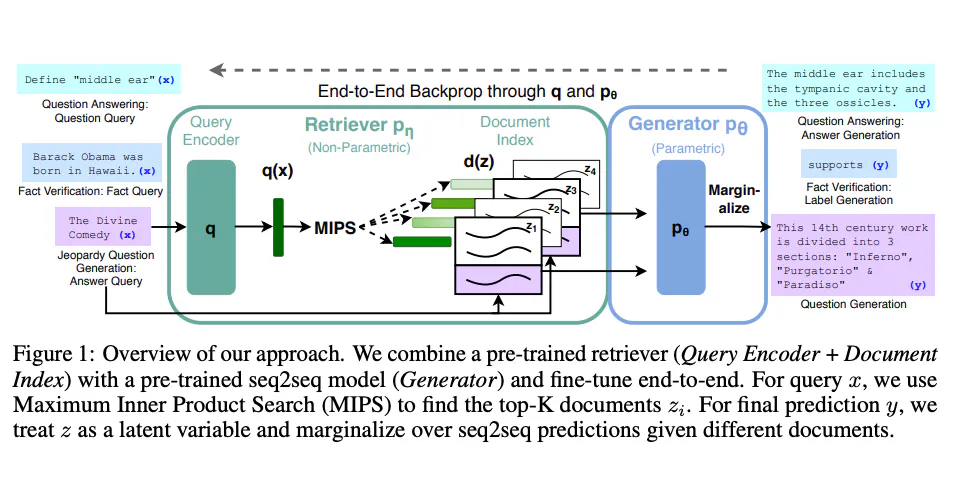
RAG 모델은 두 단계로 작동합니다:
- 검색 단계: 질의를 입력하면, 리트리버가 말뭉치를 스캔하고
N개의 가장 관련성이 높은 문서를 검색합니다. 이는 일반적으로 코사인 유사도와 같은 유사성 측정 기준을 사용하여 수행됩니다.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(corpus)
query_vector = vectorizer.transform([query])
similarity_scores = cosine_similarity(query_vector, tfidf_matrix)- 생성 단계: 제너레이터는 이러한
N개의 문서와 원래의 질의를 사용하여 일관된 응답을 생성합니다.
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base")
retriever = RagRetriever.from_pretrained("facebook/rag-token-base", index_name="exact", use_dummy_dataset=True)
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-base", retriever=retriever)
input_ids = tokenizer(query, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
generated = tokenizer.decode(outputs[0], skip_special_tokens=True)이 두 단계를 결합함으로써 RAG는 상세하고 문맥적으로 관련성 있는 응답으로 복잡한 질의에 대답 할 수 있습니다.
LLM에서 RAG 사용하기
LLM에 RAG 설정하기
LLM에 RAG를 구현하려면 다음이 필요합니다:
- 말뭉치: SQL 데이터베이스, Elasticsearch 또는 간단한 JSON 파일 형식일 수 있습니다.
- 머신 러닝 프레임워크: TensorFlow 또는 PyTorch가 일반적으로 사용됩니다.
- 컴퓨팅 리소스: 균형 잡힌 CPU/GPU가 학습 및 추론에 필요합니다.
LLM에서 RAG를 구현하는 단계
LLM에서 RAG를 구현하는 단계별 가이드입니다:
- 데이터 준비: 말뭉치는 검색 가능한 형식으로 준비되어야 합니다. Elasticsearch를 사용하는 경우 데이터를 인덱싱하는 것을 잊지 마세요.
curl -X PUT "localhost:9200/my_index"-
모델 선택: 리트리버와 제너레이터 모델을 선택합니다. 사전 훈련 된 모델을 사용하거나 직접 훈련 할 수 있습니다.
-
훈련: 리트리버와 제너레이터 모델을 훈련합니다. 일반적으로 별도로 수행됩니다.
retriever.train()
generator.train()- 통합: 훈련된 리트리버와 제너레이터를 단일 RAG 모델로 결합합니다.
rag_model = RagModel(retriever, generator)- 테스트: 텍스트 생성 품질을 위한 BLEU와 검색 정확도를 위한 recall@k와 같은 다양한 메트릭을 사용하여 모델의 성능을 검증합니다.
위의 단계를 따라하면 강력한 RAG 모델이 구축되어 다양한 LLM에 통합하여 우수한 성능을 제공할 수 있습니다.
LLM에서 RAG에 대한 유틸리티 기능
RAG 모델을 평가하기 위해 Precision@k 또는 NDCG와 같은 평가지표를 사용하는 get_retrieval_score()와 같은 유틸리티 기능을 사용할 수 있습니다.
from sklearn.metrics import ndcg_score
ndcg = ndcg_score(y_true, y_score)이 기능은 리트리버의 성능을 세밀하게 조정하여 말뭉치에서 가장 관련성이 높은 문서를 검색할 수 있도록 보장하는 데 매우 유용합니다.
RAG vs 파인 튜닝
RAG와 파인 튜닝의 차이점은 무엇인가요?
RAG와 파인 튜닝은 모두 언어 학습 모델 (LLMs)의 성능을 향상시키기 위해 개발되었지만, 작업 방식이 다릅니다. 파인 튜닝은 기존의 사전 훈련 된 모델을 수정하여 특정 작업이나 데이터 세트에 더 잘 적응하도록 하는 반면, RAG는 질문에 대한 복잡한 답변을 생성하기 위해 검색 및 생성 기능을 결합합니다.
- 파인 튜닝: 특정 데이터 세트에서 교육 단계에서 미리 훈련 된 모델의 가중치를 조정하는 작업입니다.
- RAG: 말뭉치에서 관련 정보를 가져 오고, 일관된 응답을 생성하기 위해 리트리버와 제너레이터를 결합합니다.
기술적인 비교: RAG vs 파인 튜닝
- 계산량:
- RAG: 두 개의 별개의 모델이 있기 때문에 더 많은 계산 리소스가 필요합니다.
- 파인 튜닝: 일반적으로 계산량이 적습니다.
- 유연성:
- RAG: 다양한 유형의 쿼리에 적응할 수 있는 매우 유연한 기능입니다.
- Fine-Tuning: 특정 작업에 대해서만 적용 가능합니다.
- 데이터 요구사항:
- RAG: 검색을 위해 크고 잘 구조화된 말뭉치가 필요합니다.
- Fine-Tuning: 훈련을 위해 작업별 데이터셋이 필요합니다.
- 구현 복잡도:
- RAG: 두 모델의 통합으로 인해 더 복잡합니다.
- Fine-Tuning: 비교적 간단합니다.
샘플 코드: RAG vs Fine-Tuning
RAG의 경우:
# Hugging Face의 Transformers 라이브러리를 사용합니다
from transformers import RagModel
rag_model = RagModel.from_pretrained("facebook/rag-token-nq")Fine-Tuning의 경우:
# PyTorch를 사용하여 BERT 모델을 Fine-Tuning합니다
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
model.train()이러한 차이점을 이해함으로써 LLM 프로젝트에 가장 적합한 접근 방식을 선택할 수 있습니다.
LLM 애플리케이션에 RAG 사용하는 방법
기존 LLM에 RAG 통합하기
이미 LLM을 보유하고 있고 RAG를 통합하려는 경우, 다음 단계를 따르세요:
-
사용 사례 식별: RAG를 통해 달성하려는 목표를 결정하세요 - 질의응답, 요약 등.
-
데이터 정렬: 기존 말뭉치가 RAG에서 사용할 수 있는 검색기와 호환되는지 확인하세요.
-
모델 통합: RAG 모델을 기존 LLM 아키텍처에 통합하세요.
# PyTorch를 사용한 예시
class MyLLMWithRAG(nn.Module):
def __init__(self, my_llm, rag_model):
super(MyLLMWithRAG, self).__init__()
self.my_llm = my_llm
self.rag_model = rag_model- 테스트와 검증: RAG 모델이 LLM의 성능을 향상시키는지 확인하기 위해 테스트를 실행하세요.
흔한 함정과 피하는 방법
- 적합하지 않은 말뭉치: 검색기가 관련 문서를 찾을 수 있도록 충분히 크고 다양한 말뭉치를 확보하세요.
- 모델 불일치: 검색기와 생성기는 데이터 유형과 차원에서 호환될 수 있어야 합니다.
RAG를 LLM 애플리케이션에 신중하게 통합함으로써 그 성능과 능력을 크게 향상시킬 수 있습니다.
langChain에서 RAG 사용하는 방법
langChain이란?
langChain은 언어 모델을 위한 탈중앙 플랫폼입니다. RAG를 포함하여 다양한 기계 학습 모델을 통합하여 강화된 자연어 처리 서비스를 제공합니다.
langChain에 RAG 구현하는 단계
-
설치: langChain SDK를 설치하고 개발 환경을 설정합니다.
-
모델 업로드: 사전 훈련된 RAG 모델을 langChain 플랫폼에 업로드합니다.
langChain upload --model my_rag_model- API 통합: langChain의 API를 사용하여 RAG 모델을 애플리케이션에 통합합니다.
from langChain import RagService
rag_service = RagService(api_key="your_api_key")- 쿼리 실행: langChain 플랫폼을 통해 쿼리를 실행하고, RAG 모델을 활용하여 응답을 생성합니다.
response = rag_service.query("인생의 의미는 무엇인가요?")이러한 단계를 따르면, RAG를 langChain에 원활하게 통합하여 성능과 확장성을 탁월하게 개선할 수 있습니다.
결론
RAG는 언어 학습 모델의 능력을 크게 향상시킬 수 있는 강력한 도구입니다. 기존 LLM에 통합하고, Fine-Tuning 방법과 비교하고, langChain과 같은 탈중앙 플랫폼에서 사용할 수 있습니다. RAG의 검색 및 생성 메커니즘을 통해 복잡한 쿼리에 미묘한 접근법을 제공하므로, 기계 학습과 자연어 처리 분야에서 귀중한 자산입니다.
FAQ
LLM에서 RAG란 무엇인가요?
RAG(검색 증강 생성)은 언어 학습 모델에서 복잡한 쿼리에 대답하기 위해 검색기와 생성기를 결합하는 기술입니다.
rag와 LLM의 차이점은 무엇인가요?
RAG는 LLM의 능력을 향상시키기 위한 특정 기술입니다. RAG는 독립적인 모델이 아니라 기존 LLM에 통합될 수 있는 구성 요소입니다.
rag LLM을 평가하는 방법은 무엇인가요?
텍스트 생성 품질에 대한 BLEU와 검색 정확도에 대한 recall@k와 같은 평가 지표가 일반적으로 사용됩니다.
rag vs fine-tuning의 차이점은 무엇인가요?
RAG는 검색과 생성 메커니즘을 결합한 것이고, fine-tuning은 기존 모델을 특정 작업에 대응하기 위해 수정하는 것을 의미합니다.
rag LLM의 장점은 무엇인가요?
RAG는 미묘하고 맥락에 맞는 응답을 가능하게 함으로써 복잡한 쿼리에 대해 매우 효과적입니다.
