Os 10 Melhores Bancos de Dados de Vetores de 2023: Uma Revisão Completa

Os bancos de dados de vetores não são mais um tópico de nicho discutido apenas entre cientistas de dados e administradores de banco de dados. À medida que entramos em 2023, eles se tornaram um ponto focal para qualquer pessoa lidando com tipos de dados complexos, como imagens, áudio e texto. Mas afinal, o que são bancos de dados de vetores e por que estão recebendo tanta atenção?
Neste artigo, iremos desmistificar os bancos de dados de vetores, analisar seus prós e contras e revelar a empolgação em torno deles. Também iremos dar uma olhada exclusiva nos 9 melhores bancos de dados de vetores de 2023, com um foco especial em opções de código aberto. Então, vamos lá!
Quer saber as últimas notícias do LLM? Confira a última LLM leaderboard!
O que é um Banco de Dados de Vetores?
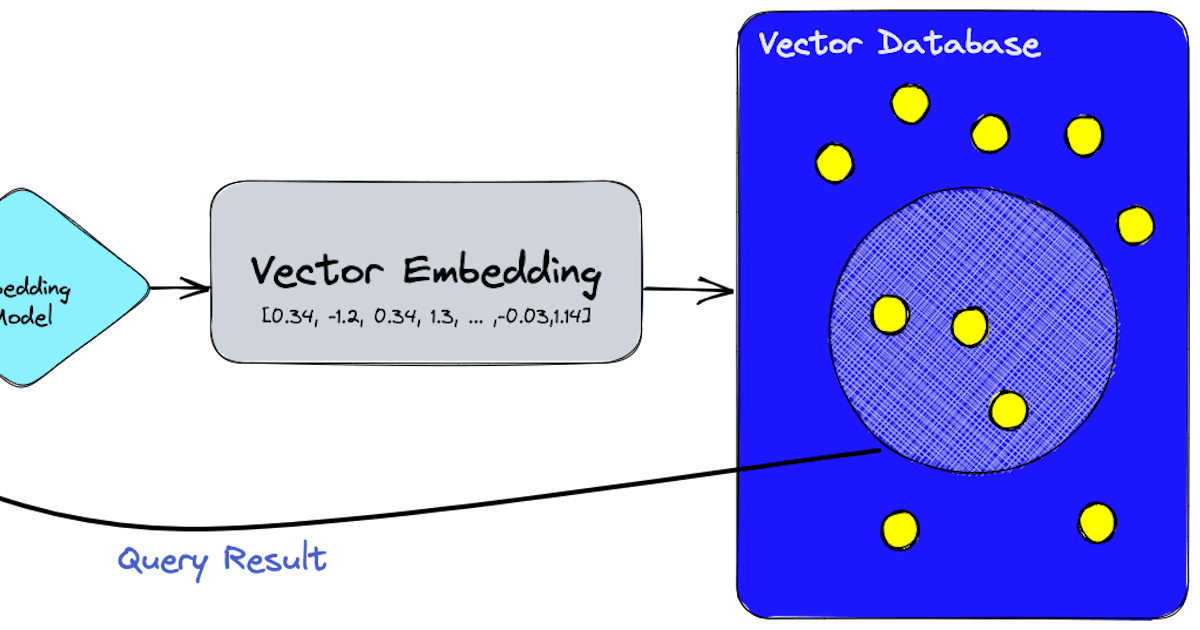
Um banco de dados de vetores é um tipo especializado de banco de dados projetado para lidar com tipos de dados complexos com os quais os bancos de dados tradicionais têm dificuldade. Ao contrário dos bancos de dados relacionais padrão que armazenam dados em tabelas, os bancos de dados de vetores usam vetores matemáticos para representar os dados. Isso permite que eles gerenciem e pesquisem de forma eficiente dados de alta dimensão, como imagens, arquivos de áudio e conteúdo textual.
Os bancos de dados de vetores utilizam algoritmos como k-NN (k-vizinhos mais próximos) para pesquisas nos dados de alta dimensão. Eles também empregam técnicas como quantização e particionamento para otimizar o desempenho das pesquisas. Aqui está um exemplo de comando para pesquisar por imagens semelhantes em um banco de dados de vetores:
SELECT * FROM imagens WHERE VECTOR_SEARCH(vetor_imagem, vetor_alvo) < 0.2;Neste exemplo, VECTOR_SEARCH é uma função que calcula a similaridade entre vetor_imagem e vetor_alvo. O < 0.2 especifica o limite de similaridade.
Por que os Bancos de Dados de Vetores são Diferentes?
-
Manejo de Dados de Alta Dimensão: Bancos de dados tradicionais não estão preparados para lidar com dados de alta dimensão. Bancos de dados de vetores preenchem essa lacuna usando vetores matemáticos para representação, facilitando o trabalho com tipos de dados complexos.
-
Capacidade de Pesquisa Rápida: Uma das características marcantes dos bancos de dados de vetores é sua capacidade de realizar pesquisas rápidas de similaridade. Por exemplo, se você tiver uma imagem, um banco de dados de vetores pode encontrar rapidamente imagens similares no banco de dados sem precisar examinar cada entrada.
-
Escalabilidade: À medida que os dados crescem, a necessidade de bancos de dados capazes de escalar sem degradação de desempenho se torna crucial. Bancos de dados de vetores são construídos com escalabilidade em mente, permitindo que lidem com grandes volumes de dados de forma eficiente.
Revisão dos Bancos de Dados de Vetores: Correspondendo à Empolgação?
Como qualquer tecnologia emergente, os bancos de dados de vetores têm sido cercados por uma quantidade considerável de empolgação. Muitos afirmam que são a próxima grande novidade em tecnologia de banco de dados, traçando paralelos com o movimento NoSQL que perturbou o cenário de banco de dados há uma década. Mas o quanto disso é verdade e no que você deve ter cautela?
A Verdade Dura dos Bancos de Dados de Vetores: Você Deve Adaptar-se?
A empolgação não é totalmente infundada. Os bancos de dados de vetores oferecem capacidades únicas que os bancos de dados tradicionais não possuem, especialmente quando se trata de lidar com dados complexos e de alta dimensão. No entanto, é essencial separar o joio do trigo. Nem todos os bancos de dados de vetores estão à altura da empolgação e alguns estão mais focados em marketing do que em oferecer recursos robustos.
O que Observar ao Escolher Bancos de Dados de Vetores:
-
Promessas Exageradas e Entregas Insuficientes: Alguns bancos de dados de vetores prometem o impossível, mas falham em fornecer recursos essenciais como alta disponibilidade, sistemas de backup e tipos de dados avançados como geoespaciais e datahora.
-
Complexidade: Embora os bancos de dados de vetores sejam poderosos, eles também podem ser complexos de configurar e gerenciar. Certifique-se de ter a experiência técnica necessária para lidar com eles ou esteja preparado para investir em treinamento.
-
Custos: Cuidado com os custos ocultos, especialmente com bancos de dados proprietários. Taxas de licenciamento podem se acumular e você também pode precisar investir em hardware especializado.
Ao estar ciente desses pontos, você pode navegar pela empolgação e tomar uma decisão mais informada. Lembre-se sempre de olhar além das palavras de marketing e analisar profundamente os recursos reais e limitações do banco de dados.
Vantagens vs Desvantagens dos Bancos de Dados de Vetores
Os bancos de dados de vetores vêm ganhando destaque por sua capacidade de lidar com tipos de dados complexos, como imagens, áudio e texto. No entanto, é crucial entender tanto suas vantagens quanto suas limitações.
Vantagens dos Bancos de Dados de Vetores:
-
Pesquisa de Similaridade Eficiente: Bancos de dados de vetores se destacam na busca pelos vizinhos mais próximos em espaços de alta dimensão, o que é crucial para sistemas de recomendação, reconhecimento de imagens e processamento de linguagem natural.
-
Escalabilidade: Muitos bancos de dados de vetores são projetados para lidar com dados em grande escala, alguns até oferecendo arquiteturas distribuídas para escalabilidade horizontal.
-
Flexibilidade: Com suporte a várias métricas de distância e algoritmos de indexação, os bancos de dados de vetores podem se adaptar altamente a casos de uso específicos.
-
Intensivo em Recursos: A busca de alta velocidade muitas vezes ocorre às custas dos recursos computacionais. Alguns bancos de dados exigem hardware especializado para obter um desempenho ótimo.
Desvantagens dos Bancos de Dados de Vetores:
- Complexidade: A variedade de opções algorítmicas e configurações pode tornar os bancos de dados de vetores desafiadores de configurar e manter.
- Custo: Embora existam opções de código aberto, os bancos de dados vetoriais comerciais podem ser caros, especialmente para implantações em grande escala.
Top 10 Bancos de Dados Vetoriais a Considerar em 202
Principais Bancos de Dados Vetoriais de Código Aberto em 2023
1. Faiss
- Preço Inicial: Gratuito (Código Aberto)
- Avaliação: 4.7/5
- Prós:
- Excepcional aceleração de GPU via CUDA
- Suporta bilhões de vetores
- Extensas opções algorítmicas como IVFADC, PQ e HNSW
- Contras:
- Requer conhecimento em quantização vetorial
- Limitado a implantações em um único nó
Detalhes Técnicos: Faiss (opens in a new tab) utiliza uma variedade de técnicas de indexação, incluindo Segmentador de Arquivo Invertido (IVF) e Quantizador Escalar (SQ) para buscas de similaridade eficientes. Ele também suporta processamento em lote de consultas e paralelização em várias GPUs. A biblioteca é otimizada tanto para a distância L2 quanto para a similaridade de produto interno, o que a torna versátil para diferentes casos de uso.
Faiss Vector Database GitHub: https://github.com/facebookresearch/faiss (opens in a new tab)

2. Annoy (Approximate Nearest Neighbors Oh Yeah)
- Preço Inicial: Gratuito (Código Aberto)
- Avaliação: 4.5/5
- Prós:
- Utiliza floresta de árvores para particionar o espaço vetorial
- Suporte a arquivos mapeados em memória para dados em grande escala
- Complexidade assintótica das consultas é (O(\log N))
- Contras:
- Limitado a métricas de distância Angular, Euclidiana, Manhattan e Hamming
- Sem suporte nativo para computação distribuída
Detalhes Técnicos: Annoy Vector Database (opens in a new tab) constrói uma árvore binária para cada vetor, particionando o espaço em espaços de meia-dimensão. As árvores são então usadas para uma busca eficiente do vizinho mais próximo. Ele também suporta tempos de construção multithread e permite salvar índices em disco, que podem ser mapeados em memória posteriormente para buscas de similaridade em grande escala.
Annoy Vector Database GitHub: https://github.com/spotify/annoy (opens in a new tab)
3. NMSLIB (Biblioteca de Espaço Não-Métrico)
- Preço Inicial: Gratuito (Código Aberto)
- Avaliação: 4.6/5
- Prós:
- Suporta uma infinidade de métricas de distância como Cosseno, Jaccard e Levenshtein
- Utiliza grafos Small World Navegáveis Hierárquicos (HNSW) para busca eficiente
- Otimizado tanto para vetores de dados densos quanto esparsos
- Contras:
- Curva de aprendizado íngreme devido a extensas opções algorítmicas
- Suporte e documentação limitados da comunidade
Detalhes Técnicos: NMSLIB Vector Database (opens in a new tab) utiliza algoritmos avançados como árvores VP, SW-graph e HNSW para indexação. Também suporta busca de vizinho mais próximo aproximado (ANN), permitindo um equilíbrio entre desempenho de consulta e precisão. A biblioteca é otimizada para desempenho de baixa latência e alta taxa de transferência, o que a torna adequada para aplicações em tempo real.
NMSLIB Vector Database GitHub: https://github.com/nmslib/nmslib (opens in a new tab)
Bancos de Dados Vetoriais Comerciais: Vale a Pena?
4. Milvus
- Preço Inicial: Gratuito (Código Aberto)
- Avaliação: 4.2/5
- Prós:
- Escalabilidade: Manipula até 100 bilhões de vetores com latência inferior a um segundo.
- Métricas de Distância: Suporta métricas Euclidiana, Cosseno e Jaccard. Suporta tipos de índice como IVF_FLAT, IVF_PQ e HNSW.
- Contras:
- Tipos de Dados: Sem suporte para tipos geoespaciais e de data e hora.
- Backup: Sem sistema de backup integrado.
- Autenticação: Recursos de segurança inconsistentes.
- Requer componentes adicionais como MySQL or SQLite para armazenamento de metadados.
- Suporte transacional limitado, não adequado para aplicativos compatíveis com ACID.
Vantagens do Milvus: O Milvus foi projetado para ambientes nativos de nuvem e suporta dimensionamento horizontal. Ele emprega um sistema de índice híbrido, combinando métodos de indexação baseados em árvore e baseados em hash para recuperação eficiente de dados. O sistema também suporta poda de vetores e filtragem de consultas para condições de pesquisa mais complexas.
Desvantagens do Milvus: Embora o Milvus seja de código aberto e escalável, ele tem limitações. Ele não oferece suporte a tipos avançados de dados, como geoespacial e data e hora. Isso representa uma lacuna significativa para aplicativos em SIG e análise de séries temporais. Também não possui um sistema de backup integrado, o que é uma falha crítica. A implementação inconsistente de recursos de segurança, como OAuth e LDAP, é outra preocupação.

5. Pinecone
- Preço Inicial: A partir de $30/mês
- Avaliação: 3.9/5
- Prós:
- Serviço totalmente gerenciado
- Recursos de versionamento e reversão de dados integrados
- Suporta multilocação
- Contras:
- Custo: O custo pode aumentar rapidamente para implantações maiores, o que pode ser exponencial com o tamanho dos dados.
- Recursos Limitados: Sem joins, transações ou indexação avançada.
- Documentação: Documentação técnica limitada.
- Customização Limitada devido à natureza gerenciada
Vantagens do Pinecone: O Pinecone utiliza um algoritmo proprietário de indexação vetorial que é otimizado tanto para vetores densos quanto esparsos. Ele usa uma arquitetura distribuída e fragmentada para escalabilidade e oferece APIs RESTful para integração fácil. No entanto, a falta de acesso ao código-fonte pode ser uma limitação para aqueles que desejam estender ou personalizar suas funcionalidades.
Desvantagens do Pinecone: A natureza comercial do Pinecone tem um custo elevado, especialmente para grandes conjuntos de dados. Ele não oferece suporte a joins e transações, que são essenciais para operações de dados complexas. A documentação técnica limitada é um sinal de alerta, sugerindo que o produto pode não corresponder às expectativas de marketing.

6. Zilliz
- Preço Inicial: Preço sob consulta
- Avaliação: 3.7/5
- Prós:
- REST API: Integração fácil com aplicativos existentes.
- Pesquisa de Atributos: Operações básicas de pesquisa de atributos suportadas.
- Baseado em Nuvem: Escalabilidade sem sobrecarga operacional.
- Contras:
- Custo: Precificação exponencial com o tamanho dos dados.
- Recursos Limitados: Sem joins, transações ou indexação avançada.
- Documentação: Documentação técnica escassa.
- Falta de tipos de dados avançados como geoespacial e data e hora.
Vantagens da Zilliz: A Zilliz utiliza uma variedade de algoritmos de indexação, incluindo IVF_SQ8 e NSG, e suporta aceleração por GPU para um processamento mais rápido de consultas. Também oferece uma linguagem de consulta semelhante ao SQL, permitindo condições de pesquisa mais complexas. No entanto, a falta de transparência em seus recursos de alta disponibilidade levanta questões sobre sua adequação para aplicativos críticos.
Desvantagens da Zilliz: A Zilliz não possui recursos essenciais como joins e transações, tornando-a pouco confiável para aplicativos sérios. A ausência de recursos de alta disponibilidade, como replicação de dados e failover automático, apresenta um risco. O sistema de backup é inadequado, exigindo recursos adicionais para recuperação de dados.

Como Avaliar Bancos de Dados Vetoriais
Ao avaliar bancos de dados vetoriais, leve em consideração os seguintes aspectos técnicos:
- Conjunto de Recursos: Suporta joins, transações e tipos de dados avançados?
- Escalabilidade: É capaz de lidar eficientemente com dados em larga escala?
- Custo: Como a precificação se escalona com os recursos oferecidos?
- Suporte da Comunidade: Existe suporte ativo da comunidade e documentação extensa?
- Benchmarks: Use benchmarks de desempenho, como consultas por segundo (QPS), latência e taxa de transferência para comparação.
Para obter mais detalhes, você pode executar ferramentas fornecidas por este repositório no GitHub (opens in a new tab) como referência para banco de dados vetoriais.
Melhores Alternativas de Bancos de Dados Vetoriais de Código Aberto em 2023
7. Qdrant: A Escolha da Comunidade
- Preço Inicial: Grátis (Código Aberto)
- Avaliação: 4.5/5
Prós:
- Local e Baseado em Nuvem: Oferece ambas as opções de implantação, dando flexibilidade.
- Modo em Memória: Permite testes sem inicializar um contêiner.
- Amigável para Migrações: Recebendo muitas migrações de outras ferramentas.
Contras:
- Documentação: Poderia se beneficiar de guias mais abrangentes.
- Tamanho da Comunidade: Comunidade menor em comparação com outras opções de código aberto.
- Conjunto de Recursos: Ainda em crescimento e pode faltar alguns recursos avançados.
Detalhes Técnicos: Qdrant (opens in a new tab) oferece tanto opções locais quanto baseadas em nuvem, tornando-o uma escolha flexível. No entanto, ele possui uma comunidade menor e poderia se beneficiar de documentação mais abrangente. Embora esteja ganhando popularidade, conjunto de recursos ainda está em crescimento e pode faltar algumas opções avançadas.
Link do Qdrant: https://qdrant.tech/ (opens in a new tab)

8. Cassandra/AstraDB: O Rei da Escalabilidade
Preço Inicial: Disponível na Camada Gratuita Avaliação: 4.3/5
Prós:
- Escalabilidade: Conhecido por lidar com alto rendimento sem falhar.
- Local e Baseado em Nuvem: Ambas as opções de implantação estão disponíveis.
- Reconhecimento na Indústria: Mantém sua posição na indústria há anos.
Contras:
- Complexidade: A curva de aprendizado é mais íngreme para novos usuários.
- Custo: A camada gratuita tem limitações e o preço pode aumentar.
- Suporte a Vetores: Não foi originalmente projetado para dados vetoriais, então alguns recursos podem estar faltando.
Detalhes Técnicos: Apache Cassandra (opens in a new tab)/DataStax AstraDB (opens in a new tab) é excelente em escalabilidade, mas possui uma curva de aprendizado íngreme. Embora ofereça uma camada gratuita, as limitações podem ser facilmente alcançadas, resultando em custos crescentes. Além disso, não foi originalmente projetado para dados vetoriais, então pode faltar alguns recursos especializados.
Apache Cassandra: https://cassandra.apache.org (opens in a new tab) DataStax AstraDB: https://www.datastax.com/products/datastax-astra (opens in a new tab)

9. MyScale DB: O Potencial SQL como Alternativa ao Pinecone
Preço Inicial: Generosa Camada Gratuita Avaliação: 4.1/5
Prós:
- Suporte SQL: Suporte completo e estendido ao SQL para todas as operações de dados.
- Velocidade: Arquitetura de banco de dados OLAP nativo em nuvem para operações rápidas.
- Dados Estruturados e Vetorizados: Gerencia ambos em um único banco de dados.
Contras:
- Novato: Relativamente novo e pode não ter suporte da comunidade.
- Documentação: Poderia se beneficiar de guias técnicos adicionais.
- Complexidade: Conhecimento em SQL é necessário, o que pode não ser adequado para todos os usuários.
Detalhes Técnicos: MyScale DB (opens in a new tab) oferece uma generosa camada gratuita e suporte SQL completo, tornando-o uma ótima escolha para aqueles familiarizados com SQL. No entanto, por ser um produto relativamente novo, pode não ter um suporte extenso da comunidade e pode se beneficiar de mais documentação técnica.
MyScale DB: https://myscale.com (opens in a new tab)
10. SPTAG (Space Partition Tree and Graph)
- Preço Inicial: Grátis (Código Aberto)
- Avaliação: 4.3/5
- Prós:
- Desenvolvido pela Microsoft, garantindo um nível de confiabilidade.
- Capacidades de pesquisa de k-NN em alta velocidade.
- Otimizado para bancos de dados em grande escala com bilhões de vetores.
- Contras:
- Suporte da comunidade limitado.
- Documentação não é tão extensa quanto outras opções de código aberto. Detalhes Técnicos: SPTAG (opens in a new tab) utiliza árvores KD-trees e Ball trees para indexação, permitindo buscas k-NN de alta velocidade. Ele é otimizado para bancos de dados em larga escala e pode lidar eficientemente com bilhões de vetores. O algoritmo também suporta busca com múltiplas threads e processamento de consultas em lote.
SPTAG GitHub: https://github.com/microsoft/SPTAG (opens in a new tab)
Perguntas frequentes
Quais são os principais bancos de dados de vetores?
Os principais bancos de dados de vetores até 2023 incluem Faiss, Annoy, NMSLIB, Milvus, Pinecone, Zilliz, Elasticsearch, Weaviate, Jina e SPTAG.
Existe algum banco de dados de vetores gratuito?
Sim, existem vários bancos de dados de vetores gratuitos e de código aberto disponíveis, como Faiss, Annoy, NMSLIB, Milvus, Weaviate, Jina e SPTAG.
O Pinecone é o melhor banco de dados de vetores?
Embora o Pinecone ofereça um serviço totalmente gerenciado e seja fácil de usar, se ele é o "melhor" depende de suas necessidades específicas. Não é de código aberto e pode ser caro para implantações maiores.
Como escolher um banco de dados de vetores?
A escolha de um banco de dados de vetores depende de vários fatores, como o tipo de dados com o qual você está trabalhando, a escala do seu projeto e o seu orçamento. Opções de código aberto como Faiss e Annoy são excelentes para aqueles que desejam ter mais controle e personalização, enquanto serviços gerenciados como o Pinecone podem ser mais adequados para aqueles que procuram facilidade de uso.
Conclusão
Bancos de dados de vetores são ferramentas essenciais para lidar com dados complexos e de alta dimensão. Embora ofereçam inúmeras vantagens, como busca eficiente de similaridade e escalabilidade, eles também têm suas próprias limitações. Opções de código aberto como Faiss e Annoy oferecem excelente desempenho e flexibilidade, mas podem exigir uma curva de aprendizado íngreme. Por outro lado, opções comerciais como o Pinecone oferecem facilidade de uso, mas podem ser caras. Portanto, é crucial avaliar cuidadosamente os prós e contras para escolher o banco de dados de vetores que melhor atenda às suas necessidades.
Quer saber as últimas notícias do LLM? Confira a classificação mais recente do LLM!
