LLaVA-Med:生物医学影像的下一个重大飞跃

医学影像领域正在经历一次范式转变。医疗保健专业人员过去完全依赖于敏锐的视力和多年的经验来解读医学扫描图像的时代已经过去了。现在出现了LLaVA-Med,它是备受赞誉的LLaVA模型的一种特殊变体,专门为生物医学领域而设计。这个强大的工具不仅仅是又一种科技产品;它代表了诊断和治疗规划的未来。无论是X光、MRI还是复杂的三维扫描,LLaVA-Med都提供了无与伦比的洞察力,填补了传统实践和尖端人工智能技术之间的差距。
想象一下,拥有一个能够在您指尖处对任何医学图像或文本进行深入分析的助手。那就是LLaVA-Med。它结合了准确性和多模态能力,无疑将成为全球医疗保健专业人员无可或缺的伙伴。让我们踏上一段探索旅程,看看这款工具的独特之处在哪里。
想了解最新的LLM新闻吗?请查看最新的LLM排行榜!
LLaVA-Med是什么?
LLaVA-Med是LLaVA模型的一个独特变体,专门针对生物医学领域进行了优化。它旨在解释和分析医学图像和文本,为医疗保健专业人员提供宝贵的工具。无论您在查看X光、MRI还是复杂的三维扫描,LLaVA-Med都能提供详细的洞察力,有助于诊断和治疗规划。
Microsoft fine-tuned the open-source #LLaVA, creating LLaVA-Med, a vision-language model able to interpret biomedical images. Imagine fine-tuning this model to read studies from your institution, generating texts that are both accurate and tailored to your language and tone. pic.twitter.com/rnSOWITTLB
— Paulo Kuriki, MD (@kuriki) October 8, 2023
LLaVA-Med的独特之处在哪里?
-
为医学数据进行了优化: 与通用的LLaVA模型不同,LLaVA-Med是在专门的数据集上进行训练的,该数据集包括医学期刊、临床笔记和各种医学图像。
-
高准确性: LLaVA-Med在解释医学图像时具有令人印象深刻的准确性,通常优于其他医学影像软件。
-
多模态能力: LLaVA-Med可以同时分析文本和图像,这使它非常适合解释常常包含书面笔记和医学图像混合内容的患者记录。
评估LLaVA-Med:它有多好?
当然,我会将提供的表格中的信息整合到文本中。
1. LLaVA-Med在生物医学视觉解释中的能力:
以广泛的LLaVA模型为基础,LLaVA-Med的卓越性在于对生物医学视觉数据的解释。
-
用于评估的基准数据集:LLaVA-Med以及其他模型在各种数据集上进行评估,具体的基准数据集包括VQA-RAD、SLAKE和PathVQA,用于测试模型在放射学、病理学等领域中进行视觉问题回答的能力。
-
监督微调结果: 下表显示了使用不同方法进行监督微调实验的结果:
| 方法 | VQA-RAD(参考) | VQA-RAD(开放) | VQA-RAD(封闭) | SLAKE(参考) | SLAKE(开放) | SLAKE(封闭) | PathVQA(参考) | PathVQA(开放) | PathVQA(封闭) |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA | 50.00 | 65.07 | 78.18 | 63.22 | 7.74 | 63.20 | |||
| LLaVA-Med (LLaVA) | 61.52 | 84.19 | 83.08 | 85.34 | 37.95 | 91.21 | |||
| LLaVA-Med (Vicuna) | 64.39 | 81.98 | 84.71 | 83.17 | 38.87 | 91.65 | |||
| LLaVA-Med (BioMed) | 64.75 | 83.09 | 87.11 | 86.78 | 39.60 | 91.09 |
指标描述:
-
方法:这表示正在评估的模型的特定版本或方法。它涵盖了LLaVA和LLaVA-Med的各种迭代和来源。
-
VQA-RAD(参考、开放、封闭):用于放射学中的视觉问题回答的指标。'参考'表示参考得分,'开放'表示开放式问题得分,而'封闭'则表示封闭式问题得分。
-
SLAKE(参考、开放、封闭):用于SLAKE基准测试的指标。'参考'表示参考得分,'开放'表示开放式问题得分,而'封闭'表示封闭式问题得分。
-
PathVQA(参考,开放型,封闭型):与病理学视觉问答相关的指标。 'Ref'表示参考分数,'Open'表示开放式问题分数,'Closed'表示封闭式问题分数。
参考资料:研究来源 (opens in a new tab)
通过将LLaVA-Med基于各种方法得出的结果进行对比,可以明显看出该模型在视觉生物医学解释方面表现出强大的性能,尤其是在与VQA-RAD和SLAKE等基准进行评估时。这种能力凸显了它在通过视觉数据为医疗专业人员提供更明智决策方面的潜力。
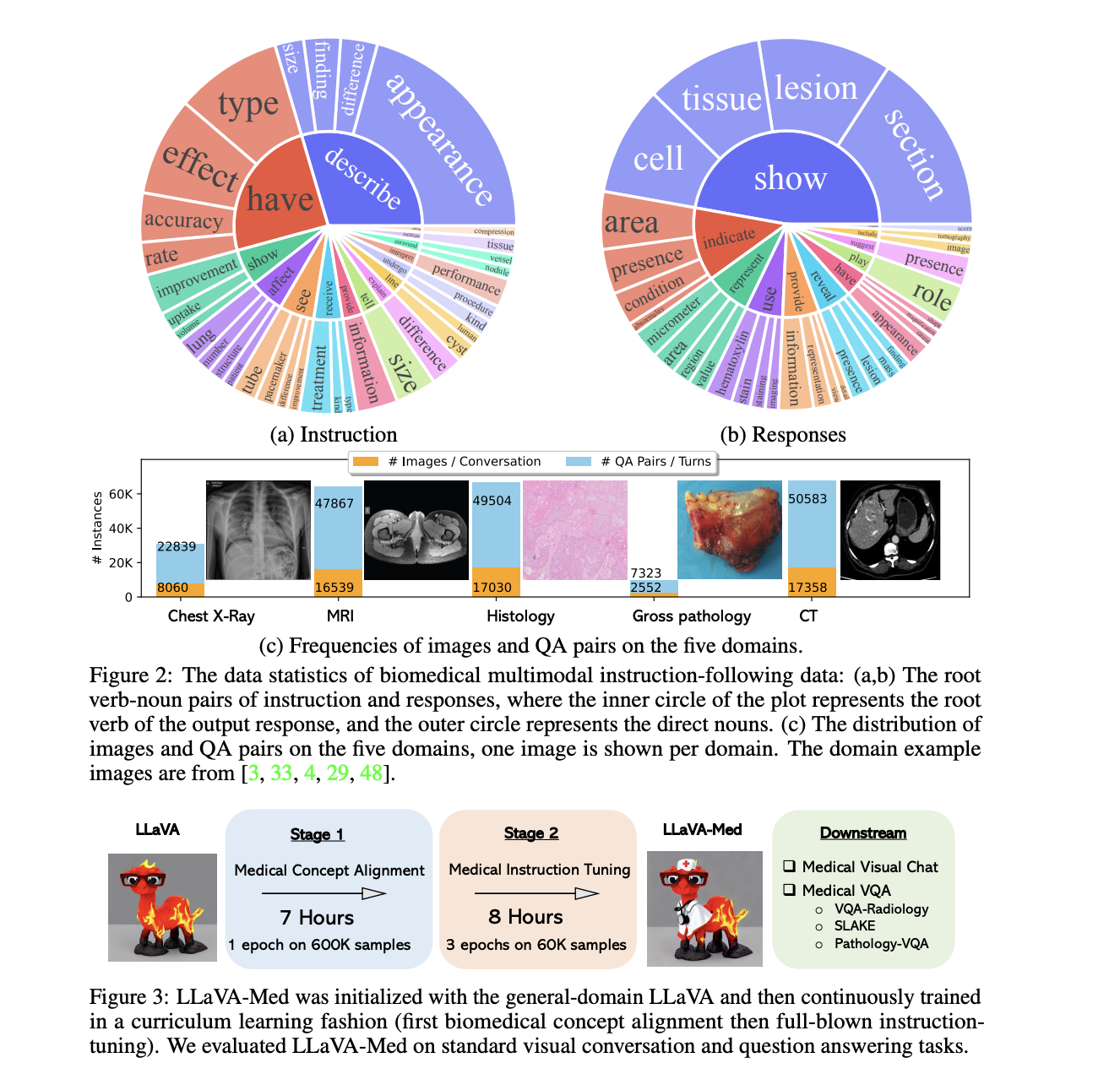
2. LLaVA-Med在指令遵循方面的能力:
LLaVA-Med从广泛的LLaVA模型中衍生出,其专业知识的突出表现得益于其对生物医学细微差别的专门强调。
-
模型细化的数据集:LLaVA-Med的改进使用了生物医学多模式指令遵循数据集。包含多样的真实生物医学背景,该数据集确保LLaVA-Med在医学知识表达和理解方面的熟练程度。
-
关于双阶段适应的见解:
- 阶段1(生物医学概念整合):这个基础阶段非常重要。它旨在将LLaVA的全面知识与独特的生物医学概念结合起来。这一步确保了随后的细化与医学复杂性保持一致。
- 阶段2(全面指令调整):作为关键节点,这个阶段对模型进行了强化训练,使其具备直观理解、参与和处理医学背景的能力。
LLaVA与LLaVA-Med的性能比较:
| 模型迭代 | 对话(%) | 描述(%) | 胸部X线(%) | 磁共振成像(%) | 组织学(%) | 解剖(%) | CT扫描(%) | 累计(%) |
|---|---|---|---|---|---|---|---|---|
| LLaVA | 39.4 | 26.2 | 41.6 | 33.4 | 38.4 | 32.9 | 33.4 | 36.1 |
| LLaVA-Med 阶段1 | 22.6 | 25.2 | 25.8 | 19.0 | 24.8 | 24.7 | 22.2 | 23.3 |
| LLaVA-Med 阶段2 | 52.4 | 49.1 | 58.0 | 50.8 | 53.3 | 51.7 | 52.2 | 53.8 |
指标描述:
-
模型迭代:指定正在审查的模型的特定迭代或阶段。包括总体LLaVA,LLaVA-Med主要阶段之后和次要阶段之后。
-
对话(%):突出模型在维持上下文对话并提供相关回答方面的熟练程度的度量标准。
-
描述(%):标记模型详尽阐述医学视觉的能力,确保传达的细节准确。
-
胸部X线(%):专用于评估LLaVA-Med在解释胸部X射线方面的准确性,这是临床诊断中不可或缺的工具。
-
磁共振成像(%):测量模型在分析和解释磁共振成像结果方面的能力。磁共振成像具有详细的洞察力,在医学诊断和治疗决策中至关重要。
-
组织学(%):反映模型在详细审查显微组织研究方面的效能,对于确定细胞异常非常重要。
-
解剖(%):衡量LLaVA-Med在阐述肉眼可见的解剖结构方面的能力,即不需要显微镜辅助的结构。
-
CT扫描(%):评估模型在解释计算机断层扫描的准确性,计算机断层扫描以其全面的横断面身体图像而闻名。
-
累计(%):综合分数,涵盖模型在各个类别中的性能。
参考资料:研究来源 (opens in a new tab)
3. LLaVA-Med视觉聊天机器人,简单来说:
LLaVA-Med不仅擅长言辞,而且在理解图片方面也很出色。
-
多才多艺:LLaVA-Med对不同的医学图像了如指掌。它可以查看从X光到磁共振成像甚至细小的组织图像的图片。
-
大量数据:是什么使其如此优秀?它看过并从许多图片和文本中学习过。因此,它了解诸如X光、身体扫描甚至简单的身体图片等事物。
-
在现实世界中的应用:想象一下医生们查看数百张X光片。LLaVA-Med可以通过快速检查这些图片,指出问题,并使医生的工作更轻松。
-
与GPT-4的比较:GPT-4在言辞方面表现出色。但是在理解医学图片并对其进行讨论方面,LLaVA-Med做得更好。它可以查看医学图片并详细讨论。
-
并非完美无缺:就像所有事物一样,LLaVA-Med也有其局限性。有时,如果图片与其所知的内容相差太大,它可能会感到困惑。但随着它看到更多的图片,它可以学习并变得更好。
您可以在此处 (opens in a new tab)测试在线版本的LLaVA-Med。
如何安装LLaVA-Med:逐步操作
与通用LLaVA模型相比,安装和运行LLaVA-Med需要更多步骤,因为它具有专门性质。以下是操作步骤:
步骤1:启动LLaVA-Med存储库
简化克隆:
首先,克隆LLaVA-Med存储库。打开终端并输入以下命令:
git clone https://github.com/microsoft/LLaVA-Med.git此命令直接从Microsoft的存储库中提取所有必要的文件到您的计算机。
步骤2:进入LLaVA-Med目录
导航基础知识:
克隆存储库后,您的下一步是切换工作目录。以下是操作步骤:
cd LLaVA-Med通过运行此命令,您将位于LLaVA-Med目录的核心位置,准备进行下一阶段。
步骤3:建立基础 - 安装软件包
以依赖性为基础的基础
每个复杂的软件都有其依赖关系。LLaVA-Med也不例外。通过以下命令,您将安装它正常运行所需的一切:
pip install -r requirements.txt请记住,这不仅仅是安装软件包。它是为了为LLaVA-Med创建一个有利的环境,以展示其功能。
第4步:与LLaVA-Med互动
运行示例提示以见证魔力:
准备好开始行动了吗?首先将LLaVA-Med模型整合到您的Python脚本中:
from LLaVAMed import LLaVAMed使模型运行起来:
model = LLaVAMed()深入研究示例医学文本分析:
text_output = model.analyze_medical_text("描述肺炎的症状。")
print(text_output)对于那些对医学图像分析感兴趣的人:
image_output = model.analyze_medical_image("路径/到/xray.jpg")
print(image_output)执行这些命令,揭示了LLaVA-Med的分析能力。例如,医学文本分析可能会阐明肺炎的症状、病因和潜在治疗方法。另一方面,图像分析可以指出X射线中的任何差异或异常。您可以查看LLaVA-Med GitHub源代码 (opens in a new tab)。
结论
尽管医学影像AI在准确性和效率方面显示出巨大的潜力,但在完全取代人类医生的阶段尚未到来。该技术作为辅助诊断的强大工具,但仍需要医疗专业人员的监督和经验,以提供最可靠和全面的护理。因此,重点应放在创建一个协同环境上,使AI和人类专业知识能够共存,提供最高质量的医疗保健。
想了解最新的LLM新闻?请查看最新的LLM排行榜!
