Groq AI 如何使 LLM 查询速度提升 10 倍

Groq 是一家生成式人工智能解决方案公司,利用其突破性的「语言处理单元(LPU)推理引擎」重新定义了大型语言模型(LLM)推理的现状。这款专为此而设计的加速器旨在克服传统 CPU 和 GPU 架构的局限,为 LLM 处理提供了无可比拟的速度和高效性。
想要了解最新的 LLM 新闻吗?请查看最新的LLM 排行榜!

LPU 体系结构:深入解析
Groq 的 LPU 体系结构的核心是一个以顺序性能为首要优化目标的单核设计。这种方法使得 LPU 可以获得出色的计算密度,在单芯片的峰值性能达到每秒 1 PetaFLOP。LPU 的独特体系结构还通过整合 220MB 片上静态随机存取存储器(SRAM),提供惊人的 1.5 TB/s 内存带宽,从而消除了外部内存瓶颈。
LPU 的同步网络功能使其在大规模部署中能够无缝扩展。通过每个 LPU 的双向带宽,达到每秒 1.6 TB/s,Groq 的技术能够有效处理 LLM 推理所需的海量数据传输。此外,LPU 支持从 FP32 到 INT4 的多种精度级别,即使在较低精度设置下也能实现高精度。
Groq 性能基准测试
在各种基准测试中,Groq 的 LPU 推理引擎始终优于业界巨头。在对 Meta AI 的 Llama-2 70B 模型进行的内部测试中,Groq 每个用户每秒可达到惊人的 300 个标记。这代表了 LLM 推理速度的显著飞跃,超过了传统基于 GPU 的系统的性能。
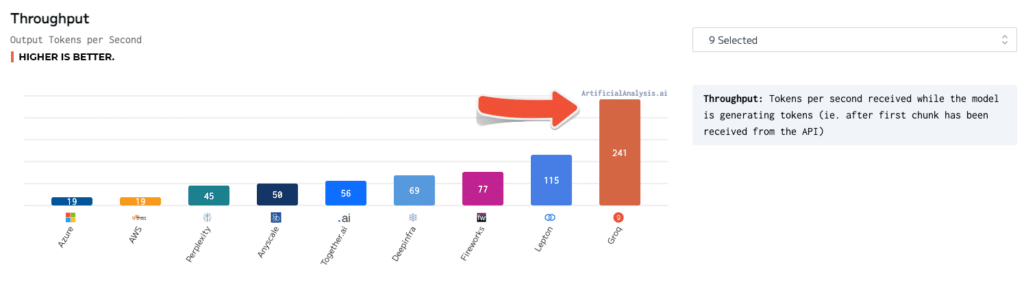
独立的基准测试进一步验证了 Groq 的卓越性能。在 ArtificialAnalysis.ai 进行的测试中,Groq 的 Llama 2 Chat(70B)API 每秒可处理 241 个标记的吞吐量,超过其他主机提供商的速度的两倍以上。Groq 在其他重要性能指标方面也表现优异,比如延迟 vs 吞吐量、总响应时间和吞吐量方差。
为了更好地理解这些数字,考虑一个用户与 AI 动力聊天机器人进行交互的场景。使用 Groq 的 LPU 推理引擎,聊天机器人可以以每秒 300 个标记的速度生成回复,实现近乎即时的对话。相比之下,基于 GPU 的系统可能只能达到每秒 50-100 个标记,导致明显的延迟和用户体验的降低。
Groq 与其他人工智能技术的比较

与 NVIDIA 的 GPU 相比,Groq 的 LPU 在 INT8 性能方面表现出明显的优势,这对于高速 LLM 推理至关重要。在将 LPU 与 NVIDIA 的 A100 GPU 进行比较的基准测试中,LPU 在 Llama-2 70B 模型上实现了 3.5 倍的加速,每秒处理 300 个标记,而 A100 只能处理每秒 85 个标记。
Groq 的技术还在与 ChatGPT 和 Google 的 Gemini 等其他 AI 模型的比较中脱颖而出。虽然这些模型的具体性能数据不公开,但 Groq 展示的速度和效率使得它有潜力在实际应用中超越它们。
使用 Groq AI
Groq 提供了一套全面的工具和服务,以便于部署和使用其 LPU 技术。GroqWare 套件包括 Groq 编译器,可提供快速启动和运行模型的一键式体验。以下是使用 Groq 编译器编译和运行模型的示例:
# 编译模型
groq compile model.onnx -o model.groq
# 在 LPU 上运行模型
groq run model.groq -i input.bin -o output.bin对于那些寻求更多定制化的用户,Groq 还允许手动编写 Groq 架构代码,以实现应用程序的定制化开发和最大性能优化。以下是一个简单矩阵乘法的手动编码的 Groq 汇编示例:
; Groq LPU 上的矩阵乘法
; 假设矩阵 A 和 B 已经加载到内存中
; 加载矩阵维度
ld r0, [n]
ld r1, [m]
ld r2, [k]
; 初始化结果矩阵 C
mov r3, 0
; 外部循环遍历 A 的行
mov r4, 0
loop_i:
; 内部循环遍历 B 的列
mov r5, 0
loop_j:
; 累加点积
mov r6, 0
mov r7, 0
loop_k:
ld r8, [A + r4 * m + r7]
ld r9, [B + r7 * k + r5]
mul r10, r8, r9
add r6, r6, r10
add r7, r7, 1
cmp r7, r2
jlt loop_k
; 将结果存储到 C
st [C + r4 * k + r5], r6
add r5, r5, 1
cmp r5, r2
jlt loop_j
add r4, r4, 1
cmp r4, r0
jlt loop_i开发人员和研究人员还可以通过 Groq API 利用 Groq 强大的技术,实现对实时推理能力的利用。以下是使用 Groq API 生成文本的示例,使用 Llama-2 70B 模型:
import groq
# 初始化 Groq 客户端
client = groq.Client(api_key="your_api_key")
# 设置模型和参数
model = "llama-2-70b"
prompt = "从前,有一次,在一个遥远的地方..."
max_tokens = 100
# 生成文本
response = client.generate(model=model, prompt=prompt, max_tokens=max_tokens)
# 打印生成的文本
print(response.text)潜在应用和影响
Groq的LPU推理引擎通过几乎即时的响应时间,为各行各业带来了新的可能性。在金融领域,Groq的技术可以用于实时欺诈检测和风险评估。通过处理大量的交易数据并在毫秒内识别异常,金融机构可以防止欺诈行为并保护客户的资产。
在医疗保健领域,Groq的LPU可以通过实时分析医疗数据来彻底改变患者护理。从处理医学影像到分析电子健康记录,Groq的技术可以帮助医疗专业人员进行快速准确的诊断,最终改善患者结果。
自动驾驶汽车也可以极大地受益于Groq的高速推理能力。通过处理传感器数据并做出瞬时决策,Groq驱动的人工智能系统可以提高自动驾驶汽车的安全性和可靠性,为智能交通的未来铺平道路。
结论
Groq的LPU推理引擎代表了人工智能加速领域的一大进步。凭借其创新的架构、令人印象深刻的基准测试以及全面的工具和服务套件,Groq赋予开发人员和组织推动大型语言模型的可能性。
随着对实时人工智能推理的需求不断增长,Groq有望引领下一代人工智能解决方案的推动。从聊天机器人和虚拟助手到自主系统等,Groq的技术的潜在应用是广泛且变革性的。
通过致力于民主化人工智能获取和促进创新,Groq不仅在技术领域革新,还在塑造我们与人工智能互动和受益的未来。当我们站在人工智能驱动时代的开端时,Groq的创新技术将成为未来几年里前所未有的进步和发现的催化剂。
想了解最新的LLM新闻吗?请查看最新的LLM排行榜!