LlamaIndex:扩展LLMs能力的LangChain替代方案

介绍:什么是LlamaIndex?
LlamaIndex是一种专为增强大型语言模型(LLMs)能力而设计的高性能索引工具。它不仅仅是一个查询优化器;它是一个全面的框架,提供响应合成、可组合性和高效的数据存储等高级功能。如果您处理复杂查询并需要高质量、上下文相关的响应,LlamaIndex是您的首选解决方案。
本文将对LlamaIndex进行技术深入剖析,探索其核心组件、高级功能以及如何在项目中有效实施。我们还将与类似的工具如LangChain进行比较,以便您完全了解其功能。
想了解最新的LLM新闻吗?查看最新的LLM排行榜!
究竟什么是LlamaIndex?
LlamaIndex是一种专门设计用于增强大型语言模型(LLMs)功能的工具。它作为特定LLM交互的全面解决方案,在需要精确查询和高质量响应的场景下表现出色。
查询:针对快速数据检索进行优化,适用于速度敏感的应用。 响应合成:精简流程,生成简洁并与上下文相关的响应。 可组合性:允许使用模块化和可重用的组件构建复杂的查询和工作流。
现在,让我们开始深入了解LlamaIndex的细节,好吗?
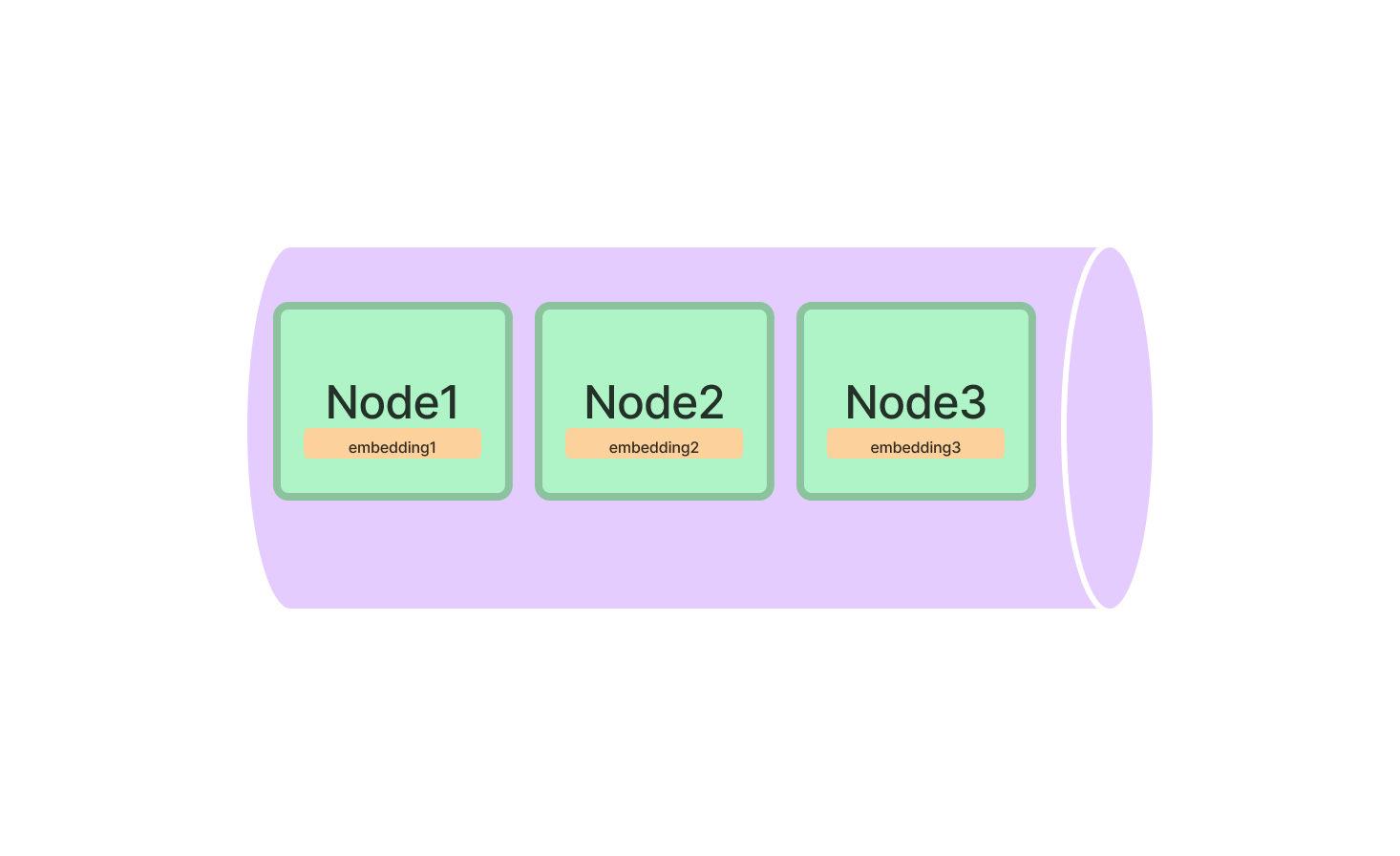
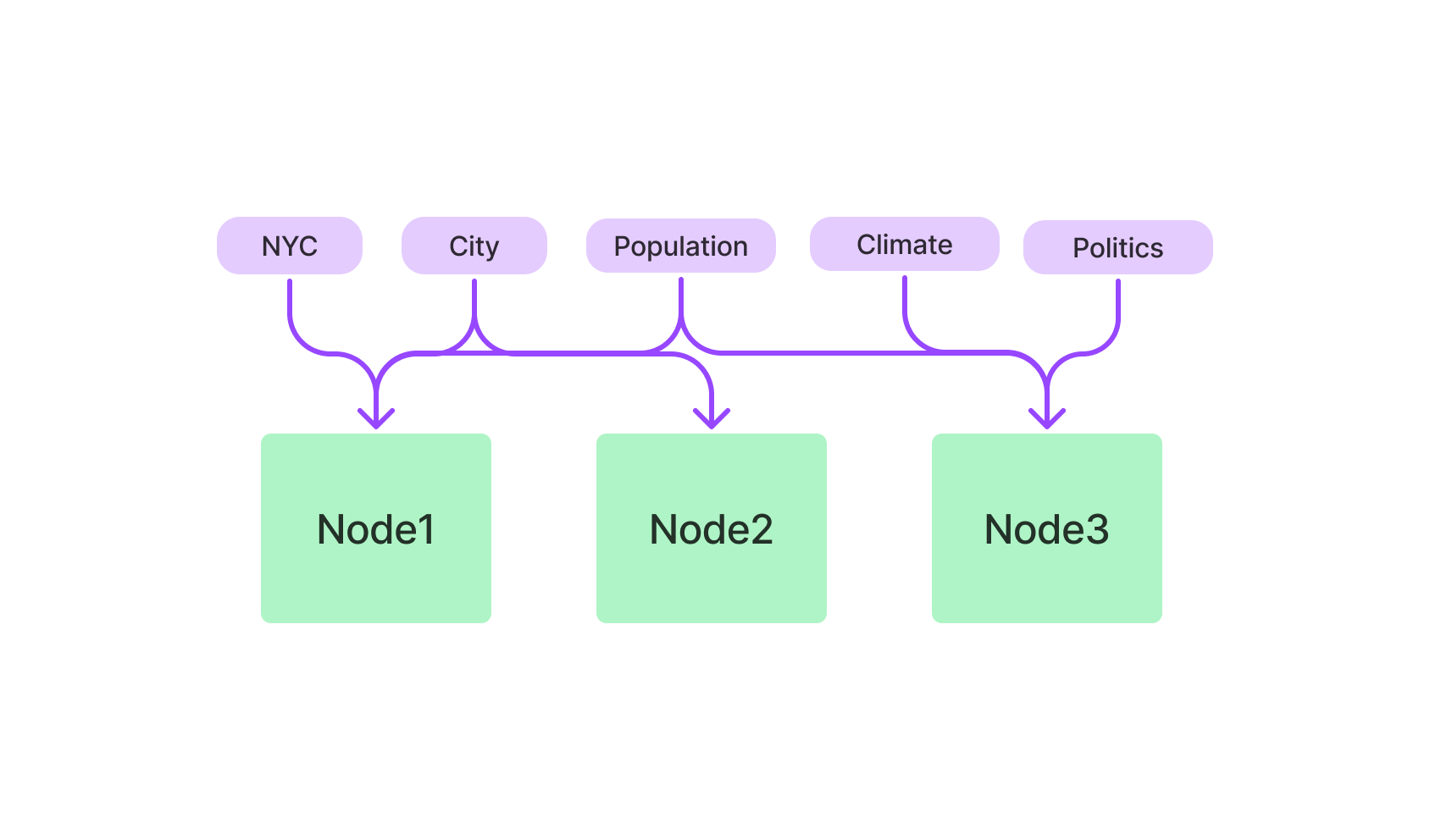
LlamaIndex中的索引是什么?
索引是LlamaIndex的核心,它们是保存要查询的信息的数据结构。LlamaIndex提供多种类型的索引,每种都针对特定任务进行了优化。

LlamaIndex中的索引类型
- 向量存储索引:利用k-NN算法,针对高维数据进行优化。
- 基于关键词的索引:使用TF-IDF算法进行文本查询。
- 混合索引:向量存储索引和基于关键词的索引的组合,提供平衡的方法。
LlamaIndex中的向量存储索引
向量存储索引是处理高维数据的首选工具。它特别适用于涉及复杂数据点的机器学习应用。
要开始使用,请从LlamaIndex软件包中导入VectorStoreIndex类,并在初始化时指定向量的维度。
from llamaindex import VectorStoreIndex
vector_index = VectorStoreIndex(dimensions=300)这将设置一个具有300个维度的向量存储索引,可以处理您的高维数据。现在,您可以向索引中添加向量并运行查询以找到最相似的向量。
# 添加向量
vector_index.add_vector(vector_id="vector_1", vector_data=[0.1, 0.2, 0.3, ...])
# 运行查询
query_result = vector_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)LlamaIndex中的基于关键词的索引
如果您更喜欢文本查询,则基于关键词的索引是您的好帮手。它使用TF-IDF算法来筛选文本数据,适用于自然语言查询。
首先从LlamaIndex软件包中导入KeywordBasedIndex类,然后进行初始化。
from llamaindex import KeywordBasedIndex
text_index = KeywordBasedIndex()现在,您可以向此索引添加文本数据并运行基于文本的查询。
# 添加文本数据
text_index.add_text(text_id="document_1", text_data="这是一个示例文档。")
# 运行查询
query_result = text_index.query(text="示例", top_k=3)使用LlamaIndex的快速入门:逐步指南
安装和初始化LlamaIndex只是个开始。要真正发挥其强大功能,您需要知道如何有效使用它。
安装LlamaIndex
首先,让我们将其安装到您的计算机上。打开终端并运行:
pip install llamaindex或者如果您使用conda:
conda install -c conda-forge llamaindex初始化LlamaIndex
安装完成后,您需要在Python环境中初始化LlamaIndex。这是为随后的所有魔力表演做准备的关键环节。
from llamaindex import LlamaIndex
index = LlamaIndex(index_type="vector_store", dimensions=300)在这里,index_type指定您要设置的索引类型,而dimensions用于指定向量存储索引的大小。
如何使用LlamaIndex的向量存储索引进行查询
成功设置LlamaIndex后,您可以探索其强大的查询能力。向量存储索引专为处理复杂的高维数据而设计,使其成为机器学习、数据分析和其他计算任务的首选工具。
在LlamaIndex中进行第一个查询
在深入了解代码之前,了解LlamaIndex查询的基本元素非常重要:
-
查询向量: 这是你希望在数据集中查找相似性的向量。它应该与你索引的向量在相同的多维空间中。
-
top_k参数: 这个参数指定你希望检索到的最接近查询向量的向量的数量。“k”代表你感兴趣的最近邻居的数量。
下面是如何进行第一次查询的步骤:
-
初始化你的索引: 确保你的索引已加载并准备好用于查询。
-
指定查询向量: 创建一个包含查询向量元素的列表或数组。
-
设置
top_k参数: 决定想要检索到多少个最近的向量。 -
执行查询: 使用
query方法执行搜索。
以下是一个示例的 Python 代码段来说明这些步骤:
# 初始化你的索引(假设它名为 'index')
# ...
# 定义查询向量
query_vector = [0.2, 0.4, 0.1, ...]
# 设置最近的向量数量
top_k = 5
# 执行查询
query_result = index.query(vector=query_vector, top_k=top_k)在 LlamaIndex 中进行查询的细化调整
为什么细化调整很重要?
细化调整你的查询可以使你将搜索过程适应你项目的特定要求。无论你处理文本、图像还是任何其他类型的数据,细化调整都可以显著提高查询的准确性和效率。
细化调整的关键参数:
-
距离度量: LlamaIndex 允许你选择不同的距离度量,例如 'euclidean' 和 'cosine'。
-
欧几里德距离: 这是欧几里德空间中两点之间“普通”的直线距离。在向量的大小很重要时使用这个度量。
-
余弦相似度: 这个度量衡量了两个向量之间夹角的余弦值。当你更关心向量的方向而不是大小时使用这个度量。
-
-
批大小: 如果你处理一个大的数据集或需要进行多次查询,设置批大小可以通过一次查询多个向量来加快处理速度。
细化调整的逐步指南:
这里是如何进行细化调整查询的步骤:
-
选择距离度量: 根据你的具体需求选择 'euclidean' 或 'cosine'。
-
设置批大小: 确定你想要一次处理的向量数量。
-
执行已细化调整的查询: 再次使用
query方法,但这次包括额外的参数。
以下是一个 Python 代码片段来演示:
# 定义查询向量
query_vector = [0.2, 0.4, 0.1, ...]
# 设置最近的向量数量
top_k = 5
# 选择距离度量
distance_metric = 'euclidean'
# 设置多次查询的批大小
batch_size = 100
# 执行已细化调整的查询
query_result = index.query(vector=query_vector, top_k=top_k, metric=distance_metric, batch_size=batch_size)通过掌握这些细化调整技巧,你可以使你的 LlamaIndex 查询更加有针对性和高效,从而从你的高维数据中获取最大价值。
用 LlamaIndex 可以做什么?
所以,你已经掌握了基础知识,但是用 LlamaIndex 实际上可以构建什么?可能性是巨大的,特别是当考虑到它与大型语言模型(LLMs)的兼容性时。
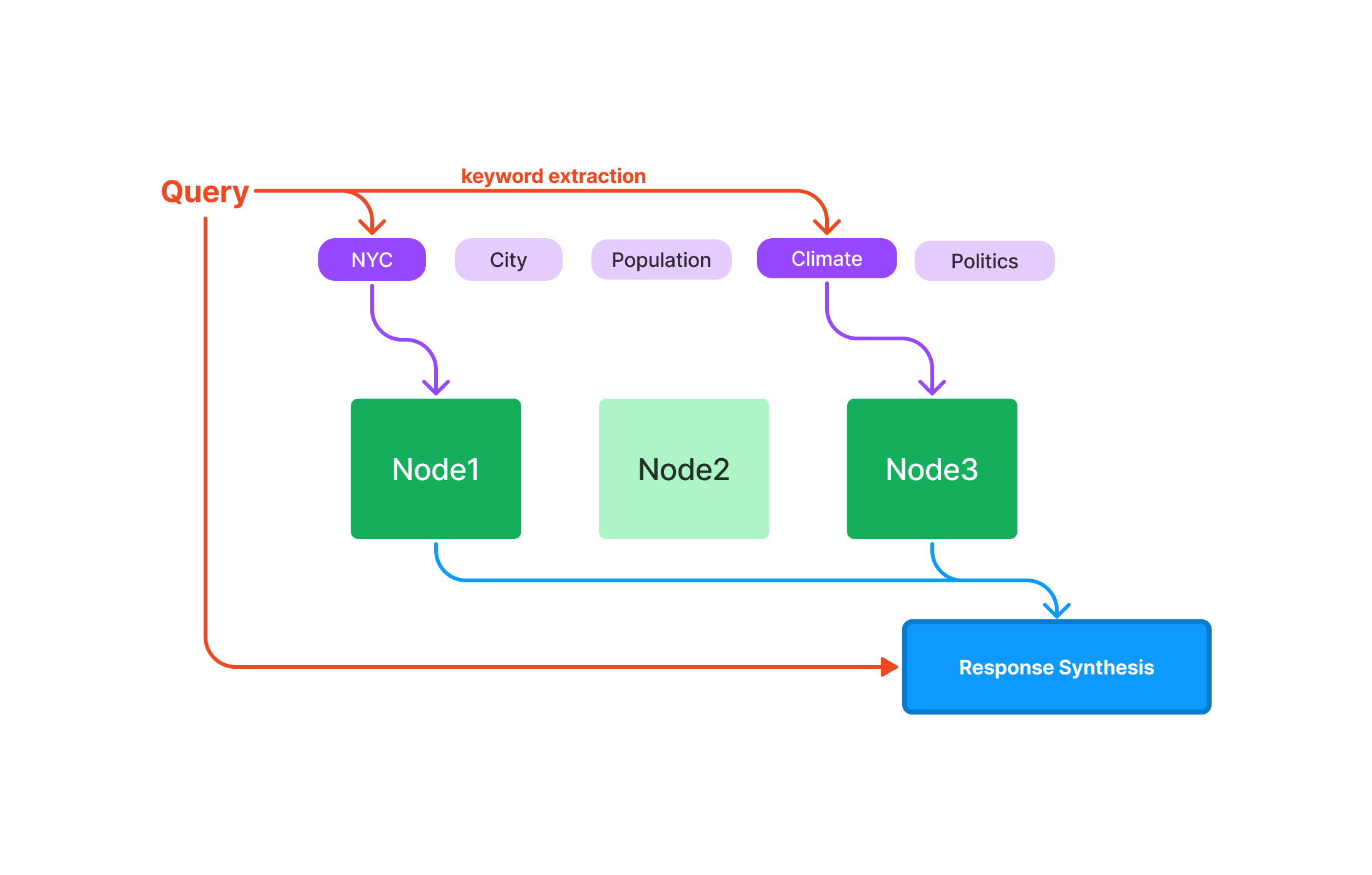
LlamaIndex 用于高级搜索引擎
LlamaIndex 最引人注目的用途之一是在高级搜索引擎领域。想象一下,一个搜索引擎不仅可以检索相关文档,而且还可以理解你的查询的上下文。通过 LlamaIndex,你可以构建一个这样的搜索引擎。
以下是一个快速示例,演示如何使用 LlamaIndex 的基于关键词的索引设置一个基本的搜索引擎。
# 初始化基于关键词的索引
from llamaindex import KeywordBasedIndex
search_index = KeywordBasedIndex()
# 添加一些文档
search_index.add_text("doc1", "羊驼太棒了。")
search_index.add_text("doc2", "我喜欢编程。")
# 运行查询
results = search_index.query("羊驼", top_k=2)LlamaIndex 用于推荐系统
另一个迷人的应用是构建推荐系统。无论是推荐类似的产品、文章还是歌曲,LlamaIndex 的向量存储索引都能起到改变游戏规则的作用。
以下是如何设置一个基本的推荐系统:
# 初始化向量存储索引
from llamaindex import VectorStoreIndex
rec_index = VectorStoreIndex(dimensions=50)
# 添加一些产品向量
rec_index.add_vector("product1", [0.1, 0.2, 0.3, ...])
rec_index.add_vector("product2", [0.4, 0.5, 0.6, ...])
# 运行一个查询来找到相似的产品
similar_products = rec_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)LlamaIndex vs. LangChain
在开发由大型语言模型(LLMs)驱动的应用程序时,选择框架可以对项目的成功产生重大影响。在这个领域中,两个引起关注的框架是 LlamaIndex 和 LangChain。它们都有各自独特的特点和优势,但它们满足不同的需求并针对特定的任务进行了优化。在本节中,我们将深入探讨技术细节,并提供样例代码,以帮助你理解这两个框架之间的关键区别,特别是在检索增强生成(RAG)方面,用于聊天机器人开发的上下文中。
核心特点和技术能力
LangChain
-
通用框架: LangChain 被设计为一种多功能工具,适用于各种应用。它不仅允许加载、处理和索引数据,还提供了与 LLMs 交互的功能。
样例代码:
const res = await llm.call("Tell me a joke"); -
灵活性:LangChain的显著特点之一是其灵活性。它允许用户广泛定制其应用程序的行为。
-
高级API:LangChain对于使用LLM进行工作的大多数复杂性进行了抽象,提供了简单易用的高级API。
示例代码:
const chain = new SqlDatabaseChain({ llm: new OpenAI({ temperature: 0 }), database: db, sqlOutputKey: "sql", }); const res = await chain.call({ query: "有多少首歌曲?" }); -
现成链路:LangChain预装了一些现成的链路,比如
SqlDatabaseChain,可以进行定制,也可以作为构建新应用程序的基础。
LlamaIndex
-
专为搜索和检索而设计:LlamaIndex专为构建搜索和检索应用程序而设计。它提供了一个简单的界面,用于查询LLM并检索相关文档。
示例代码:
query_engine = index.as_query_engine() response = query_engine.query("Stackoverflow 很棒。") -
效率:LlamaIndex经过优化,性能更好,更适合需要快速处理大量数据的应用程序。
-
数据连接器:LlamaIndex可以从多种来源摄入数据,包括API、PDF、SQL数据库等,实现与LLM应用程序的无缝集成。
-
优化索引:LlamaIndex的一个关键特点是它能够将摄入的数据结构化为中间表示形式,以便快速高效地查询。
如何选择框架?
-
通用应用程序:如果要构建一个需要灵活性和通用性的聊天机器人,LangChain是理想选择。其通用性和高级API使其适用于各种应用。
-
搜索和检索重点:如果您的聊天机器人的主要功能是搜索和检索信息,LlamaIndex是更好的选择。其专业的索引和检索功能使其在此类任务中非常高效。
-
组合使用:在某些情况下,同时使用这两个框架可能很有益。LangChain可以处理通用功能和与LLM的交互,而LlamaIndex可以管理专门的搜索和检索任务。这种组合可以提供一种平衡的方法,充分发挥LangChain的灵活性和LlamaIndex的高效性。
组合使用的示例代码:
# LangChain用于通用功能 res = llm.call("告诉我一个笑话") # LlamaIndex用于专门搜索 query_engine = index.as_query_engine() response = query_engine.query("告诉我关于气候变化的信息。")
应该选择LangChain还是LlamaIndex?
选择LangChain或LlamaIndex,或者决定同时使用两者,应该根据项目的具体要求和目标来指导。LangChain具有更广泛的功能范围,非常适合通用应用程序。相比之下,LlamaIndex专注于高效的搜索和检索,非常适合大数据处理任务。通过了解每个框架的技术细节和功能,您可以做出符合聊天机器人开发需求的明智决策。
总结
到目前为止,您应该已经对LlamaIndex有了很好的了解。从其专业索引到其广泛应用领域,再到其相对于其他工具(如LangChain)的优势,LlamaIndex无疑是与大型语言模型一起工作的不可或缺的工具。无论是构建搜索引擎、推荐系统还是任何需要高效查询和数据检索的应用程序,LlamaIndex都能满足您的需求。
LlamaIndex常见问题解答
让我们回答一些关于LlamaIndex最常见的问题。
LlamaIndex的用途是什么?
LlamaIndex主要用作用户和大型语言模型之间的中间层。它在执行查询、合成响应和数据集成方面表现出色,非常适合各种应用,如搜索引擎和推荐系统。
LlamaIndex是否免费使用?
是的,LlamaIndex是一款开源工具,可以免费使用。您可以在GitHub上找到其源代码,并为其开发做出贡献。
GPT Index和LlamaIndex是什么?
GPT Index专门用于基于文本的查询,通常与GPT(预训练生成变换器)模型一起使用。另一方面,LlamaIndex更加通用,可以处理基于文本和矢量的查询,与更广泛范围的大型语言模型兼容。
LlamaIndex的架构是什么?
LlamaIndex建立在模块化架构上,包括各种类型的索引,如矢量存储索引和基于关键词的索引。它主要使用Python编写,并支持多种算法,如kNN、TF-IDF和BERT嵌入。
想了解最新的大型语言模型新闻吗?请查看最新的大型语言模型排行榜!
