Llemma: 比GPT-4更好的数学LLM

在不断发展的人工智能领域中,语言模型已经成为许多应用的基石,从聊天机器人到内容生成。然而,对于数学等特定任务,不是所有的语言模型都能胜任。 Llemma是一款革命性的模型,旨在轻松解决复杂的数学问题。
虽然像GPT-4这样的模型在自然语言处理方面取得了重大进展,但在数学领域却表现不佳。本文旨在揭示Llemma的独特能力,并探讨为何即使像GPT-4这样的巨头在处理数字时也难以胜任。
什么是Llemma?
那么Llemma是什么呢?Llemma是一个开放的语言模型,经过微调以专攻数学。与通用模型不同,Llemma配备了计算工具,使其能够轻松解决复杂的数学问题。具体而言,它利用Python解释器和形式化定理证明器执行计算和证明定理。
-
Python解释器:Llemma可以执行Python代码进行复杂计算。这是与像GPT-4这样缺乏与外部计算工具交互能力的模型相比的显著优势。
-
形式化定理证明器:这些工具使Llemma能够自动证明数学定理。这在学术研究和数学建模中特别有用。

这些计算工具的集成使Llemma与竞争对手有所区别。它不仅能理解数学语言,还能进行计算和证明定理,为数学任务提供了全面的解决方案。
为何GPT-4在数学方面失败?标记化。
GPT-4在数学任务中的局限性一直是专家和爱好者们讨论的话题。尽管它在自然语言处理方面表现出色,但在数学计算方面的表现却不尽如人意。
标记化是任何语言模型中都至关重要的一个过程,但在数字方面,对于GPT-4来说尤为棘手。该模型的标记化过程并没有为数字提供独特的表示,从而引发了歧义。
-
多义性表示:例如,数字"143"可以被标记化为["143"]或["14","3"],或其他任何组合。这种缺乏标准表示的情况使得模型难以准确进行计算。
-
浪费的标记:一种解决方法是将每个数字分开标记化,但这种方法效率低下,因为它浪费了标记,而标记在语言模型中是宝贵的资源。
Llemma训练使用的数据集
数据是任何机器学习模型的命脉,Llemma也不例外。 Llemma最显著的一个方面之一是其使用的专门数据集,称为代数堆栈(AlgebraicStack)。该数据集包含110亿个与数学相关的代码标记。
-
标记的多样性:该数据集涵盖了从代数到微积分的各种数学概念,为模型提供了丰富的训练环境。
-
数据质量:AlgebraicStack中的标记是高质量且经过严格审核的,确保模型训练的数据可靠。
使用这样一个专门的数据集使得Llemma在数学方面达到了业内无与伦比的专业水平。重要的不仅是数据的数量,还有质量和特定性,这使Llemma成为数学界的奇才。
Llemma的工作原理是什么?
xVal:解决GPT-4的标记化问题
解决GPT-4的标记化问题的一个有趣解决方案是xVal的概念。这种方法建议使用一个通用的[NUM]标记,然后按照实际数字的值进行缩放。例如,数字"143"将被标记化为[NUM],并按照143进行缩放。该方法在主要涉及数字的序列预测问题中显示出有希望的结果。以下是一些关键点:
-
性能提升:xVal方法在性能方面比标准的标记化技术取得了显著改进。它在序列预测任务中比基准线模型领先70倍,比强基准线模型领先2倍。
-
多功能性:xVal的一个令人兴奋的方面是它在语言模型之外的领域也有潜在的应用价值。它可以成为处理数值数据的深度神经网络的一个重大突破。
虽然xVal为改善GPT-4的数学能力带来了一丝希望,但它仍处于试验阶段。而且,即使成功实施,它也只能作为一个更根本问题的临时解决方案。
Llemma的子模块和实验
Llemma并不只是一个独立的模型,它是一个更大生态系统的一部分,旨在推动语言模型在数学领域中的突破。该项目包含与重叠(overlap),**微调(fine-tuning)和定理证明实验(theorem proving experiments)**相关的各种子模块。
-
重叠子模块:重点研究Llemma在解决新的未知问题时的泛化能力。
-
微调子模块:涉及调整模型参数以优化其在特定数学任务中的性能。
-
Theorem Proving Experiments: 这些实验旨在测试 Llemma 自动证明复杂数学定理的能力。
这些子模块都为 Llemma 成为一个全面且高效的数学模型做出了贡献。它们作为新功能和优化的测试平台,确保 Llemma 保持在数学语言建模的前沿。
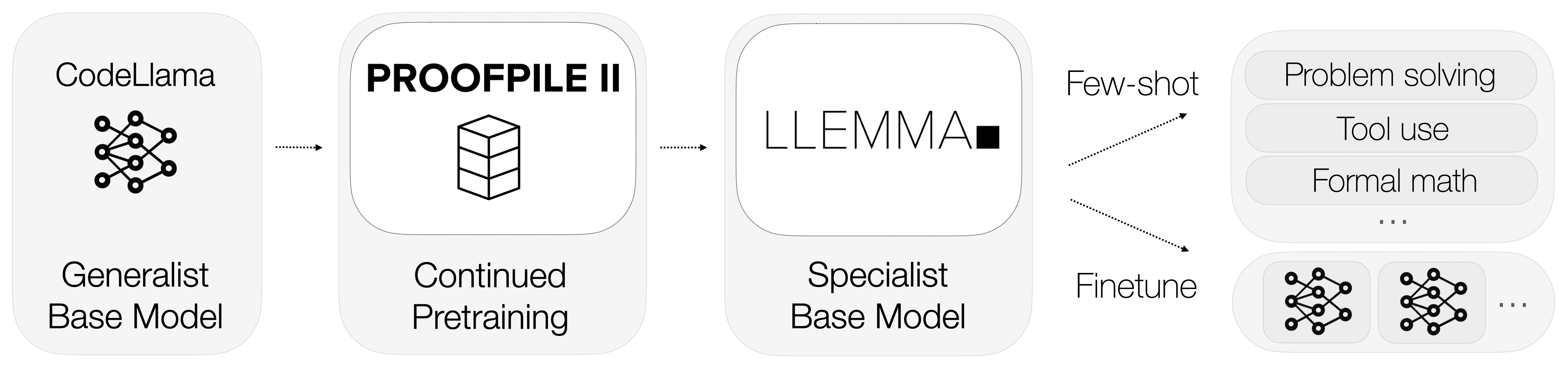
目前,我们应该清楚 Llemma 不仅仅是另一个语言模型;它是一个专为在数学领域出色而设计的专门工具。它整合了计算工具、专门的训练数据和持续的实验,使其成为不可忽视的力量。在下一节中,我们将深入探讨为什么即使是像 GPT-4 这样的先进模型在数学任务中也会遇到困难,以及 Llemma 如何超越它们。
Llemma vs. GPT-4:哪个更好?
把 Llemma 和 GPT-4 放在一起对比,差异非常明显。Llemma 在数学方面的专门专注,支持它的计算工具和专门数据集,使它具备了明显的优势。而另一方面,GPT-4 尽管在自然语言处理方面有着强大的表现,但由于其记号化问题,在数学任务上表现不佳。
-
准确性:得益于其专门的训练和计算工具,Llemma 在计算和定理证明方面具有高水准的准确性。相比之下,GPT-4 在五位数乘法方面几乎没有准确率(0%)。
-
灵活性:Llemma 的架构使其能够适应和在各种数学任务中脱颖而出,从基本计算到复杂定理证明。而 GPT-4 在数学方面缺乏这种适应性水平。
-
效率:Llemma 利用像 AlgebraicStack 这样的专门数据集,确保其在数学任务中训练的是高质量的数据,使其在效率上高度出色。GPT-4 由于其通用训练,无法与此效率水平相匹配。
总之,虽然 GPT-4 可能是一个全才,但 Llemma 是一个专家:数学。它的专门专注和先进功能使其成为任何数学任务的首选模型。在下一节中,我们将总结我们的讨论,并展望像 Llemma 这样的数学语言模型的未来。
结论:数学语言模型的未来
正如我们所见,Llemma 证明了专门语言模型可以取得的成就。它在解决数学问题和证明定理方面的独特能力使其与像 GPT-4 这样的通用模型区分开来。但是,对于数学领域的语言模型,这意味着什么呢?
-
专注于特定领域而非泛化:Llemma 的成功表明,未来的发展可能是针对特定任务定制的专门语言模型。虽然通用模型具有其优点,但 Llemma 带来的专业知识水平是无与伦比的。
-
整合计算工具:Llemma 对 Python 解释器和形式化定理证明器的使用可能为整合外部工具进行专门任务的未来模型铺平道路。这可能不仅局限在数学领域,还可能涉及物理学、工程学甚至医学等领域。
-
动态记号化:GPT-4 面临的标记化问题凸显了对更动态和灵活的记号化方法的需求,例如 xVal 解决方案。实施这些技术可显著提高通用模型在专门任务中的性能。
简而言之,Llemma 是专门语言模型可以及应该成为什么样子的一个蓝图。它不仅提高了数学语言模型的标准,还提供了对人工智能领域更广泛的宝贵见解。
参考资料
对于那些对数学语言模型世界更深入了解感兴趣的人,这里有一些可靠的资源供进一步阅读:
- Llemma 项目 GitHub 仓库 (opens in a new tab)
- AlgebraicStack 数据集 (opens in a new tab)
- xVal 研究论文 (opens in a new tab)
想了解最新的 LLM 新闻吗?请查看最新的 LLM 排行榜!
