Zephyr-7b:语言模型的新领域

如果您一直关注人工智能的进展,那么您可能已经听说过Zephyr-7b。这不仅仅是又一个语言模型;它是人工智能领域的一大突破。Zephyr-7b的设计不仅仅是一个聊天机器人,它在性能、效率和实用性方面开创了新的基准。
在人工智能越来越多地融入我们日常生活的世界中,Zephyr-7b成为了开源人工智能未来可能性的明灯。无论您是开发人员、技术爱好者还是对人工智能的最新进展感到好奇,本文都是您全面了解Zephyr-7b的指南。
想了解最新的LLM新闻吗?请查看最新的LLM排行榜!
Zephyr-7b是什么?
Zephyr-7b是从其前身Mistral-7B-v0.1微调而成的语言模型。它不仅仅是一个普通的模型;它被设计成一个有帮助的助手。那么它有什么与众不同的地方呢?答案在于它的训练方法——直接偏好优化(DPO)。这种技术使得Zephyr-7b在性能上具有优势,并使它比以往任何时候都更具帮助性。
- 模型类型:7B参数的类似GPT的模型。
- 语言:主要设计为英语。
- 许可证:采用CC BY-NC 4.0许可。
Zephyr-7b的独特功能
真正使Zephyr-7b与众不同的是其独特的功能,使其不仅仅是一个聊天机器人。它旨在提供帮助、高效和极其多功能。
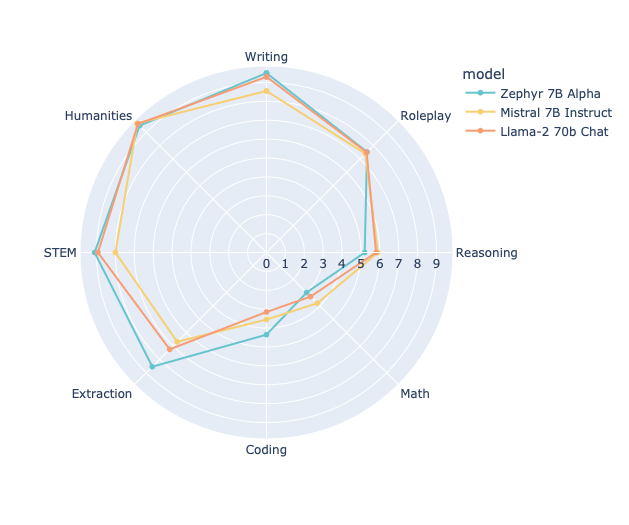
- 在MT Bench上的性能:Zephyr-7b在MT Bench上表现出色,优于其他模型如llama2-70b。
- 训练数据:该模型经过了公开可用数据和合成数据的混合训练,使其具有高韧性和多功能性。
- 成本效益:Zephyr-7b的训练总计算成本约为500美元,不仅强大而且经济高效。
直接偏好优化(DPO)的作用
DPO是塑造Zephyr-7b的训练方法的重要手段。与其他训练方法不同的是,DPO侧重于使模型的响应更符合人类的偏好。这导致了一个在基准测试中表现良好,并在实际应用中表现出色的模型。
以下是一个代码片段,以帮助您了解Zephyr-7b中DPO的工作原理:
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-alpha", torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])Zephyr-7b的技术规格:您需要了解的内容
要了解Zephyr-7b的实力,技术规格是关键。本节将深入探讨这款模型在语言模型领域中的出众之处。
模型类型和参数
Zephyr-7b是一款类似于GPT的模型,拥有70亿个参数。在语言模型领域,参数的数量通常是模型复杂性和功能的很好指标。
- 模型类型:类似GPT的模型,共7B个参数
- 支持的语言:主要英语
- 许可证:CC BY-NC 4.0
训练数据和方法:Zephyr-7b的支撑
Zephyr-7b最有趣的方面之一是它的训练数据和方法。与许多仅依赖公开可用数据的其他模型不同,Zephyr-7b使用了公开数据和合成数据的混合训练。这种多样化的训练数据为其韧性和多功能性做出了贡献。
- 训练数据:公开可用数据和合成数据混合
- 训练方法:直接偏好优化(DPO)
下面是一些训练超参数的快速查看:
- 学习率:5e-07
- 训练批大小:2
- 评估批大小:4
- 种子:42
- 优化器:Adam,betas=(0.9,0.999),epsilon=1e-08
评估指标:数据不会撒谎
Zephyr-7b经过了严格的评估,以测试其能力。该模型在各种指标上进行了评估,数字结果非常令人印象深刻。
- 损失:0.4605
- 奖励/选择:-0.5053
- 奖励/拒绝:-1.8752
- 奖励/准确性:0.7812
- 奖励/利润率:1.3699
这些指标不仅证明了模型的性能,还提供了关于其优势和改进空间的见解。
如何开始使用Zephyr-7b:逐步指南
如果您对Zephyr-7b和我们一样兴奋,您可能想知道如何开始使用它。那么您很幸运!本节将指导您逐步了解此划时代模型的步骤。
存储库和演示:入门的起点
首先,您需要查看官方代码库和演示,这些平台提供了您深入了解Zephyr-7b所需的所有资源。
运行Zephyr-7b的所需代码
由于Transformers库中的pipeline()函数的存在,使得运行Zephyr-7b变得简单直观。以下是一个示例代码片段,演示了如何运行该模型。
from transformers import pipeline
import torch
# 初始化pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-alpha", torch_dtype=torch.bfloat16, device_map="auto")
# 创建消息提示
messages = [
{"role": "system", "content": "你是一个友好的聊天机器人。"},
{"role": "user", "content": "给我讲一个笑话。"},
]
# 生成回复
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
# 打印生成的文本
print(outputs[0]["generated_text"])Zephyr-7b的实际应用和限制
虽然技术细节丰富多样,但任何语言模型的真正考验在于其实际应用。Zephyr-7b不例外,它的设计目的是为了实际应用。
聊天和对话界面
Zephyr-7b的主要应用之一是在聊天和对话界面中。该模型已经在UltraChat数据集的变体上进行了微调,使其能够处理各种对话场景。无论您是正在构建客户服务机器人还是交互式游戏,Zephyr-7b都可以胜任。
文本生成和内容创作
Zephyr-7b在文本生成方面也非常出色。无论您是希望自动生成文章,为网站创建动态响应,还是编写代码,Zephyr-7b的文本生成功能都能胜任任务。
限制:需要注意的事项
虽然Zephyr-7b是一个功能强大的工具,但了解它的限制非常重要。该模型尚未通过RLHF等技术与人类偏好进行调整,这意味着如果不正确管理,它可能会产生有问题的输出。在实际应用中部署Zephyr-7b时,始终确保拥有足够的过滤机制。
Zephyr-7b的未来展望
展望未来,我们可以明确地看到Zephyr-7b只是个开始。通过持续的研究和开发,我们可以预期该模型的更高级别版本,进一步推动语言模型领域的可能性。
即将推出的功能和增强
尽管当前版本的Zephyr-7b令人印象深刻,但即将推出一些功能和增强。其中包括但不限于:
- 通过改进的对齐技术实现更接近人类对话的互动
- 扩展到英语以外的多种语言
- 更强大的处理复杂查询和任务的能力
更广泛的影响:设定新的标准
Zephyr-7b不仅仅是一个模型,它是开源人工智能领域内潜力的体现。通过在性能、效率和实用性方面设定新的基准,Zephyr-7b为未来的模型奠定了基础,并塑造了人工智能的发展方向。
结论:Zephyr-7b的重要性
在充斥着各种语言模型的世界中,Zephyr-7b作为创新和实用性的象征脱颖而出。无论您是开发人员,希望将先进的人工智能集成到您的项目中,还是科技爱好者,渴望探索最新的进展,Zephyr-7b都能为您提供所需。其技术实力、实际应用和未来潜力使其成为值得探索的模型。
所以,如果您准备投身于开源人工智能的未来,Zephyr-7b将是您的入场券。不要错过这场革命,立即开始探索Zephyr-7b吧!
想了解最新的LLM新闻吗?查看最新的LLM排行榜!
