The Era of 1-bit Large Language Models: Microsoft Introduces BitNet b1.58
Published on
Introduction
Microsoft researchers have introduced a groundbreaking 1-bit Large Language Model (LLM) variant called BitNet b1.58, where every single parameter of the model is ternary, taking on values of 1. This 1.58-bit LLM matches the performance of full-precision (FP16 or BF16) Transformer LLMs with the same model size and training tokens, while being significantly more cost-effective in terms of latency, memory usage, throughput, and energy consumption. BitNet b1.58 represents a major step forward in making LLMs both high-performing and highly efficient.

What is BitNet b1.58?
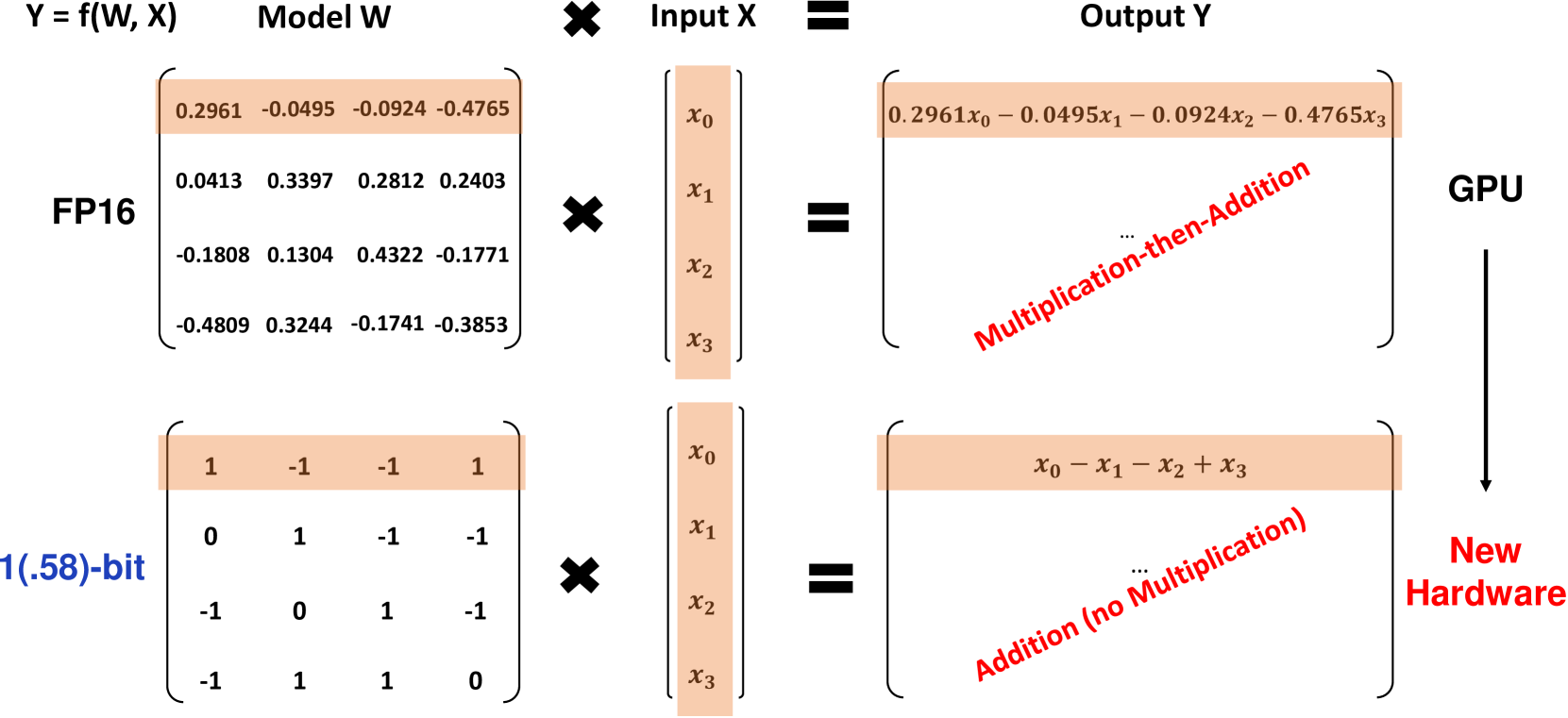
BitNet b1.58 is based on the original BitNet architecture, a Transformer model that replaces the standard nn.Linear layers with BitLinear layers. It is trained from scratch with 1.58-bit weights and 8-bit activations. Compared to the original 1-bit BitNet, b1.58 introduces a few key modifications:
-
It uses an absmean quantization function to constrain weights to 1. This rounds each weight to the nearest integer among those values after scaling by the average absolute value.
-
For activations, it scales them to the range [-sa, sa] per token, simplifying implementation compared to the original BitNet.
-
It adopts components from the popular open-source LLaMA architecture, including RMSNorm, SwiGLU activations, rotary embeddings, and removes biases. This allows easy integration with existing LLM software.
The addition of the 0 value to the weights enables feature filtering, boosting the modeling capability compared to pure 1-bit models. Experiments show BitNet b1.58 matches FP16 baselines in perplexity and end-task performance starting at a 3B parameter size.
Performance Results
The researchers compared BitNet b1.58 to a reproduced FP16 LLaMA LLM baseline at various model sizes from 700M to 70B parameters. Both were pre-trained on the same RedPajama dataset for 100B tokens and evaluated on perplexity and a range of zero-shot language tasks.
Key findings include:
-
BitNet b1.58 matches the perplexity of the FP16 LLaMA baseline at 3B size, while being 2.71x faster and using 3.55x less GPU memory.
-
A 3.9B BitNet b1.58 outperforms the 3B LLaMA in perplexity and end tasks with lower latency and memory cost.
-
On zero-shot language tasks, the performance gap between BitNet b1.58 and LLaMA narrows as model size increases, with BitNet matching LLaMA at 3B size.
-
Scaling up to 70B, BitNet b1.58 achieves 4.1x speedup over the FP16 baseline. Memory savings also increase with scale.
-
BitNet b1.58 uses 71.4x less energy for matrix multiplications. End-to-end energy efficiency increases with model size.
-
On two 80GB A100 GPUs, a 70B BitNet b1.58 supports 11x larger batch sizes than LLaMA, enabling 8.9x higher throughput.
The results demonstrate that BitNet b1.58 provides a Pareto improvement over state-of-the-art FP16 LLMs - it is more efficient in latency, memory, and energy while matching perplexity and end-task performance at sufficient scale. For example, a 13B BitNet b1.58 is more efficient than a 3B FP16 LLM, a 30B BitNet more efficient than 7B FP16, and a 70B BitNet more efficient than a 13B FP16 model.
When trained on 2T tokens following the StableLM-3B recipe, BitNet b1.58 outperformed StableLM-3B zero-shot on all evaluated tasks, showing strong generalization.
The tables below provide more detailed data on the performance comparisons between BitNet b1.58 and the FP16 LLaMA baseline:
| Models | Size | Memory (GB) | Latency (ms) | PPL |
|---|---|---|---|---|
| LLaMA LLM | 700M | 2.08 (1.00x) | 1.18 (1.00x) | 12.33 |
| BitNet b1.58 | 700M | 0.80 (2.60x) | 0.96 (1.23x) | 12.87 |
| LLaMA LLM | 1.3B | 3.34 (1.00x) | 1.62 (1.00x) | 11.25 |
| BitNet b1.58 | 1.3B | 1.14 (2.93x) | 0.97 (1.67x) | 11.29 |
| LLaMA LLM | 3B | 7.89 (1.00x) | 5.07 (1.00x) | 10.04 |
| BitNet b1.58 | 3B | 2.22 (3.55x) | 1.87 (2.71x) | 9.91 |
| BitNet b1.58 | 3.9B | 2.38 (3.32x) | 2.11 (2.40x) | 9.62 |
Table 1: Perplexity and cost comparison of BitNet b1.58 and LLaMA LLM.
| Models | Size | ARCe | ARCc | HS | BQ | OQ | PQ | WGe | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA LLM | 700M | 54.7 | 23.0 | 37.0 | 60.0 | 20.2 | 68.9 | 54.8 | 45.5 |
| BitNet b1.58 | 700M | 51.8 | 21.4 | 35.1 | 58.2 | 20.0 | 68.1 | 55.2 | 44.3 |
| LLaMA LLM | 1.3B | 56.9 | 23.5 | 38.5 | 59.1 | 21.6 | 70.0 | 53.9 | 46.2 |
| BitNet b1.58 | 1.3B | 54.9 | 24.2 | 37.7 | 56.7 | 19.6 | 68.8 | 55.8 | 45.4 |
| LLaMA LLM | 3B | 62.1 | 25.6 | 43.3 | 61.8 | 24.6 | 72.1 | 58.2 | 49.7 |
| BitNet b1.58 | 3B | 61.4 | 28.3 | 42.9 | 61.5 | 26.6 | 71.5 | 59.3 | 50.2 |
| BitNet b1.58 | 3.9B | 64.2 | 28.7 | 44.2 | 63.5 | 24.2 | 73.2 | 60.5 | 51.2 |
Table 2: Zero-shot accuracy of BitNet b1.58 and LLaMA LLM on end tasks.
The decoding latency and memory consumption of BitNet b1.58 at different model sizes are shown in Figure 1. The speedup increases with model size, reaching 4.1x at 70B parameters compared to the FP16 baseline. Memory savings also grow with scale.
Refer to caption Refer to caption Figure 1: Decoding latency (left) and memory consumption (right) of BitNet b1.58 at different model sizes.
In terms of energy efficiency, BitNet b1.58 uses 71.4x less energy for matrix multiplications compared to FP16 LLMs. The end-to-end energy cost across model sizes is illustrated in Figure 2, showing BitNet b1.58 becomes increasingly more efficient at larger scales.
Refer to caption
Refer to caption
Figure 2: Energy consumption of BitNet b1.58 compared to LLaMA LLM. Left: Components of arithmetic operations energy. Right: End-to-end energy cost across model sizes.
Throughput is another key advantage of BitNet b1.58. On two 80GB A100 GPUs, a 70B BitNet b1.58 supports batch sizes 11x larger than a 70B LLaMA LLM, resulting in 8.9x higher throughput, as shown in Table 3.
| Models | Size | Max Batch Size | Throughput (tokens/s) |
|---|---|---|---|
| LLaMA LLM | 70B | 16 (1.0x) | 333 (1.0x) |
| BitNet b1.58 | 70B | 176 (11.0x) | 2977 (8.9x) |
Table 3: Throughput comparison of 70B BitNet b1.58 and LLaMA LLM.
Implications and Future Directions
The BitNet b1.58 architecture and results have significant implications for the future of LLMs:
-
It establishes a new Pareto frontier and scaling law for LLMs that are both high-performing and highly efficient. 1.58-bit LLMs can match FP16 baselines at dramatically lower inference costs.
-
The drastic memory reduction enables running much larger LLMs on a given amount of hardware. This is especially impactful for memory-intensive architectures like mixture-of-experts.
-
8-bit activations can double the context length possible with a given memory budget compared to 16-bit. Further compression to 4-bit or lower is possible in the future.
-
The exceptional efficiency of 1.58-bit LLMs on CPU devices opens up deployment of powerful LLMs on edge/mobile, where CPUs are the main processor.
-
The new low-bit computation paradigm of BitNet b1.58 motivates designing custom AI accelerators and systems optimized specifically for 1-bit LLMs to fully leverage the potential.
Microsoft sees 1-bit LLMs as a highly promising path to making LLMs dramatically more cost-effective while preserving their capabilities. They envision an era where 1-bit models power applications from the data center to the edge. However, reaching that future will require co-designing the model architectures, hardware, and software systems to fully harness the unique properties of these models. BitNet b1.58 establishes an exciting starting point for this new era of LLMs.
Conclusion
BitNet b1.58 represents a major breakthrough in pushing large language models to the limit of quantization while preserving performance. By leveraging ternary 1 weights and 8-bit activations, it matches FP16 LLMs in perplexity and end-task performance with dramatically lower memory usage, latency, and energy consumption.
The 1.58-bit architecture establishes a new Pareto frontier for LLMs, where larger models can be run at a fraction of the cost. It opens up new possibilities like natively supporting longer context, deploying powerful LLMs on edge devices, and motivates designing custom hardware for low-bit AI.
Microsoft's work demonstrates that aggressively quantized LLMs are not just viable but in fact establish a superior scaling law compared to FP16 models. With further co-design of architectures, hardware and software, 1-bit LLMs have the potential to power the next major leap in cost-effective AI capabilities from cloud to edge. BitNet b1.58 provides an impressive starting point for this exciting new era of ultra-efficient large language models.