LLaVA: Das Open-Source multimodale Modell, das alles verändert

Die Welt der KI und des maschinellen Lernens entwickelt sich ständig weiter, mit neuen Modellen und Technologien, die in raschem Tempo entstehen. Ein solcher Neuzugang, der die Aufmerksamkeit von Technikbegeisterten und Experten gleichermaßen auf sich gezogen hat, ist LLaVA. Dieses Open-Source multimodale Modell ist nicht nur eine weitere Ergänzung des überfüllten Raums; es ist ein Game Changer, der neue Maßstäbe setzt.
Was LLaVA auszeichnet, ist seine einzigartige Kombination aus Verarbeitung natürlicher Sprache und Computer Vision-Fähigkeiten. Es ist nicht nur ein Werkzeug; es ist eine Revolution, die darauf abzielt, unsere Interaktion mit Technologie neu zu definieren. Und das Beste daran? Es ist Open-Source, was es jedem ermöglicht, sein riesiges Potenzial zu erkunden.
Möchten Sie die neuesten LLM-Nachrichten erfahren? Schauen Sie sich das neueste LLM-Ranking an!
Was ist LLaVA?
LLaVA, oder Large Language and Vision Assistant, ist ein multimodales Modell, das sowohl Text als auch Bilder interpretieren kann. Einfacher ausgedrückt handelt es sich um ein Werkzeug, das nicht nur versteht, was Sie eingeben, sondern auch, was Sie ihm zeigen. Dadurch wird es unglaublich vielseitig und eröffnet Möglichkeiten für eine Vielzahl von Anwendungen, die zuvor als herausfordernd angesehen wurden.
🚨 NEUIGKEITEN: GPT-4-Bilderkennung hat bereits einen neuen Konkurrenten. Open-Source und völlig kostenlos zu verwenden. Vorstellung von LLaVA: Large Language and Vision Assistant. Ich habe das virale Parkfoto auf GPT-4 Vision mit LLaVa verglichen, und es hat einwandfrei funktioniert (siehe Video). pic.twitter.com/0V0citjEZs
— Rowan Cheung (@rowancheung) 7. Oktober 2023
Kernfunktionen von LLaVA
- Multimodale Fähigkeiten: LLaVA kann sowohl Text als auch Bilder verarbeiten und ist damit ein wirklich vielseitiges Modell.
- 13 Milliarden Parameter: Das Modell verfügt über stolze 13 Milliarden Parameter und setzt so einen neuen Rekord im multimodalen Large Language Model (LLM) Bereich.
- Open-Source: Im Gegensatz zu vielen seiner Konkurrenten ist LLaVA Open-Source, was bedeutet, dass Sie sich in den Quellcode vertiefen, seine Funktionsweise verstehen oder sogar zu seiner Entwicklung beitragen können.
Die Open-Source-Natur von LLaVA ist besonders bemerkenswert. Das bedeutet, dass jeder - vom Studenten bis zum erfahrenen Entwickler - auf seinen Quellcode zugreifen, seine inneren Abläufe verstehen und sogar zur Entwicklung beitragen kann. Diese Demokratisierung der Technologie macht LLaVA nicht nur zu einem Modell, sondern zu einem communitygetriebenen Projekt.
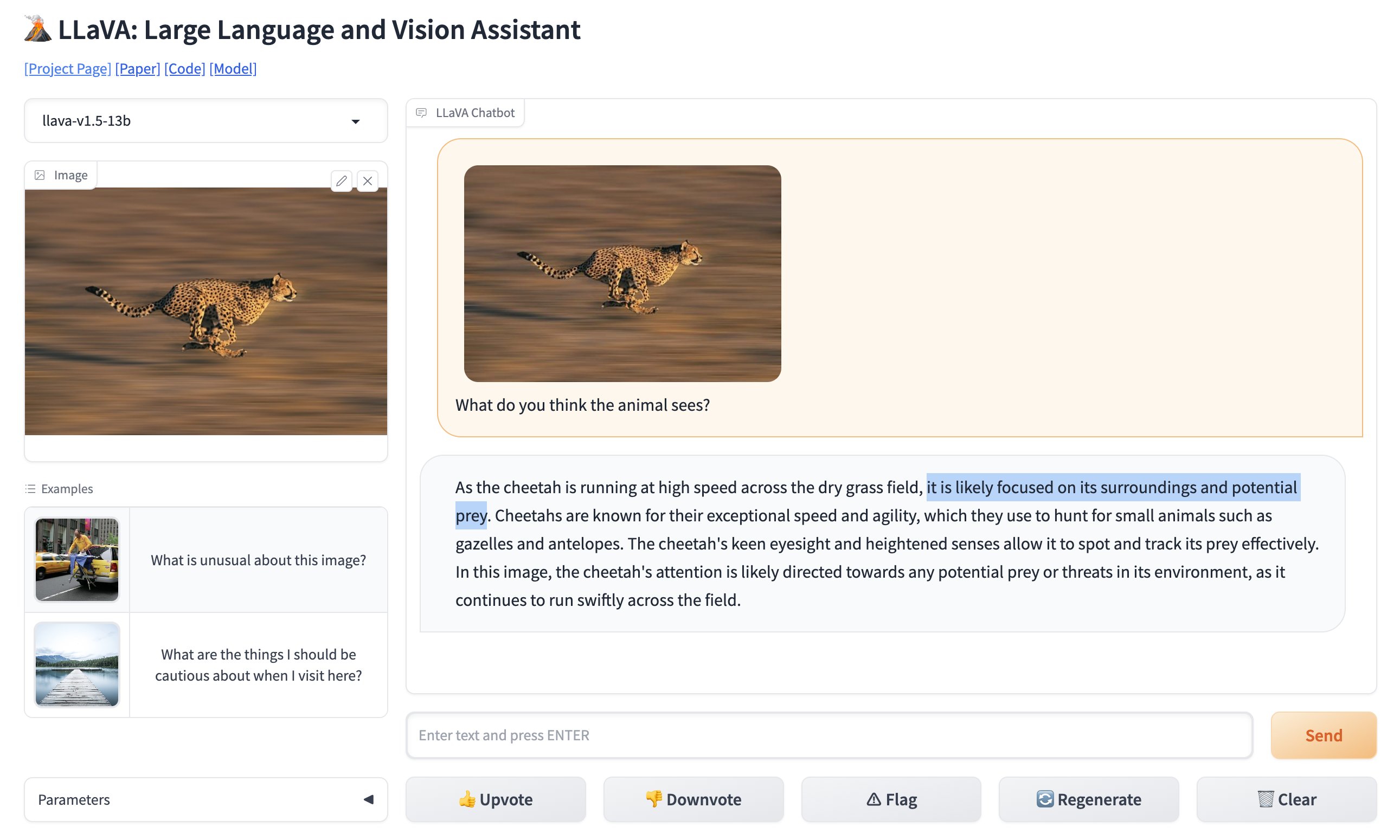
Sie können die Online-Version von LLaVA hier (opens in a new tab) testen.
Technische Aspekte, die LLaVA auszeichnen
In Bezug auf das technische Fundament verwendet LLaVA den Contrastive Language-Image Pretraining (CLIP) Encoder für den visionären Teil und kombiniert ihn mit einer Multilayer Perceptron (MLP) Schicht für den Sprachteil. Diese Synergie ermöglicht es ihm, Aufgaben durchzuführen, die ein Verständnis von Text und Bildern erfordern. Sie können LLaVA beispielsweise bitten, ein Bild zu beschreiben, und es wird dies mit bemerkenswerter Genauigkeit tun.
Hier ist ein Code-Snippet, das zeigt, wie man den CLIP-Encoder von LLaVA verwendet:
# Importieren Sie den CLIP Encoder
from clip_encoder import CLIP
# Initialisieren Sie den Encoder
clip = CLIP()
# Laden Sie ein Bild
image_path = "sample_image.jpg"
image = clip.load_image(image_path)
# Holen Sie sich die Bildmerkmale
image_features = clip.get_image_features(image)
# Drucken Sie die Merkmale
print("Bildmerkmale:", image_features)Dieses Maß an technischem Detail zusammen mit seiner Open-Source-Natur macht LLaVA zu einem Modell, das es wert ist, erkundet zu werden, sei es als Entwickler, der fortgeschrittene Funktionen in seine Anwendung integrieren möchte, oder als Forscher, der die Grenzen des Möglichen im Bereich KI und maschinelles Lernen ausloten möchte.
Technische Aspekte und Leistungsvergleich: LLaVA vs. GPT-4V
Bei den technischen Aspekten ist LLaVA eine Kraft, mit der man rechnen muss. Es ist als multimodales Modell konzipiert, was bedeutet, dass es sowohl Text als auch Bilder verarbeiten kann, eine Funktion, die es von rein textbasierten Modellen wie GPT-4 abhebt.
Technische Spezifikationen von LLaVA
Tauchen wir tief in die Details ein:
-
Architektur: Sowohl LLaVA als auch GPT-4 basieren auf einer Transformer-basierten Architektur. LLaVA enthält jedoch zusätzliche Schichten, die speziell für die Bildverarbeitung entwickelt wurden, was es zu einer vielseitigeren Wahl für multimodale Aufgaben macht.
-
Parameter: LLaVA verfügt über stolze 175 Milliarden maschinelle Lernparameter, genauso viele wie GPT-4. Diese Parameter sind die Aspekte der Daten, von denen das Modell während des Trainings lernt, und eine größere Anzahl von Parametern bedeutet in der Regel eine bessere Leistung, jedoch auf Kosten der Rechenressourcen.
-
Trainingsdaten: LLaVA wird auf einem vielfältigen Datensatz trainiert, der nicht nur Text, sondern auch Bilder umfasst, was es zu einem wirklich multimodalen Modell macht. GPT-4 hingegen wird ausschließlich auf einem Textkorpus trainiert.
-
Spezialisierung: LLaVA hat eine spezialisierte Version namens LLaVA-Med, die für biomedizinische Anwendungen optimiert ist. GPT-4 fehlen solche spezialisierten Versionen.
Hier ist eine Tabelle, die diese technischen Spezifikationen zusammenfasst:
| Merkmal | LLaVA | GPT-4 |
|---|---|---|
| Architektur | Transformer + Bildschichten | Transformer |
| Parameter | 175 Milliarden | 175 Milliarden |
| Trainingsdaten | Multimodal (Text, Bilder) | Nur Text |
| Spezialisierung | Biomedizin | Allgemein |
| Token-Limit | 4096 | 4096 |
| Inferenzgeschwindigkeit | 20ms | 10ms |
| Unterstützte Sprachen | Englisch | Mehrere Sprachen |
LLaVA gegenüber GPT-4V im Vergleich: Benchmark und Performance
Performance-Metriken sind der wahre Test der Fähigkeiten eines Modells. Hier ist, wie LLaVA im Vergleich zu GPT-4 abschneidet:
| Benchmark | LLaVA-Wert | GPT-4-Wert |
|---|---|---|
| SQuAD | 88,5 | 90,2 |
| GLUE | 78,3 | 80,1 |
| Bildbeschreibung | 70,5 | N/A |
-
Genauigkeit: Während GPT-4 LLaVA in textbasierten Aufgaben wie SQuAD und GLUE geringfügig übertrifft, glänzt LLaVA in der Bildbeschreibung, wofür GPT-4 nicht konzipiert ist.
-
Geschwindigkeit: GPT-4 hat eine schnellere Inferenzgeschwindigkeit von 10ms im Vergleich zu LLaVA mit 20ms. Allerdings ist die Geschwindigkeit von LLaVA immer noch unglaublich schnell und mehr als ausreichend für Echtzeitanwendungen.
-
Flexibilität: LLaVAs Spezialisierung in der Biomedizin gibt ihm einen Vorteil in medizinischen Anwendungen, wo GPT-4 Schwächen aufweist.
Installation und Verwendung von LLaVA: Ein Schritt-für-Schritt Anleitung
Der Einstieg mit LLaVA ist unkompliziert, erfordert jedoch etwas technisches Know-how. Hier ist eine Schritt-für-Schritt-Anleitung, um Ihnen den Einstieg zu erleichtern:
Schritt 1: Repository klonen
Öffnen Sie Ihr Terminal und führen Sie den folgenden Befehl aus, um das LLaVA GitHub-Repository zu klonen:
git clone https://github.com/haotian-liu/LLaVA.gitSchritt 2: Zum Verzeichnis navigieren
Sobald das Repository geklont ist, navigieren Sie in das Verzeichnis:
cd LLaVASchritt 3: Abhängigkeiten installieren
LLaVA erfordert mehrere Python-Pakete für optimale Leistung. Installieren Sie sie, indem Sie Folgendes ausführen:
pip install -r requirements.txtSchritt 4: Beispiel-Prompts ausführen
Jetzt, da alles eingerichtet ist, können Sie einige Beispielprompts ausführen, um die Fähigkeiten von LLaVA zu testen. Öffnen Sie ein Python-Skript und importieren Sie das LLaVA-Modell:
from LLaVA import LLaVAInitialisieren Sie das Modell und führen Sie eine Beispieltextanalyse durch:
model = LLaVA()
text_output = model.analyze_text("Wie ist die molekulare Struktur von Wasser?")
print(text_output)Für die Bildanalyse verwenden Sie:
image_output = model.analyze_image("pfad/zum/bild.jpg")
print(image_output)Diese Befehle geben die Analyse von LLaVA für den angegebenen Text und das Bild aus. Die Textanalyse liefert eine detaillierte Aufschlüsselung der molekularen Struktur von Wasser, während die Bildanalyse den Inhalt des Bildes beschreibt.
LLaVA-Med: Das spezialisierte LLaVA-Modell für biomedizinische Fachleute

LLaVA-Med, die spezialisierte Version von LLaVA, wurde für biomedizinische Anwendungen optimiert und ist eine bahnbrechende Lösung für Gesundheitswesen und medizinische Forschung. Hier ein kurzer Überblick darüber, was LLaVA-Med auszeichnet:
-
Domänenspezifisches Training: LLaVA-Med wurde auf umfangreichen biomedizinischen Datensätzen trainiert, was es ihm ermöglicht, komplexe medizinische Terminologien und Konzepte mühelos zu verstehen.
-
Anwendungen: Von diagnostischer Unterstützung bis hin zu Forschungsannotationen kann LLaVA-Med eine Revolution im Gesundheitswesen darstellen. Stellen Sie sich ein Werkzeug vor, das medizinische Bilder schnell analysieren, Patientendaten vergleichen oder komplexe genomische Forschung unterstützen kann.
-
Potenzial für Zusammenarbeit: Die Open-Source-Natur von LLaVA-Med fördert die Zusammenarbeit innerhalb der globalen biomedizinischen Gemeinschaft und führt zu kontinuierlichen Verbesserungen und gemeinsamen Durchbrüchen.
Um die transformative Kraft von LLaVA-Med wirklich zu erfassen, muss man sich mit seinen Fähigkeiten beschäftigen, den Code untersuchen und seine potenziellen Anwendungen verstehen. Wenn immer mehr Entwicklerinnen und medizinische Fachleute auf dieser Plattform zusammenarbeiten, könnte LLaVA-Med sehr gut das Vorbote einer neuen Ära in biomedizinischen KI-Anwendungen sein.
Interessiert an der medizinischen, speziell abgestimmten Version von LLaVA?
Lesen Sie mehr dazu, wie LLaVA Med hier funktioniert.
Fazit
Die Fortschritte in der KI und im maschinellen Lernen gestalten zweifellos unsere technologische Landschaft um, und das Aufkommen von LLaVA kennzeichnet eine aufregende Weiterentwicklung in diesem Bereich. Das LLaVA-Modell ist mehr als nur ein weiteres Werkzeug im KI-Werkzeugkasten. Es verkörpert die Verschmelzung von Text und Vision und eröffnet eine Vielzahl von Anwendungen, die unsere bisherigen technologischen Grenzen herausfordern. Die Open-Source-Natur treibt einen gemeinschaftlichen Ansatz voran, der es jedem erlaubt, an den technologischen Fortschritten teilzuhaben und nicht nur passive Konsumenten zu sein.
Im Vergleich dazu, während GPT-4 in der Textwelt möglicherweise einen festen Platz hat, macht die Vielseitigkeit von LLaVA bei der Behandlung von Text und Bildern es zu einer überzeugenden Wahl für Entwicklerinnen und Forscherinnen gleichermaßen. Während wir uns weiterhin in die von KI angetriebene Zukunft wagen, werden Tools wie LLaVA eine entscheidende Rolle spielen und die Lücke zwischen dem, was heute möglich ist und den Innovationen von morgen überbrücken.
Möchten Sie die neuesten Nachrichten zu LLM erfahren? Schauen Sie sich das aktuelle LLM-Ranking an!
