LLaVA-Med: Der nächste große Schritt in der biomedizinischen Bildgebung

Die Welt der medizinischen Bildgebung erlebt einen Paradigmenwechsel. Vorbei sind die Zeiten, in denen sich Fachleute im Gesundheitswesen ausschließlich auf ihren scharfen Blick und jahrelange Erfahrung verlassen mussten, um medizinische Scans zu interpretieren. Betreten Sie LLaVA-Med, eine spezialisierte Variante des renommierten LLaVA-Modells, das exklusiv für den biomedizinischen Sektor entwickelt wurde. Dieses leistungsstarke Tool ist nicht nur eine weitere technische Errungenschaft; es repräsentiert die Zukunft der Diagnose und Behandlungsplanung. Ob Röntgenbilder, MRTs oder komplexe 3D-Scans - LLaVA-Med bietet beispiellose Einblicke und schließt die Lücke zwischen herkömmlichen Praktiken und hochmoderner KI-Technologie.
Stellen Sie sich vor, Sie hätten einen Assistenten, der Ihnen eine detaillierte Analyse jedes medizinischen Bildes oder Textes an Ihren Fingerspitzen liefern kann. Das ist LLaVA-Med für Sie. Mit einer Kombination aus Genauigkeit und multimodalen Fähigkeiten wird es ein unverzichtbarer Begleiter für Fachleute im Gesundheitswesen auf der ganzen Welt sein. Machen Sie sich auf eine Reise, um herauszufinden, was dieses Tool so außergewöhnlich macht.
Möchten Sie die neuesten LLM-Nachrichten erfahren? Schauen Sie sich das neueste LLM-Ranking an!
Was ist LLaVA-Med?
LLaVA-Med ist eine einzigartige Variante des LLaVA-Modells, das speziell für den biomedizinischen Sektor optimiert wurde. Es ist darauf ausgelegt, medizinische Bilder und Texte zu interpretieren und zu analysieren, was es zu einem unverzichtbaren Werkzeug für Fachleute im Gesundheitswesen macht. Ob Sie sich Röntgenbilder, MRTs oder komplexe 3D-Scans ansehen - LLaVA-Med liefert detaillierte Einblicke, die bei Diagnose und Behandlungsplanung helfen können.
Microsoft hat das Open-Source-Modell #LLaVA optimiert und LLaVA-Med entwickelt, ein Modell für visuelle und sprachliche Informationen, das biomedizinische Bilder interpretieren kann. Stellen Sie sich vor, dieses Modell so anzupassen, dass es Studien aus Ihrer Einrichtung liest und Texte generiert, die sowohl genau als auch auf Ihre Sprache und Ihren Ton abgestimmt sind. pic.twitter.com/rnSOWITTLB
— Paulo Kuriki, MD (@kuriki) 8. Oktober 2023
Was macht LLaVA-Med einzigartig?
-
Feinabstimmung für medizinische Daten: Im Gegensatz zum vielseitigen LLaVA-Modell wurde LLaVA-Med auf einem spezialisierten Datensatz trainiert, der medizinische Fachzeitschriften, klinische Notizen und eine Vielzahl von medizinischen Bildern umfasst.
-
Hohe Genauigkeit: LLaVA-Med zeichnet sich durch beeindruckende Genauigkeitsraten bei der Interpretation medizinischer Bilder aus und übertrifft häufig andere medizinische Bildgebungstechnologien.
-
Multimodale Fähigkeiten: LLaVA-Med kann Texte und Bilder analysieren, was es ideal zur Interpretation von Patientenakten macht, die oft eine Mischung aus schriftlichen Notizen und medizinischen Bildern enthalten.
Evaluierung von LLaVA-Med: Wie gut ist es?
Gewiss, ich werde die Informationen aus der bereitgestellten Tabelle in den Text integrieren.
1. LLaVA-Meds Fähigkeiten zur Interpretation visueller biomedizinischer Daten:
Basierend auf dem umfassenden LLaVA-Modell wird die Exzellenz von LLaVA-Med besonders betont, wenn es um die Interpretation von visuellen biomedizinischen Daten geht.
-
Benchmark-Datensätze zur Evaluierung: LLaVA-Med und andere Modelle werden anhand verschiedener Datensätze bewertet, wobei spezifische Benchmarks wie VQA-RAD, SLAKE und PathVQA verwendet werden, um die Fähigkeit des Modells zur visuellen Fragebeantwortung in Radiologie, Pathologie und anderen Bereichen zu testen.
-
Ergebnisse der überwachten Feinabstimmung: Die Tabelle zeigt die Ergebnisse der überwachten Feinabstimmungsexperimente mit verschiedenen Methoden:
| Methode | VQA-RAD (Ref) | VQA-RAD (Offen) | VQA-RAD (Geschlossen) | SLAKE (Ref) | SLAKE (Offen) | SLAKE (Geschlossen) | PathVQA (Ref) | PathVQA (Offen) | PathVQA (Geschlossen) |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA | 50,00 | 65,07 | 78,18 | 63,22 | 7,74 | 63,20 | |||
| LLaVA-Med (LLaVA) | 61,52 | 84,19 | 83,08 | 85,34 | 37,95 | 91,21 | |||
| LLaVA-Med (Vicuna) | 64,39 | 81,98 | 84,71 | 83,17 | 38,87 | 91,65 | |||
| LLaVA-Med (BioMed) | 64,75 | 83,09 | 87,11 | 86,78 | 39,60 | 91,09 |
Beschreibung der Metriken:
-
Methode: Dies gibt die spezifische Version oder den spezifischen Ansatz des Modells an, der bewertet wird. Es umfasst verschiedene Iterationen und Quellen von LLaVA und LLaVA-Med.
-
VQA-RAD (Ref, Offen, Geschlossen): Metriken für die visuelle Fragebeantwortung in der Radiologie. 'Ref' bezieht sich auf die Referenzpunktzahl, 'Offen' auf die Bewertung offener Fragen und 'Geschlossen' auf die Bewertung geschlossener Fragen.
-
SLAKE (Ref, Offen, Geschlossen): Metriken für den SLAKE-Benchmark. 'Ref' steht für die Referenzpunktzahl, 'Offen' entspricht der Bewertung von offenen Fragen und 'Geschlossen' bezieht sich auf die Bewertung geschlossener Fragen. Please provide the German translation for this markdown file. If there is a frontmatter, make sure you translate language parameter to the matching "de" as well. For the code, do not translate code, only translate comments. Do not translate the content of sample prompt. Here is the file:
-
PathVQA (Ref, Open, Closed): Metriken im Zusammenhang mit Pathology Visual Question Answering. 'Ref' steht für den Referenzscore, 'Open' für den Punktestand bei offenen Fragen und 'Closed' für den Punktestand bei geschlossenen Fragen.
Referenz: Forschungsquelle (opens in a new tab)
Durch den Vergleich der Ergebnisse von LLaVA-Med, die aus verschiedenen Methoden abgeleitet wurden, ist offensichtlich, dass das Modell eine beeindruckende Leistung bei der visuellen biomedizinischen Interpretation zeigt, insbesondere im Vergleich zu Benchmarks wie VQA-RAD und SLAKE. Diese Kompetenz unterstreicht ihr Potenzial, medizinischen Fachleuten bei der Entscheidungsfindung auf der Grundlage visueller Daten zu unterstützen.
2. Kompetenz von LLaVA-Med in der Befolgung von Anweisungen:
Ausgehend vom umfangreichen LLaVA-Modell zeichnet sich die Kompetenz von LLaVA-Med durch ihren maßgeschneiderten Schwerpunkt auf biomedizinischen Feinheiten aus.
-
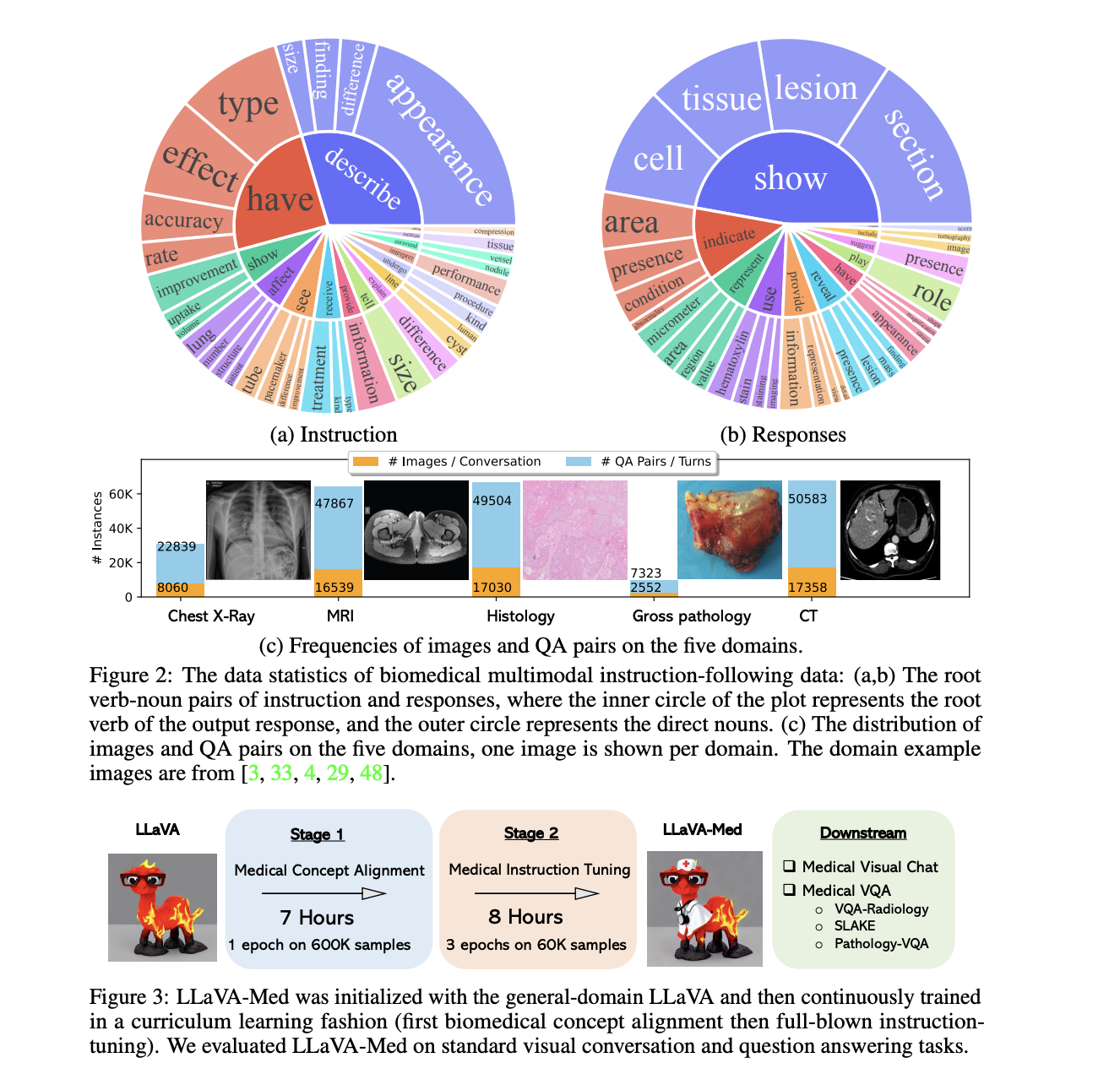
Datensatz zur Modellverbesserung: Die Verbesserung von LLaVA-Med basierte auf dem Biomedical multimodal instruction-following Datensatz. Dieser Datensatz umfasst verschiedene reale biomedizinische Kontexte und stellt sicher, dass LLaVA-Med über das Fachwissen in der Medizin verfügt, um diese präzise zu verstehen und zu erklären.
-
Einblicke in die Dual-Phase-Adaption:
- Phase 1 (Integrierung biomedizinischer Konzepte): Diese grundlegende Phase war entscheidend. Sie hatte zum Ziel, das umfassende Wissen von LLaVA mit verschiedenen biomedizinischen Konzepten zu verschmelzen. Dieser Schritt gewährleistete, dass die anschließende Verbesserung im Einklang mit den medizinischen Feinheiten war.
- Phase 2 (umfassende instruktive Abstimmung): An diesem entscheidenden Punkt wurde das Modell intensiv anhand von biomedizinischen Anweisungen geschult, um seine Fähigkeit zu stärken, medizinische Kontexte intuitiv zu verstehen, zu erfassen und darauf einzugehen.
Vergleichende Leistung von LLaVA gegenüber LLaVA-Med:
| Modelliteration | Konversation (%) | Beschreibung (%) | CXR (%) | MRI (%) | Histologie (%) | Grob (%) | CT (%) | Kumulativ (%) |
|---|---|---|---|---|---|---|---|---|
| LLaVA | 39,4 | 26,2 | 41,6 | 33,4 | 38,4 | 32,9 | 33,4 | 36,1 |
| LLaVA-Med Phase 1 | 22,6 | 25,2 | 25,8 | 19,0 | 24,8 | 24,7 | 22,2 | 23,3 |
| LLaVA-Med Phase 2 | 52,4 | 49,1 | 58,0 | 50,8 | 53,3 | 51,7 | 52,2 | 53,8 |
Beschreibung der Metriken:
-
Modelliteration: Bezeichnet die bestimmte Iteration oder Phase des zu untersuchenden Modells. Es umfasst das übergreifende LLaVA, LLaVA-Med nach der primären Phase und nach der sekundären Phase.
-
Konversation (%): Eine Kennzahl, die die Fähigkeit des Modells hervorhebt, einen kontextbezogenen Dialog aufrechtzuerhalten und relevante Antworten anzubieten.
-
Beschreibung (%): Ein Indikator für die Fähigkeit des Modells, medizinische visuelle Darstellungen gründlich zu erläutern und sicherzustellen, dass die vermittelten Details präzise sind.
-
CXR (%): Bewertet die Genauigkeit von LLaVA-Med bei der Interpretation von Röntgenbildern der Brust, einem unverzichtbaren Instrument in der klinischen Diagnostik.
-
MRI (%): Misst die Fähigkeit des Modells, Magnetresonanztomographie-Ergebnisse zu analysieren und zu erklären. MRIs sind aufgrund ihrer detaillierten Einblicke von entscheidender Bedeutung für die medizinische Diagnosestellung und therapeutische Entscheidungen.
-
Histologie (%): Eine Reflektion der Effektivität des Modells bei der Untersuchung von mikroskopischen Gewebestudien, die für die Lokalisierung zellulärer Unregelmäßigkeiten wichtig sind.
-
Grob (%): Ein Maß für die Fähigkeit von LLaVA-Med, grobe anatomische Strukturen zu erläutern, die ohne mikroskopische Hilfe sichtbar sind.
-
CT (%): Bewertet die Präzision des Modells bei der Interpretation von Computertomographie-Scans, die für ihre umfassenden, schnittbildartigen Körperdarstellungen bekannt sind.
-
Kumulativ (%): Eine konsolidierte Punktzahl, die die Leistung des Modells in verschiedenen Kategorien zusammenfasst.
Referenz: Forschungsquelle (opens in a new tab)
3. LLaVA-Med Visual Chatbot, in einfachen Worten:
LLaVA-Med ist nicht nur gut mit Worten, sondern versteht auch Bilder sehr gut.
-
Gut in vielen Dingen: LLaVA-Med weiß viel über verschiedene medizinische Bilder. Es kann Bilder von Röntgenaufnahmen bis hin zu Magnetresonanztomographien und sogar winzigen Gewebebildern betrachten.
-
Viele Daten: Was macht es so gut? Es hat viele Bilder und Texte gesehen und daraus gelernt. Es kennt sich also mit Dingen wie Röntgenaufnahmen, Körper-Scans und sogar einfachen Körperbildern aus.
-
Verwendung in der realen Welt: Stellen Sie sich Ärzte vor, die Hunderte von Röntgenaufnahmen betrachten. LLaVA-Med kann helfen, indem es diese Bilder schnell überprüft, Probleme herausfindet und die Arbeit des Arztes erleichtert.
-
Vergleich mit GPT-4: GPT-4 ist großartig mit Worten. Aber wenn es darum geht, medizinische Bilder zu verstehen und darüber zu sprechen, macht LLaVA-Med einen besseren Job. Es kann ein medizinisches Bild betrachten und darüber im Detail sprechen.
-
Es ist nicht perfekt: Wie alles hat auch LLaVA-Med seine Grenzen. Manchmal kann es verwirrt sein, wenn ein Bild zu sehr von dem abweicht, was es kennt. Aber je mehr Bilder es sieht, desto besser kann es lernen und sich verbessern.
Sie können eine Online-Version von LLaVA-Med hier (opens in a new tab) ausprobieren.
Wie man LLaVA-Med installiert: Schritt für Schritt
Die Einrichtung von LLaVA-Med erfordert einige zusätzliche Schritte im Vergleich zum allgemeinen LLaVA-Modell aufgrund seiner spezialisierten Natur. Hier ist, wie es geht:
Schritt 1: Initialisierung des LLaVA-Med-Repositorys
Klonen leicht gemacht:
Beginnen Sie mit dem Klonen des LLaVA-Med-Repositorys. Öffnen Sie Ihr Terminal und geben Sie Folgendes ein:
git clone https://github.com/microsoft/LLaVA-Med.gitMit diesem Befehl werden alle erforderlichen Dateien direkt aus dem Microsoft-Repository auf Ihren Computer heruntergeladen.
Schritt 2: Eintauchen in das LLaVA-Med-Verzeichnis
Navigation Essentials:
Nachdem Sie das Repository geklont haben, wechseln Sie als nächstes in Ihr Arbeitsverzeichnis. So geht's:
cd LLaVA-MedMit diesem Befehl positionieren Sie sich im Herzstück des LLaVA-Med-Verzeichnisses und sind bereit, mit der nächsten Phase fortzufahren.
Schritt 3: Einrichten der Grundlage - Installation von Paketen
Eine auf Abhängigkeiten aufgebaute Grundlage
Jede komplexe Software hat ihre eigenen Abhängigkeiten. LLaVA-Med bildet da keine Ausnahme. Mit folgendem Befehl installieren Sie alles, was zur reibungslosen Funktion erforderlich ist:
pip install -r requirements.txtDenken Sie daran, hier geht es nicht nur um das Installieren von Paketen. Es geht darum, eine förderliche Umgebung zu schaffen, um die Fähigkeiten von LLaVA-Med zu präsentieren.
Schritt 4: Interaktion mit LLaVA-Med
Ausführung von Beispiel-Prompts, um die Magie zu erleben:
Bereit für Aktion? Beginnen Sie mit der Integration des LLaVA-Med-Modells in Ihr Python-Skript:
from LLaVAMed import LLaVAMedStarten Sie das Modell:
model = LLaVAMed()Tauchen Sie ein in eine exemplarische medizinische Textanalyse:
text_output = model.analyze_medical_text("Beschreiben Sie die Symptome von Lungenentzündung.")
print(text_output)Und für diejenigen, die sich für die medizinische Bildanalyse interessieren:
image_output = model.analyze_medical_image("Pfad/zu/röntgenbild.jpg")
print(image_output)Durch die Ausführung dieser Befehle wird die analytische Fähigkeit von LLaVA-Med offenbart. Zum Beispiel kann die medizinische Textanalyse Symptome, verursachende Faktoren und potenzielle Behandlungen für Lungenentzündung beleuchten. Die Bildanalyse kann hingegen Abweichungen oder Unregelmäßigkeiten im Röntgenbild aufzeigen. Sie können den LLaVA-Med-GitHub-Quellcode (opens in a new tab) einsehen.
Fazit
Obwohl KI in der medizinischen Bildgebung ein enormes Potenzial hinsichtlich Genauigkeit und Effizienz zeigt, ist sie noch nicht in einem Stadium, in dem sie menschliche Ärzte vollständig ersetzen kann. Die Technologie dient als mächtiges Werkzeug zur Unterstützung der Diagnose, erfordert jedoch die Aufsicht und Erfahrung eines medizinischen Fachmanns, um eine zuverlässige und umfassende Versorgung zu gewährleisten. Daher sollte der Fokus auf der Schaffung einer kooperativen Umgebung liegen, in der KI und menschliche Expertise gemeinsam die bestmögliche Gesundheitsversorgung bieten können.
Möchten Sie die neuesten LLM-Nachrichten erfahren? Schauen Sie sich die aktuelle LLM-Rangliste an!
