LlamaIndex: die LangChain-Alternative, die LLMs erweitert

Einführung: Was ist LlamaIndex?
LlamaIndex ist ein leistungsstarkes Indexierungstool, das speziell entwickelt wurde, um die Fähigkeiten von Large Language Models (LLMs) zu erweitern. Es ist nicht nur ein Abfrageoptimierer; es ist ein umfassendes Framework, das fortschrittliche Funktionen wie Antwortsynthese, Komponierbarkeit und effiziente Datenspeicherung bietet. Wenn Sie komplexe Abfragen bearbeiten und hochwertige, kontextuell relevante Antworten benötigen, ist LlamaIndex die Lösung Ihrer Wahl.
In diesem Artikel werden wir uns technisch intensiv mit LlamaIndex befassen und seine Kernkomponenten, fortgeschrittenen Funktionen und die effektive Implementierung in Ihren Projekten erkunden. Wir werden ihn auch mit ähnlichen Tools wie LangChain vergleichen, um Ihnen ein umfassendes Verständnis seiner Fähigkeiten zu geben.
Möchten Sie die neuesten LLM-Nachrichten erfahren? Schauen Sie sich das neueste LLM-Ranking an!
Was ist eigentlich LlamaIndex?
LlamaIndex ist ein spezialisiertes Tool, das entwickelt wurde, um die Funktionalitäten von Large Language Models (LLMs) zu erweitern. Es dient als umfassende Lösung für bestimmte LLM-Interaktionen und zeichnet sich besonders in Szenarien aus, die präzise Abfragen und hochwertige Antworten erfordern.
Abfragen: Optimiert für schnelle Datenabrufe, ideal für anwendungen, bei denen Geschwindigkeit wichtig ist. Antwortsynthese: Optimiert für prägnante und kontextuell relevante Antworten. Komponierbarkeit: Ermöglicht den Aufbau komplexer Abfragen und Workflows mit modularen und wiederverwendbaren Komponenten.
Nun gehen wir ins Detail zu LlamaIndex, sollen wir?
Was sind Indexe in LlamaIndex?
Indexe sind der Kern von LlamaIndex und dienen als Datenstrukturen, die die abzufragenden Informationen enthalten. LlamaIndex bietet verschiedene Arten von Indexen, die jeweils für bestimmte Aufgaben optimiert sind.

Arten von Indexen in LlamaIndex
- Vektorstore-Index: Verwendet k-NN-Algorithmen und ist für hochdimensionale Daten optimiert.
- Schlüsselwortbasierter Index: Verwendet TF-IDF für textbasierte Abfragen.
- Hybridindex: Eine Kombination aus Vektor- und Schlüsselwortbasierten Indexen, die einen ausgewogenen Ansatz bietet.
Vektorstore-Index in LlamaIndex
Der Vektorstore-Index ist ideal für alles, was mit hochdimensionalen Daten zu tun hat. Er ist besonders nützlich für maschinelles Lernen, bei dem komplexe Datenpunkte behandelt werden.
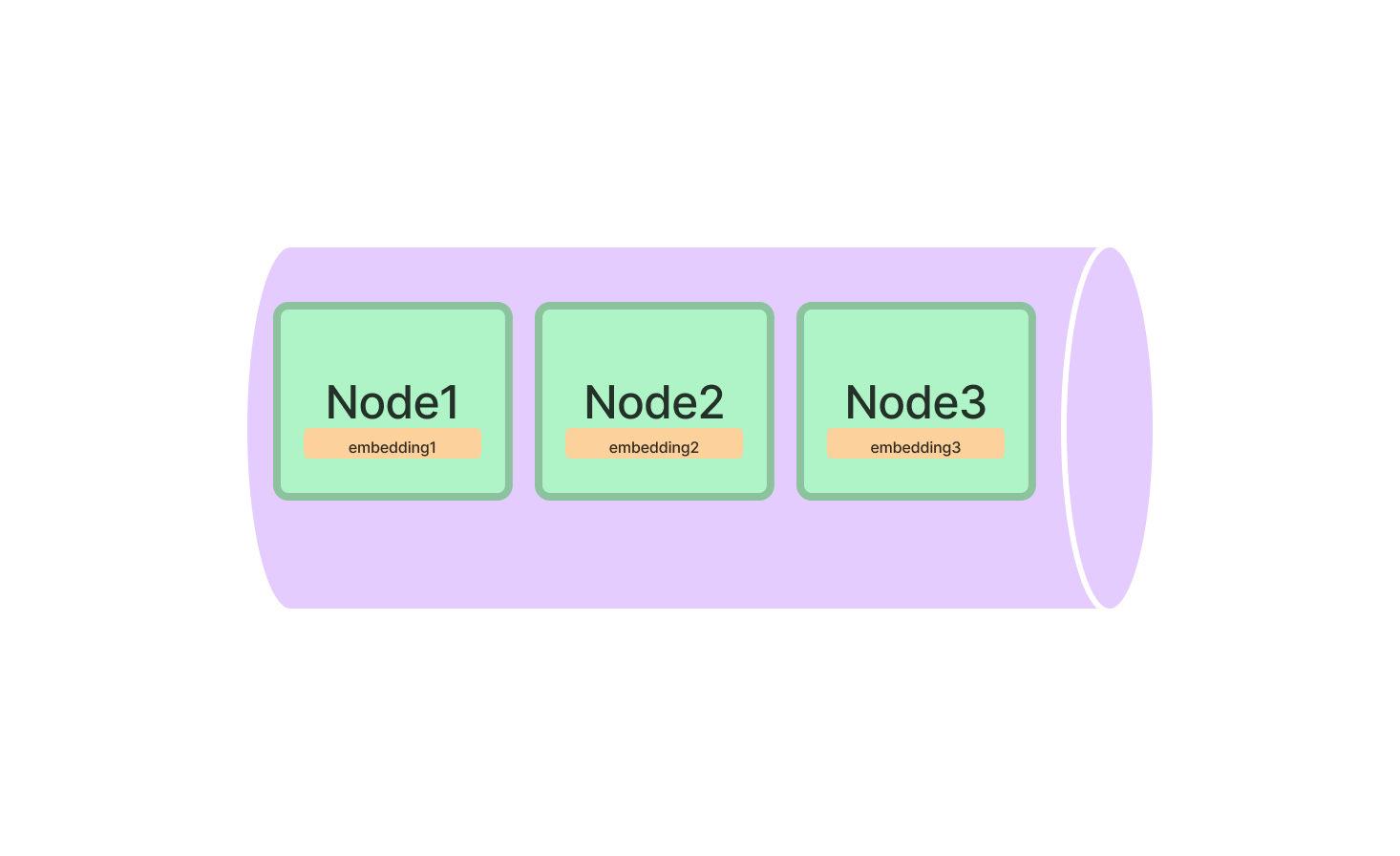
Um loszulegen, importieren Sie die Klasse VectorStoreIndex aus dem LlamaIndex-Paket. Initialisieren Sie sie, indem Sie die Dimensionen Ihrer Vektoren angeben.
from llamaindex import VectorStoreIndex
vector_index = VectorStoreIndex(dimensions=300)Damit richten Sie einen Vektorstore-Index mit 300 Dimensionen ein, der bereit ist, Ihre hochdimensionalen Daten zu verarbeiten. Sie können jetzt Vektoren zum Index hinzufügen und Abfragen ausführen, um die ähnlichsten Vektoren zu finden.
# Einen Vektor hinzufügen
vector_index.add_vector(vector_id="vector_1", vector_data=[0.1, 0.2, 0.3, ...])
# Eine Abfrage ausführen
query_result = vector_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)Schlüsselwortbasierter Index in LlamaIndex
Wenn Sie eher textbasierte Abfragen bevorzugen, ist der schlüsselwortbasierte Index Ihr Verbündeter. Er verwendet den TF-IDF-Algorithmus, um textuelle Daten zu durchsuchen, was ihn ideal für natürliche Sprachabfragen macht.
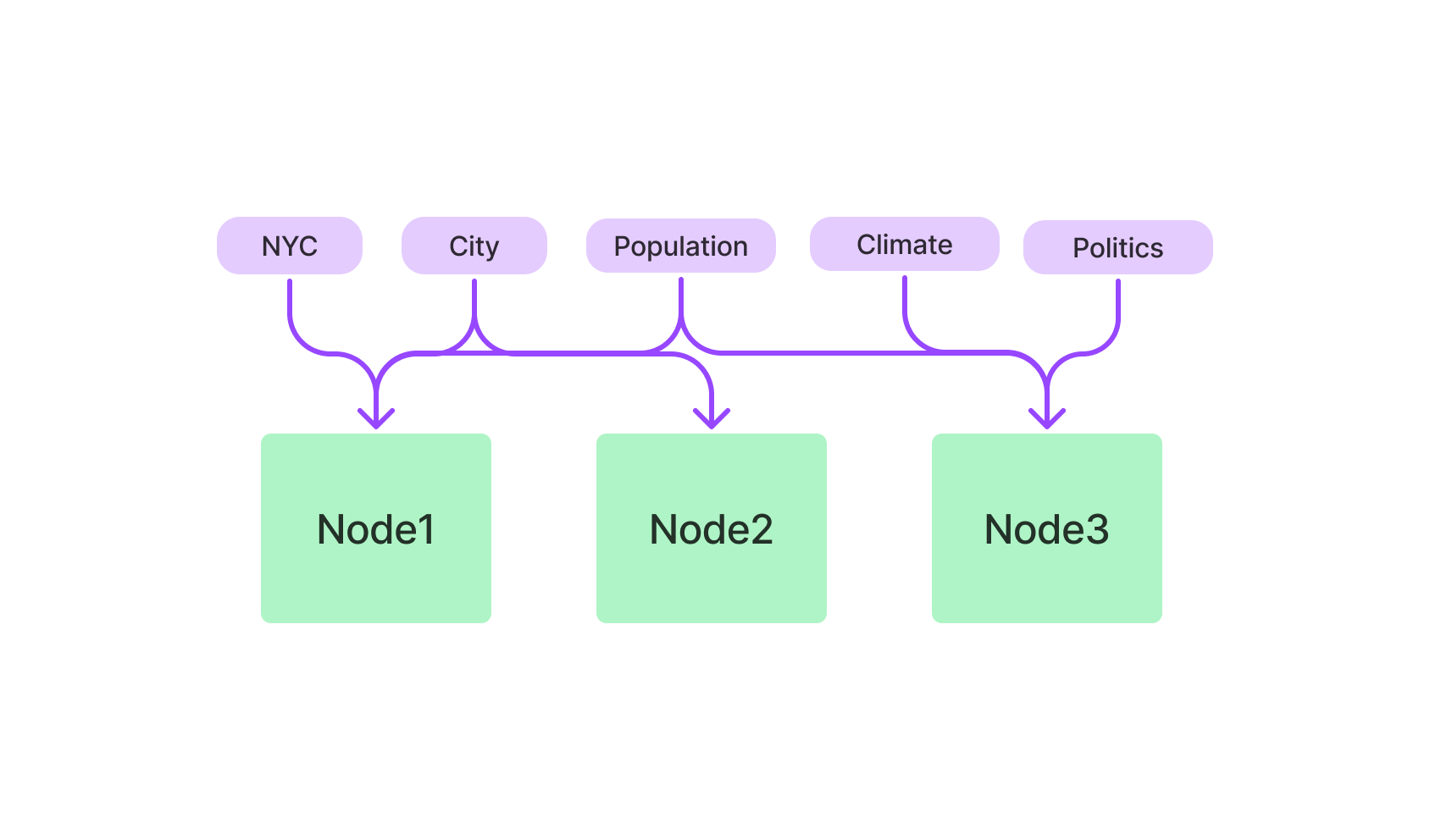
Beginnen Sie damit, die Klasse KeywordBasedIndex aus dem LlamaIndex-Paket zu importieren. Initialisieren Sie sie.
from llamaindex import KeywordBasedIndex
text_index = KeywordBasedIndex()Jetzt können Sie Textdaten zu diesem Index hinzufügen und textbasierte Abfragen ausführen.
# Textdaten hinzufügen
text_index.add_text(text_id="document_1", text_data="Dies ist ein Beispiel-Dokument.")
# Eine Abfrage ausführen
query_result = text_index.query(text="Beispiel", top_k=3)Schnellstart mit LlamaIndex: Schritt-für-Schritt-Anleitung
Die Installation und Initialisierung von LlamaIndex ist nur der Anfang. Um seine Kraft wirklich nutzen zu können, müssen Sie wissen, wie Sie es effektiv verwenden können.
LlamaIndex installieren
Zuerst müssen Sie es auf Ihren Computer bekommen. Öffnen Sie Ihr Terminal und führen Sie aus:
pip install llamaindexOder wenn Sie conda verwenden:
conda install -c conda-forge llamaindexLlamaIndex initialisieren
Nach Abschluss der Installation müssen Sie LlamaIndex in Ihrer Python-Umgebung initialisieren. Hier setzen Sie die Bühne für all die Magie, die folgt.
from llamaindex import LlamaIndex
index = LlamaIndex(index_type="vector_store", dimensions=300)Hier gibt index_type an, welche Art von Index Sie einrichten, und dimensions wird verwendet, um die Größe des Vektorstore-Index anzugeben.
Wie man mit dem Vektorstore-Index von LlamaIndex eine Abfrage durchführt
Nachdem Sie LlamaIndex erfolgreich eingerichtet haben, können Sie seine leistungsstarken Abfragetechniken erkunden. Der Vektorstore-Index wurde entwickelt, um komplexe, hochdimensionale Daten zu verwalten und eignet sich daher hervorragend für maschinelles Lernen, Datenanalyse und andere Berechnungsaufgaben.
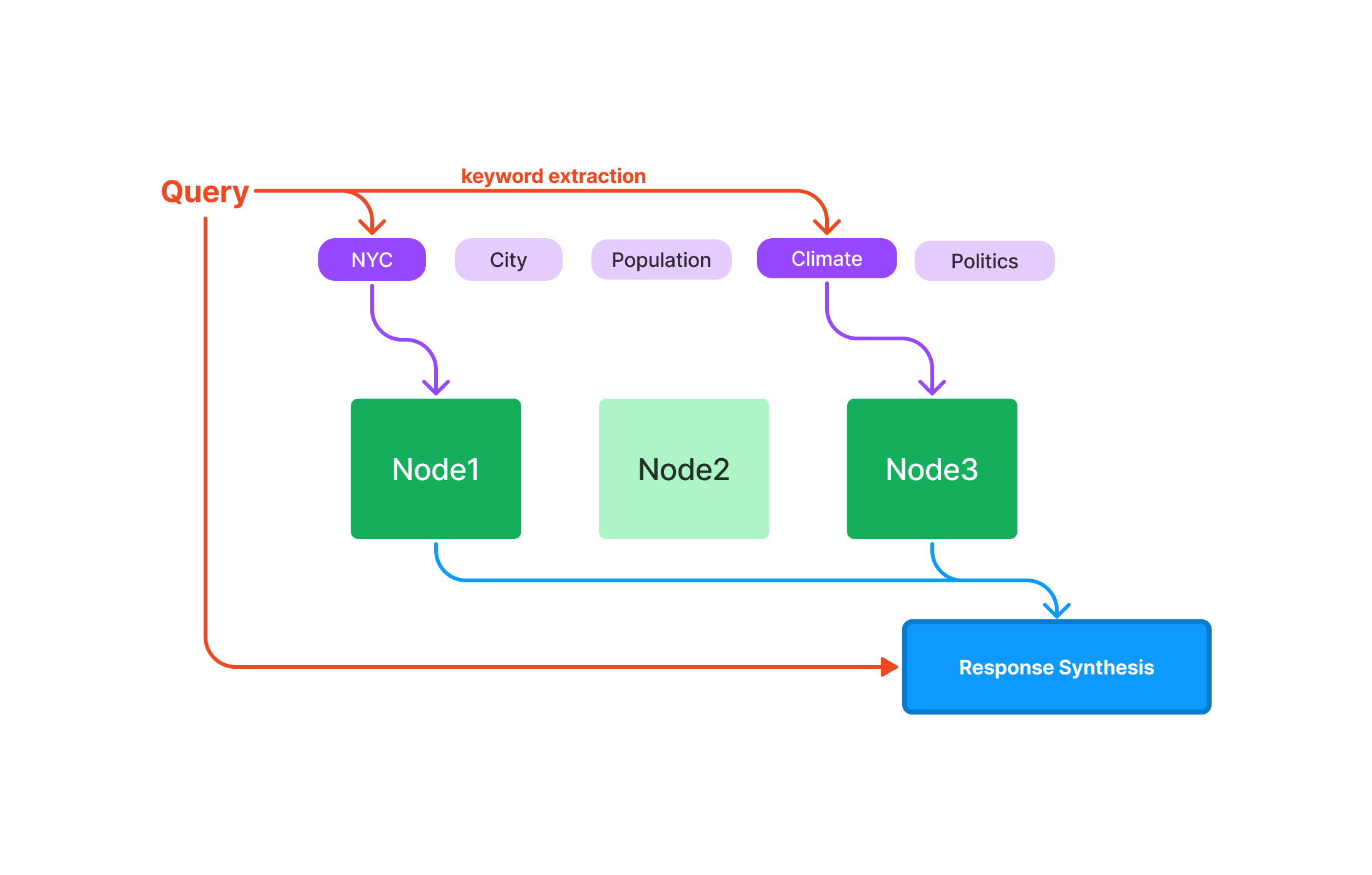
Führen Sie Ihre erste Abfrage in LlamaIndex durch
Bevor Sie sich mit dem Code befassen, ist es wichtig, die grundlegenden Elemente einer Abfrage in LlamaIndex zu verstehen:
-
Abfragevektor: Dies ist der Vektor, für den Sie Ähnlichkeiten in Ihrem Datensatz finden möchten. Er sollte den gleichen Dimensionalitätsbereich wie die von Ihnen indizierten Vektoren haben.
-
top_k-Parameter: Dieser Parameter gibt die Anzahl der nächstgelegenen Vektoren zu Ihrem Abfragevektor an, die Sie abrufen möchten. Das "k" intop_ksteht für die Anzahl der interessierenden nächsten Nachbarn.
Hier finden Sie eine Aufschlüsselung, wie Sie Ihre erste Abfrage erstellen können:
-
Initialisieren Sie Ihren Index: Stellen Sie sicher, dass Ihr Index geladen ist und für Abfragen bereit ist.
-
Geben Sie den Abfragevektor an: Erstellen Sie eine Liste oder ein Array, das die Elemente Ihres Abfragevektors enthält.
-
Setzen Sie den
top_k-Parameter: Entscheiden Sie, wie viele der nächsten Vektoren Sie abrufen möchten. -
Führen Sie die Abfrage aus: Verwenden Sie die Methode
query, um die Suche durchzuführen.
Hier ist ein Beispielcode in Python, der diese Schritte veranschaulicht:
# Initialisieren Sie Ihren Index (vorausgesetzt er heißt 'index')
# ...
# Definieren Sie den Abfragevektor
query_vector = [0.2, 0.4, 0.1, ...]
# Setzen Sie die Anzahl der nächsten Vektoren, die abgerufen werden sollen
top_k = 5
# Führen Sie die Abfrage aus
query_result = index.query(vector=query_vector, top_k=top_k)Feinabstimmung Ihrer Abfragen in LlamaIndex
Warum Feinabstimmung wichtig ist?
Durch die Feinabstimmung Ihrer Abfragen können Sie den Suchprozess an die spezifischen Anforderungen Ihres Projekts anpassen. Ob Sie es mit Texten, Bildern oder anderen Arten von Daten zu tun haben, die Feinabstimmung kann die Genauigkeit und Effizienz Ihrer Abfragen erheblich verbessern.
Wichtige Parameter zur Feinabstimmung:
-
Abstandsmetrik: LlamaIndex bietet Ihnen die Möglichkeit, zwischen verschiedenen Abstandsmetriken wie 'Euklidisch' und 'Kosinus' zu wählen.
-
Euklidischer Abstand: Dies ist der "gewöhnliche" direkte Abstand zwischen zwei Punkten im euklidischen Raum. Verwenden Sie diese Metrik, wenn die Größe der Vektoren wichtig ist.
-
Kosinus-Ähnlichkeit: Diese Metrik misst den Kosinus des Winkels zwischen zwei Vektoren. Verwenden Sie diese Metrik, wenn Sie mehr am Richtungsvektor interessiert sind als an seiner Größe.
-
-
Batch-Größe: Wenn Sie es mit einem großen Datensatz zu tun haben oder mehrere Abfragen durchführen müssen, kann das Festlegen einer Batch-Größe den Prozess beschleunigen, indem mehrere Vektoren gleichzeitig abgefragt werden.
Schritt-für-Schritt-Anleitung zur Feinabstimmung:
So gehen Sie vor, um Ihre Abfrage fein abzustimmen:
-
Wählen Sie die Abstandsmetrik: Entscheiden Sie sich basierend auf Ihren spezifischen Anforderungen für 'Euklidisch' oder 'Kosinus'.
-
Setzen Sie die Batch-Größe: Legen Sie die Anzahl der Vektoren fest, die Sie in einem einzelnen Stapel verarbeiten möchten.
-
Führen Sie die fein abgestimmte Abfrage aus: Verwenden Sie erneut die Methode
query, aber diesmal mit den zusätzlichen Parametern.
Hier ist ein Python-Code-Snippet, um dies zu veranschaulichen:
# Definieren Sie den Abfragevektor
query_vector = [0.2, 0.4, 0.1, ...]
# Setzen Sie die Anzahl der nächsten Vektoren, die abgerufen werden sollen
top_k = 5
# Wählen Sie die Abstandsmetrik
distance_metric = 'euclidean'
# Setzen Sie die Batch-Größe für mehrere Abfragen
batch_size = 100
# Führen Sie die fein abgestimmte Abfrage aus
query_result = index.query(vector=query_vector, top_k=top_k, metric=distance_metric, batch_size=batch_size)Durch die Beherrschung dieser Feinabstimmungstechniken können Sie Ihre LlamaIndex-Abfragen gezielter und effizienter gestalten und so den größtmöglichen Nutzen aus Ihren hochdimensionalen Daten ziehen.
Was können Sie mit LlamaIndex erstellen?
Sie haben die Grundlagen verstanden, aber was genau können Sie eigentlich mit LlamaIndex erstellen? Die Möglichkeiten sind vielfältig, insbesondere wenn Sie die Kompatibilität mit Large Language Models (LLMs) berücksichtigen.
LlamaIndex für erweiterte Suchmaschinen
Eine der überzeugendsten Anwendungen von LlamaIndex liegt im Bereich erweiterter Suchmaschinen. Stellen Sie sich eine Suchmaschine vor, die nicht nur relevante Dokumente abruft, sondern auch den Kontext Ihrer Anfrage versteht. Mit LlamaIndex können Sie genau das aufbauen.
Hier ist ein kurzes Beispiel, um zu zeigen, wie Sie eine grundlegende Suchmaschine mit dem Keyword-based Index von LlamaIndex einrichten können.
# Initialisieren Sie den Keyword-based Index
from llamaindex import KeywordBasedIndex
search_index = KeywordBasedIndex()
# Fügen Sie einige Dokumente hinzu
search_index.add_text("doc1", "Lamas sind fantastisch.")
search_index.add_text("doc2", "Ich liebe das Programmieren.")
# Führen Sie eine Abfrage aus
results = search_index.query("Lamas", top_k=2)LlamaIndex für Empfehlungssysteme
Eine weitere faszinierende Anwendung besteht in der Erstellung von Empfehlungssystemen. Ob es um ähnliche Produkte, Artikel oder sogar Lieder geht, LlamaIndex's Vector Store Index kann eine wichtige Rolle spielen.
So könnten Sie ein grundlegendes Empfehlungssystem einrichten:
# Initialisieren Sie den Vector Store Index
from llamaindex import VectorStoreIndex
rec_index = VectorStoreIndex(dimensions=50)
# Fügen Sie einige Produktvektoren hinzu
rec_index.add_vector("product1", [0.1, 0.2, 0.3, ...])
rec_index.add_vector("product2", [0.4, 0.5, 0.6, ...])
# Führen Sie eine Abfrage aus, um ähnliche Produkte zu finden
similar_products = rec_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)LlamaIndex vs. LangChain
Bei der Entwicklung von Anwendungen, die von Large Language Models (LLMs) unterstützt werden, kann die Wahl des Frameworks einen erheblichen Einfluss auf den Erfolg des Projekts haben. Zwei Frameworks, die in diesem Bereich Aufmerksamkeit erregt haben, sind LlamaIndex und LangChain. Beide haben ihre einzigartigen Features und Vorteile, erfüllen jedoch unterschiedliche Anforderungen und sind für spezifische Aufgaben optimiert. In diesem Abschnitt gehen wir auf die technischen Details ein und geben Beispielcode, um Ihnen die wichtigsten Unterschiede zwischen diesen beiden Frameworks zu veranschaulichen, insbesondere im Zusammenhang mit der Rückgewinnungs-augmentierten Erzeugung (RAG) für die Entwicklung von Chatbots.
Kernfunktionen und technische Fähigkeiten
LangChain
-
Allzweck-Framework: LangChain wurde als vielseitiges Werkzeug für eine Vielzahl von Anwendungen entwickelt. Es erlaubt nicht nur das Laden, Verarbeiten und Indizieren von Daten, sondern bietet auch Funktionen zur Interaktion mit LLMs.
Beispielcode:
const res = await llm.call("Erzähl mir einen Witz"); -
Flexibilität: Eine der herausragenden Funktionen von LangChain ist ihre Flexibilität. Sie ermöglicht es Benutzern, das Verhalten ihrer Anwendungen umfassend anzupassen.
-
APIs auf hoher Ebene: LangChain abstrahiert die meisten Komplexitäten, die mit der Arbeit mit LLMs verbunden sind, und bietet APIs auf hoher Ebene, die einfach und benutzerfreundlich sind.
Beispielcode:
const chain = new SqlDatabaseChain({ llm: new OpenAI({ temperature: 0 }), database: db, sqlOutputKey: "sql", }); const res = await chain.call({ query: "Wie viele Tracks gibt es?" }); -
Fertige Chains: LangChain enthält vorgefertigte Chains wie
SqlDatabaseChain, die angepasst oder als Basis zum Erstellen neuer Anwendungen verwendet werden können.
LlamaIndex
-
Spezialisiert auf Suche und Abruf: LlamaIndex ist speziell für den Aufbau von Such- und Abrufanwendungen konzipiert. Es bietet eine einfache Schnittstelle zum Abfragen von LLMs und zum Abrufen relevanter Dokumente.
Beispielcode:
query_engine = index.as_query_engine() response = query_engine.query("Stackoverflow ist großartig.") -
Effizienz: LlamaIndex ist für hohe Leistung optimiert und daher eine bessere Wahl für Anwendungen, die große Datenmengen schnell verarbeiten müssen.
-
Datenverbindungen: LlamaIndex kann Daten aus verschiedenen Quellen wie APIs, PDFs, SQL-Datenbanken und mehr importieren, was eine nahtlose Integration in LLM-Anwendungen ermöglicht.
-
Optimiertes Indizieren: Eine der Hauptfunktionen von LlamaIndex besteht darin, die importierten Daten in Zwischenrepräsentationen zu strukturieren, die für schnelles und effizientes Abfragen optimiert sind.
Wann welches Framework verwenden?
-
Allgemeine Anwendungen: Wenn Sie einen Chatbot entwickeln, der flexibel und vielseitig sein muss, ist LangChain die ideale Wahl. Ihre allgemeine Natur und APIs auf hoher Ebene machen sie für eine Vielzahl von Anwendungen geeignet.
-
Schwerpunkt auf Suche und Abruf: Wenn die primäre Funktion Ihres Chatbots darin besteht, Informationen zu suchen und abzurufen, ist LlamaIndex die bessere Option. Ihre spezialisierten Indizierung und Abrufmöglichkeiten machen sie für solche Aufgaben äußerst effizient.
-
Beides kombinieren: In einigen Szenarien kann es vorteilhaft sein, beide Frameworks zu verwenden. LangChain kann allgemeine Funktionen und Interaktionen mit LLMs verwalten, während LlamaIndex spezialisierte Such- und Abrufaufgaben übernehmen kann. Diese Kombination kann einen ausgewogenen Ansatz bieten, indem sie die Flexibilität von LangChain und die Effizienz von LlamaIndex nutzt.
Beispielcode für kombinierte Verwendung:
# LangChain für allgemeine Funktionen res = llm.call("Erzähl mir einen Witz") # LlamaIndex für spezialisierte Suche query_engine = index.as_query_engine() response = query_engine.query("Erzähl mir etwas über den Klimawandel.")
Also, welches sollte ich wählen? LangChain oder LlamaIndex?
Die Entscheidung zwischen LangChain und LlamaIndex oder die Entscheidung, beide zu verwenden, sollte durch die spezifischen Anforderungen und Ziele Ihres Projekts geleitet werden. LangChain bietet ein breiteres Spektrum an Funktionen und eignet sich ideal für allgemeine Anwendungen. Im Gegensatz dazu ist LlamaIndex auf effiziente Suche und Abrufspezialisierung spezialisiert und eignet sich daher für datenintensive Aufgaben. Durch das Verständnis der technischen Feinheiten und Fähigkeiten jedes Frameworks können Sie eine fundierte Entscheidung treffen, die am besten zu Ihren Bedürfnissen bei der Entwicklung von Chatbots passt.
Zusammenfassung
Jetzt sollten Sie ein solides Verständnis davon haben, worum es bei LlamaIndex geht. Von spezialisierten Indizes über eine breite Palette von Anwendungen bis hin zu seinen Vorteilen gegenüber anderen Tools wie LangChain erweist sich LlamaIndex als unverzichtbares Werkzeug für alle, die mit Large Language Models arbeiten. Egal, ob Sie eine Suchmaschine, ein Empfehlungssystem oder eine Anwendung entwickeln, die effiziente Abfragen und Datenabruf erfordert, LlamaIndex ist die richtige Wahl.
Häufig gestellte Fragen zu LlamaIndex
Lassen Sie uns einige der häufigsten Fragen klären, die Menschen zu LlamaIndex haben.
Wofür wird LlamaIndex verwendet?
LlamaIndex wird hauptsächlich als Zwischenschicht zwischen Benutzern und Large Language Models verwendet. Es zeichnet sich durch eine effiziente Ausführung von Abfragen, Synthese von Antworten und Integration von Daten aus und eignet sich daher für eine Vielzahl von Anwendungen wie Suchmaschinen und Empfehlungssysteme.
Ist LlamaIndex kostenlos?
Ja, LlamaIndex ist ein Open-Source-Tool und daher kostenlos zu verwenden. Sie können den Quellcode auf GitHub finden und zu seiner Entwicklung beitragen.
Was ist GPT Index und LlamaIndex?
GPT Index ist für textbasierte Abfragen konzipiert und wird in der Regel mit GPT (Generative Pre-trained Transformer) Modellen verwendet. LlamaIndex ist hingegen vielseitiger und kann sowohl textbasierte als auch vektorbasierte Abfragen verarbeiten, was es mit einer breiteren Palette von Large Language Models kompatibel macht.
Wie ist die Architektur von LlamaIndex?
LlamaIndex basiert auf einer modularen Architektur, die verschiedene Arten von Indizes wie den Vector Store Index und den Keyword-basierten Index umfasst. Es ist hauptsächlich in Python geschrieben und unterstützt mehrere Algorithmen wie k-NN, TF-IDF und BERT-Embeddings.
Möchten Sie die neuesten LLM-Nachrichten erfahren? Schauen Sie auf der neuesten LLM-Bestenliste vorbei!
