Llemma: Die mathematische LLM, die besser ist als GPT-4

In der ständig weiterentwickelnden Welt der künstlichen Intelligenz sind Sprachmodelle zum Eckpfeiler zahlreicher Anwendungen geworden, von Chatbots bis zur Content-Erstellung. Bei spezialisierten Aufgaben wie Mathematik sind jedoch nicht alle Sprachmodelle gleich. Hier kommt Llemma ins Spiel, ein bahnbrechendes Modell, das komplexe mathematische Probleme mühelos lösen kann.
Während Modelle wie GPT-4 enorme Fortschritte im Bereich der natürlichen Sprachverarbeitung gemacht haben, verlieren sie im Bereich der Mathematik den Anschluss. Dieser Artikel soll die einzigartigen Fähigkeiten von Llemma beleuchten und untersuchen, warum selbst Giganten wie GPT-4 beim Rechnen ins Straucheln geraten.
Was ist Llemma?
Also, was genau ist Llemma? Llemma ist ein offenes Sprachmodell, das speziell auf Mathematik spezialisiert ist. Im Gegensatz zu Modellen mit allgemeinem Zweck verfügt Llemma über Rechentools, die es ihm ermöglichen, komplexe mathematische Probleme zu lösen. Konkret nutzt es Python-Interpreter und formale Beweisführer, um Berechnungen durchzuführen und Theoreme zu beweisen.
-
Python-Interpreter: Llemma kann Python-Code ausführen, um komplexe Berechnungen durchzuführen. Dies ist ein bedeutender Vorteil gegenüber Modellen wie GPT-4, die keine Möglichkeit haben, mit externen Rechentools zu interagieren.
-
Formale Beweisführer: Diese Tools ermöglichen es Llemma, mathematische Theoreme automatisch zu beweisen. Dies ist besonders nützlich in der akademischen Forschung und mathematischen Modellbildung.

Die Integration dieser Rechentools unterscheidet Llemma von seinen Konkurrenten. Es versteht nicht nur mathematische Sprache, sondern führt auch Berechnungen durch und beweist Theoreme, um eine umfassende Lösung für mathematische Aufgaben anzubieten.
Warum GPT-4 bei Mathematik versagt? Tokenisierung.
Die Grenzen von GPT-4 bei mathematischen Aufgaben sind sowohl unter Experten als auch unter Enthusiasten ein Thema der Diskussion. Obwohl es im Bereich der natürlichen Sprachverarbeitung eine enorme Leistung erbringt, ist seine Leistung bei mathematischen Berechnungen weniger beeindruckend.
Tokenisierung ist ein entscheidender Prozess in jedem Sprachmodell, der jedoch bei GPT-4 insbesondere bei Zahlen problematisch ist. Der Tokenisierungsprozess des Modells ordnet Zahlen keine eindeutigen Darstellungen zu, was zu Mehrdeutigkeiten führt.
-
Mehrdeutige Darstellungen: Beispielsweise kann die Zahl "143" als ["143"] oder ["14", "3"] oder in einer beliebigen anderen Kombination tokenisiert werden. Diese fehlende standardisierte Darstellung erschwert dem Modell die präzise Durchführung von Berechnungen.
-
Verschwendete Tokens: Eine mögliche Lösung wäre die Tokenisierung jeder Ziffer einzeln, aber dieser Ansatz ist ineffizient, da er wertvolle Ressourcen in Sprachmodellen verschwendet.
Verwendete Trainingsdaten für Llemma
Daten sind der Lebenssaft jedes maschinellen Lernmodells, und das gilt auch für Llemma. Eine der bemerkenswertesten Eigenschaften von Llemma ist der Einsatz eines spezialisierten Datensatzes namens AlgebraicStack. Dieser Datensatz umfasst erstaunliche 11 Milliarden Tokens an Code, der speziell mit Mathematik zusammenhängt.
-
Token-Vielfalt: Der Datensatz enthält eine Vielzahl mathematischer Konzepte, von Algebra bis hin zur Analysis, und bietet so einen reichhaltigen Trainingshintergrund für das Modell.
-
Datenqualität: Die Tokens in AlgebraicStack sind qualitativ hochwertig und sorgfältig geprüft, sodass das Modell auf zuverlässigen Daten trainiert wird.
Die Verwendung eines solch spezialisierten Datensatzes ermöglicht es Llemma, ein Maß an Fachwissen in Mathematik zu erreichen, das in der Branche beispiellos ist. Es geht nicht nur um die Menge der Daten, sondern auch um deren Qualität und Spezifität, die Llemma zu einem mathematischen Wunderkind machen.
Wie funktioniert Llemma?
xVal: Behebung des Tokenisierungsproblems von GPT-4
Eine faszinierende Lösung für das Tokenisierungsproblem von GPT-4 ist das Konzept von xVal. Dieser Ansatz schlägt vor, ein allgemeines [NUM]-Token zu verwenden, das dann mit dem tatsächlichen Wert der Zahl skaliert wird. Beispielsweise würde die Zahl "143" als [NUM] tokenisiert und mit 143 skaliert werden. Diese Methode hat vielversprechende Ergebnisse bei Sequenzvorhersageproblemen gezeigt, die hauptsächlich numerisch sind. Hier sind einige wichtige Punkte:
-
Leistungssteigerung: Die xVal-Methode hat eine signifikante Verbesserung der Leistung gegenüber herkömmlichen Tokenisierungstechniken gezeigt. Sie erzielt eine 70-fache Verbesserung gegenüber Grundlinien und eine 2-fache Verbesserung gegenüber starken Grundlinien bei Sequenzvorhersageaufgaben.
-
Vielseitigkeit: Ein spannender Aspekt von xVal ist seine potenzielle Anwendbarkeit über Sprachmodelle hinaus. Es könnte eine Revolution für Deep-Learning-Netzwerke bei Regressionsproblemen sein und einen neuen Ansatz zur Handhabung numerischer Daten bieten.
Während xVal einen Hoffnungsschimmer bietet, um die mathematischen Fähigkeiten von GPT-4 zu verbessern, befindet es sich immer noch im experimentellen Stadium. Darüber hinaus würde es, selbst wenn es erfolgreich implementiert wird, nur als vorübergehende Lösung für ein grundlegenderes Problem dienen.
Submodule und Experimente in Llemma
Llemma ist kein eigenständiges Modell, sondern Teil eines größeren Ökosystems, das darauf ausgerichtet ist, die Grenzen dessen, was Sprachmodelle in der Mathematik erreichen können, zu erweitern. Das Projekt umfasst verschiedene Submodule, die sich mit Überschneidungen, Feinabstimmungen und Theorembeweisexperimenten befassen.
-
Überschneidungs-Submodul: Hier geht es darum, wie gut Llemma sein Training verallgemeinern kann, um neue, unbekannte Probleme zu lösen.
-
Feinabstimmungs-Submodul: Dies beinhaltet das Anpassen der Modellparameter, um seine Leistung in bestimmten mathematischen Aufgaben zu optimieren.
-
Theorem Proving Experiments: Diese sind darauf ausgelegt, die Fähigkeit von Llemma zu testen, komplexe mathematische Theoreme automatisch zu beweisen.
Jedes dieser Teilmodule trägt dazu bei, dass Llemma ein vielseitiges und hochleistungsfähiges mathematisches Modell ist. Sie dienen als Testumgebungen für neue Funktionen und Optimierungen und stellen sicher, dass Llemma weiterhin an vorderster Front der mathematischen Sprachmodellierung bleibt.
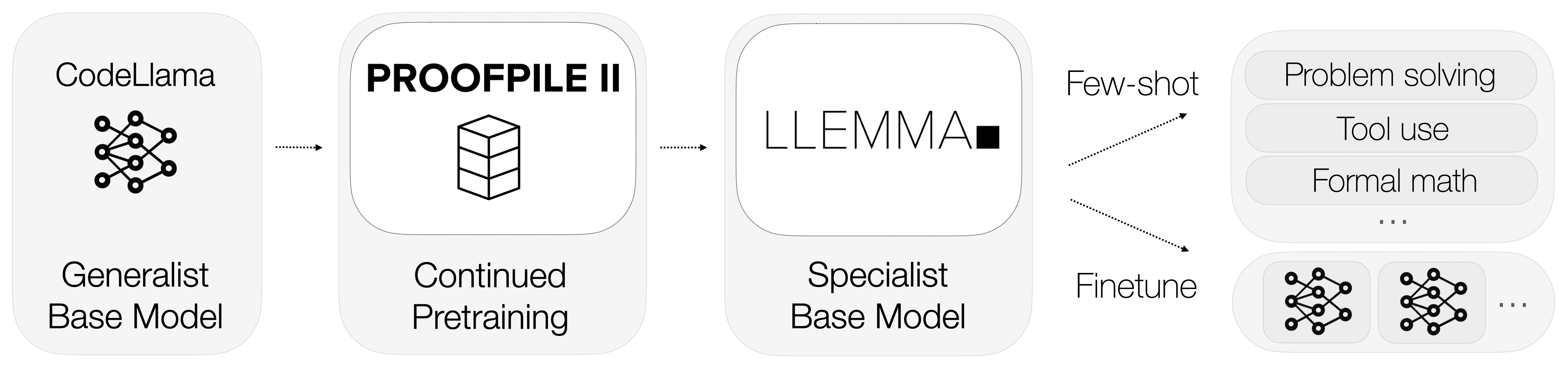
Inzwischen sollte klar sein, dass Llemma nicht nur ein weiteres Sprachmodell ist. Es ist ein spezialisiertes Werkzeug, das sich im Bereich der Mathematik hervorragend bewährt. Die Integration von Berechnungswerkzeugen, spezialisierten Trainingsdaten und laufenden Experimenten macht es zu einer beeindruckenden Leistung. Im nächsten Abschnitt werden wir darauf eingehen, warum selbst fortschrittliche Modelle wie GPT-4 Schwierigkeiten mit mathematischen Aufgaben haben und wie Llemma sie hinter sich lässt.
Llemma vs. GPT-4: Wer ist besser?
Wenn wir Llemma und GPT-4 nebeneinander stellen, sind die Unterschiede deutlich. Llemma's spezieller Fokus auf Mathematik, unterstützt durch Berechnungswerkzeuge und dedizierte Datensätze, gibt ihm einen klaren Vorteil. Andererseits hat GPT-4 trotz seiner Fähigkeiten in der natürlichen Sprachverarbeitung aufgrund seiner Tokenisierungsprobleme Schwierigkeiten bei mathematischen Aufgaben.
-
Genauigkeit: Llemma zeichnet sich durch eine hohe Genauigkeit sowohl bei Berechnungen als auch beim Theorembeweis aus, dank seiner spezialisierten Schulung und Berechnungswerkzeuge. Im Gegensatz dazu hat GPT-4 eine nahezu 0%ige Genauigkeitsrate bei der Multiplikation von 5-stelligen Zahlen.
-
Flexibilität: Die Architektur von Llemma ermöglicht es ihm, sich an verschiedene mathematische Aufgaben anzupassen und darin hervorragende Leistungen zu erbringen, von grundlegenden Berechnungen bis zum komplexen Theorembeweis. GPT-4 fehlt diese Anpassungsfähigkeit im Bereich der Mathematik.
-
Effizienz: Llemma's Verwendung spezialisierter Datensätze wie AlgebraicStack gewährleistet, dass es mit hochwertigen Daten geschult wird und somit bei mathematischen Aufgaben äußerst effizient ist. GPT-4 kann mit seiner allgemeinen Schulung diesem Effizienzniveau nicht gleichkommen.
Zusammenfassend kann gesagt werden, dass GPT-4 zwar ein Alleskönner sein mag, aber Llemma ist der Meister einer Disziplin: Mathematik. Sein spezialisierter Fokus in Verbindung mit seinen fortschrittlichen Funktionen machen es zum bevorzugten Modell für jede mathematische Aufgabe. Im nächsten Abschnitt werden wir unsere Diskussion abschließen und einen Blick auf die Zukunft mathematischer Sprachmodelle wie Llemma werfen.
Fazit: Die Zukunft mathematischer Sprachmodelle
Wie wir gesehen haben, ist Llemma ein Zeugnis dafür, was spezialisierte Sprachmodelle erreichen können. Seine einzigartigen Fähigkeiten, mathematische Probleme zu lösen und Theoreme zu beweisen, unterscheiden es von allgemeinen Modellen wie GPT-4. Aber was bedeutet das für die Zukunft von Sprachmodellen in der Mathematik?
-
Spezialisierung statt Verallgemeinerung: Der Erfolg von Llemma legt nahe, dass die Zukunft in spezialisierten Sprachmodellen liegt, die für spezifische Aufgaben zugeschnitten sind. Während allgemeine Modelle ihre Vorzüge haben, ist das Fachwissen, das Llemma mitbringt, unübertroffen.
-
Integration von Berechnungswerkzeugen: Llemma's Verwendung von Python-Interpretern und formalen Theorembeweisern könnte den Weg für zukünftige Modelle ebnen, die externe Werkzeuge für spezialisierte Aufgaben integrieren. Dies könnte über Mathematik hinausgehen und Bereiche wie Physik, Ingenieurwesen und sogar Medizin umfassen.
-
Dynamische Tokenisierung: Die Tokenisierungsprobleme, mit denen GPT-4 konfrontiert ist, zeigen den Bedarf an dynamischeren und flexibleren Tokenisierungsmethoden, wie z.B. der xVal-Lösung. Die Implementierung solcher Techniken könnte die Leistung von allgemeinen Modellen in spezialisierten Aufgaben erheblich verbessern.
Kurz gesagt dient Llemma als Blaupause für das, was spezialisierte Sprachmodelle sein können und sollten. Es setzt nicht nur den Maßstab für mathematische Sprachmodelle, sondern bietet auch wertvolle Erkenntnisse, die dem breiteren Bereich der künstlichen Intelligenz zugute kommen können.
Referenzen
Für alle, die tiefer in die Welt mathematischer Sprachmodelle eintauchen möchten, finden Sie hier einige glaubwürdige Quellen für weitere Informationen:
- Llemma Project GitHub Repository (opens in a new tab)
- AlgebraicStack Dataset (opens in a new tab)
- xVal Research Paper (opens in a new tab)
Möchten Sie die neuesten Nachrichten über LLM erfahren? Schauen Sie sich das aktuelle LLM-Ranking an!
