Die Ära der 1-Bit Large Language Models: Microsoft stellt BitNet b1.58 vor
Published on
Einführung
Microsoft-Forscher haben eine bahnbrechende Variante des 1-Bit Large Language Models (LLM) namens BitNet b1.58 vorgestellt, bei dem jeder einzelne Parameter des Modells ternär ist und die Werte 1 annimmt. Dieses 1,58-Bit LLM ist in der Leistung vergleichbar mit vollpräzisen (FP16 oder BF16) Transformer LLMs mit derselben Modellgröße und Anzahl an Trainings-Token und gleichzeitig deutlich kosteneffizienter in Bezug auf Latenz, Speichernutzung, Durchsatz und Energieverbrauch. BitNet b1.58 ist ein großer Schritt nach vorn, um LLMs sowohl leistungsstark als auch hoch effizient zu machen.

Was ist BitNet b1.58?
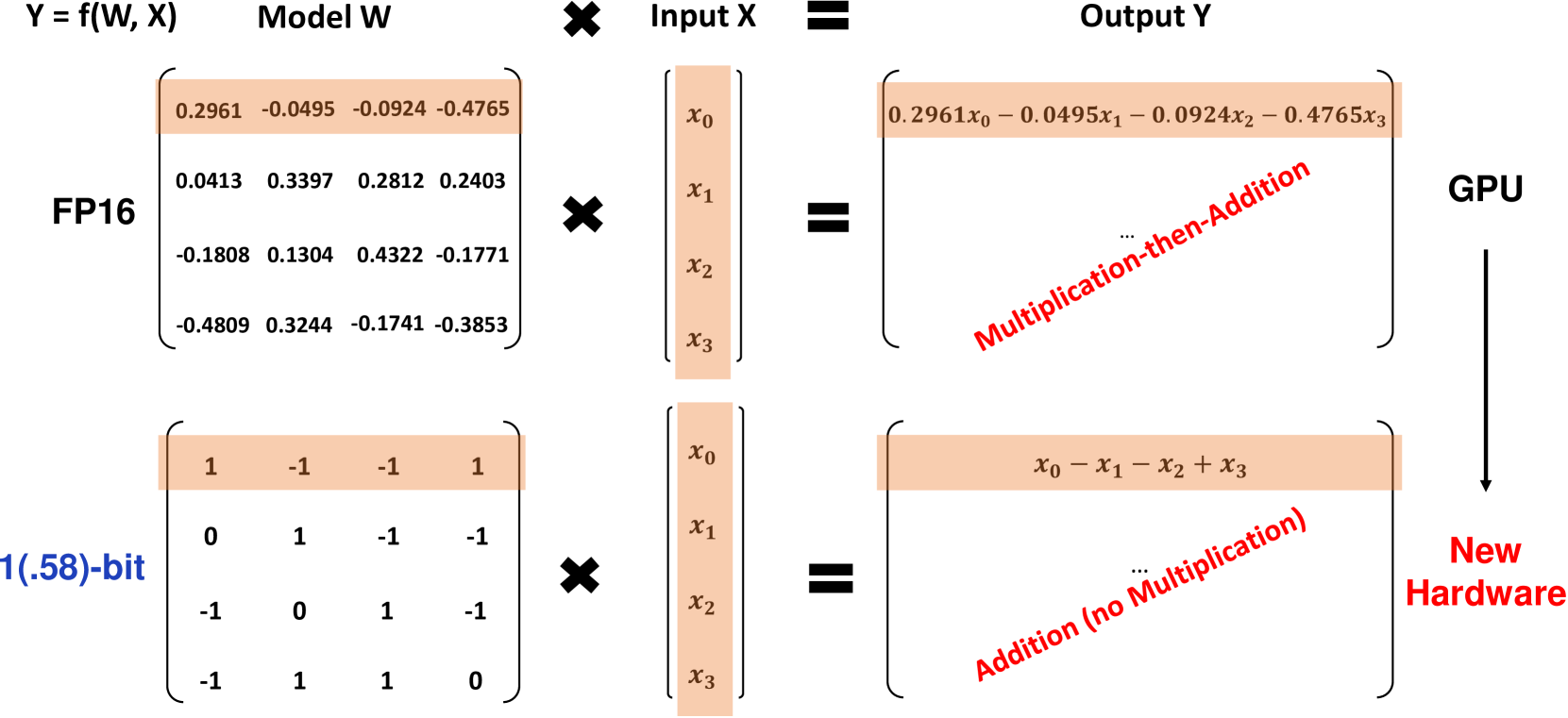
BitNet b1.58 basiert auf der ursprünglichen BitNet-Architektur, einem Transformer-Modell, das die herkömmlichen nn.Linear-Schichten durch BitLinear-Schichten ersetzt. Es wird von Grund auf mit 1,58-Bit Gewichten und 8-Bit Aktivierungen trainiert. Im Vergleich zum ursprünglichen 1-Bit BitNet führt b1.58 einige wesentliche Modifikationen ein:
-
Es verwendet eine absmean Quantisierungsfunktion, um die Gewichte auf 1 zu beschränken. Dabei werden die Gewichte nach Skalierung mit dem durchschnittlichen absoluten Wert auf den nächsten ganzzahligen Wert unter diesen Werten gerundet.
-
Für Aktivierungen werden diese auf den Bereich [-sa, sa] pro Token skaliert, was im Vergleich zum ursprünglichen BitNet eine einfachere Implementierung ermöglicht.
-
Es übernimmt Komponenten aus der beliebten Open-Source LLaMA-Architektur, wie beispielsweise RMSNorm, SwiGLU-Aktivierungen, rotierende Einbettungen und entfernt Bias. Dadurch lässt sich eine einfache Integration mit vorhandener LLM-Software erreichen.
Die Hinzufügung des Werts 0 zu den Gewichten ermöglicht die Merkmalsfilterung und erhöht damit die Modellierungsfähigkeit im Vergleich zu reinen 1-Bit-Modellen. Experimente zeigen, dass BitNet b1.58 ab einer Parametergröße von 3B eine vergleichbare Perplexität und End-Task-Leistung wie FP16-Baselines aufweist.
Leistungsergebnisse
Die Forscher verglichen BitNet b1.58 mit einem reproduzierten FP16 LLaMA LLM-Basislinienmodell bei verschiedenen Modellgrößen von 700M bis 70B Parametern. Beide Modelle wurden mit demselben RedPajama-Datensatz für 100B Token vortrainiert und auf Perplexität sowie eine Reihe von Zero-Shot-Sprachaufgaben evaluiert.
Die wichtigsten Erkenntnisse sind:
-
BitNet b1.58 erreicht bei einer Größe von 3B die gleiche Perplexität wie die FP16 LLaMA-Basislinie, ist jedoch 2,71-mal schneller und verbraucht 3,55-mal weniger GPU-Speicher.
-
Ein 3,9B BitNet b1.58 Modell erzielt eine bessere Perplexität und End-Task-Leistung als das 3B LLaMA-Modell bei geringerer Latenz und Speicherkosten.
-
Bei Zero-Shot-Sprachaufgaben verringert sich die Leistungslücke zwischen BitNet b1.58 und LLaMA mit zunehmender Modellgröße, wobei BitNet bei einer Größe von 3B mit LLaMA vergleichbar ist.
-
Bei Skalierung auf 70B erreicht BitNet b1.58 eine 4,1-fache Beschleunigung gegenüber der FP16-Basislinie. Auch die Speicherersparnis nimmt mit der Skalierung zu.
-
BitNet b1.58 verwendet 71,4-mal weniger Energie für Matrixmultiplikationen. Die End-to-End-Energieeffizienz steigt mit der Modellgröße.
-
Auf zwei 80GB A100-GPUs unterstützt ein 70B BitNet b1.58 Modell Chargengrößen, die um das 11-fache größer sind als bei LLaMA, was eine 8,9-fach höhere Durchsatz ermöglicht.
Die Ergebnisse zeigen, dass BitNet b1.58 eine Pareto-Verbesserung gegenüber führenden FP16 LLMs bietet - es ist in Bezug auf Latenz, Speicher und Energie effizienter und erzielt gleichzeitig bei ausreichender Skalierung eine vergleichbare Perplexität und End-Task-Leistung. Zum Beispiel ist ein 13B BitNet b1.58 Modell effizienter als ein 3B FP16 LLM-Modell, ein 30B BitNet effizienter als ein 7B FP16-Modell und ein 70B BitNet effizienter als ein 13B FP16-Modell.
Wenn BitNet b1.58 mit der StableLM-3B Methode auf 2T Token trainiert wird, übertrifft es StableLM-3B Zero-Shot in allen evaluierten Aufgaben und zeigt eine starke Generalisierungsfähigkeit.
Die folgenden Tabellen enthalten detailliertere Daten zu den Leistungsvergleichen zwischen BitNet b1.58 und der FP16 LLaMA-Basislinie:
| Modelle | Größe | Speicher (GB) | Latenz (ms) | PPL |
|---|---|---|---|---|
| LLaMA LLM | 700M | 2,08 (1,00x) | 1,18 (1,00x) | 12,33 |
| BitNet b1.58 | 700M | 0,80 (2,60x) | 0,96 (1,23x) | 12,87 |
| LLaMA LLM | 1,3B | 3,34 (1,00x) | 1,62 (1,00x) | 11,25 |
| BitNet b1.58 | 1,3B | 1,14 (2,93x) | 0,97 (1,67x) | 11,29 |
| LLaMA LLM | 3B | 7,89 (1,00x) | 5,07 (1,00x) | 10,04 |
| BitNet b1.58 | 3B | 2,22 (3,55x) | 1,87 (2,71x) | 9,91 |
| BitNet b1.58 | 3,9B | 2,38 (3,32x) | 2,11 (2,40x) | 9,62 |
Tabelle 1: Perplexitäts- und Kostenumvergleich zwischen BitNet b1.58 und LLaMA LLM.
| Modelle | Größe | ARCe | ARCc | HS | BQ | OQ | PQ | WGe | Durchschn. |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA LLM | 700M | 54,7 | 23,0 | 37,0 | 60,0 | 20,2 | 68,9 | 54,8 | 45,5 |
| BitNet b1.58 | 700M | 51,8 | 21,4 | 35,1 | 58,2 | 20,0 | 68,1 | 55,2 | 44,3 |
| LLaMA LLM | 1,3B | 56,9 | 23,5 | 38,5 | 59,1 | 21,6 | 70,0 | 53,9 | 46,2 |
| BitNet b1.58 | 1,3B | 54,9 | 24,2 | 37,7 | 56,7 | 19,6 | 68,8 | 55,8 | 45,4 |
| LLaMA LLM | 3B | 62,1 | 25,6 | 43,3 | 61,8 | 24,6 | 72,1 | 58,2 | 49,7 |
| BitNet b1.58 | 3B | 61,4 | 28,3 | 42,9 | 61,5 | 26,6 | 71,5 | 59,3 | 50,2 |
| BitNet b1.58 | 3,9B | 64,2 | 28,7 | 44,2 | 63,5 | 24,2 | 73,2 | 60,5 | 51,2 |
Tabelle 2: Zero-Shot-Genauigkeit von BitNet b1.58 und LLaMA LLM in Endaufgaben.
Die Decodierungs-Latenz und der Speicherverbrauch von BitNet b1.58 bei unterschiedlichen Modellgrößen werden in Abbildung 1 dargestellt. Die Verarbeitungsgeschwindigkeit nimmt mit der Modellgröße zu und erreicht eine Beschleunigung von 4,1x bei 70B Parametern im Vergleich zur FP16-Basislinie. Auch die Speichereinsparungen nehmen mit der Skalierung zu.
Siehe Bildunterschrift Siehe Bildunterschrift Abbildung 1: Decodierungs-Latenz (links) und Speicherverbrauch (rechts) von BitNet b1.58 bei unterschiedlichen Modellgrößen. In Bezug auf die Energieeffizienz verwendet BitNet b1.58 bei Matrixmultiplikationen 71,4-mal weniger Energie im Vergleich zu FP16 LLMs. Die End-to-End-Energiekosten über verschiedene Modellgrößen werden in Abbildung 2 dargestellt, wobei BitNet b1.58 bei größeren Skalen zunehmend effizienter wird.
Verweis auf die Bildunterschrift
Verweis auf die Bildunterschrift
Abbildung 2: Energieverbrauch von BitNet b1.58 im Vergleich zu LLaMA LLM. Links: Komponenten des Energieverbrauchs für arithmetische Operationen. Rechts: End-to-End-Energiekosten über verschiedene Modellgrößen.
Eine weitere entscheidende Stärke von BitNet b1.58 ist die Durchsatzrate. Mit zwei 80-GB-A100-GPUs unterstützt ein 70B BitNet b1.58 Batch-Größen, die um den Faktor 11 größer sind als bei einem 70B LLaMA LLM, was zu einer 8,9-fach höheren Durchsatzrate führt, wie in Tabelle 3 gezeigt.
| Modelle | Größe | Max. Batch-Größe | Durchsatz (Token/s) |
|---|---|---|---|
| LLaMA LLM | 70B | 16 (1,0x) | 333 (1,0x) |
| BitNet b1.58 | 70B | 176 (11,0x) | 2977 (8,9x) |
Tabelle 3: Durchsatzvergleich von 70B BitNet b1.58 und LLaMA LLM.
Implikationen und zukünftige Entwicklungen
Die Architektur und die Ergebnisse von BitNet b1.58 haben bedeutende Auswirkungen auf die Zukunft von LLMs:
-
Es etabliert eine neue Pareto-Front und Skalierungsgesetz für LLMs, die sowohl leistungsstark als auch hoch effizient sind. LLMs mit 1,58-Bit können FP16-Baselines bei deutlich geringeren Inferenzkosten erreichen.
-
Die drastische Speicherverringerung ermöglicht das Ausführen viel größerer LLMs auf einer festgelegten Hardwaremenge. Dies ist besonders bedeutsam für speicherintensive Architekturen wie "Mixture-of-Experts".
-
8-Bit-Aktivierungen ermöglichen eine doppelte Kontextlänge im Vergleich zu 16-Bit-Modellen bei gegebenem Speicherbudget. Eine weitere Komprimierung auf 4 Bits oder weniger ist in Zukunft möglich.
-
Die außergewöhnliche Effizienz von 1,58-Bit-LLMs auf CPU-Geräten ermöglicht den Einsatz leistungsstarker LLMs auf Edge/Mobile-Geräten, wo CPUs der Hauptprozessor sind.
-
Das neue Niedrig-Bit-Berechnungsparadigma von BitNet b1.58 motiviert die Entwicklung maßgeschneiderter KI-Beschleuniger und Systeme, die speziell für 1-Bit-LLMs optimiert sind, um das volle Potenzial auszuschöpfen.
Microsoft sieht 1-Bit-LLMs als einen vielversprechenden Weg, um LLMs erheblich kosteneffektiver zu machen und gleichzeitig ihre Fähigkeiten zu erhalten. Sie stellen sich eine Ära vor, in der 1-Bit-Modelle Anwendungen vom Rechenzentrum bis zum Edge mit Energie versorgen. Allerdings erfordert es die gemeinsame Gestaltung von Modellarchitekturen, Hardware und Software, um die einzigartigen Eigenschaften dieser Modelle vollständig zu nutzen. BitNet b1.58 stellt einen aufregenden Ausgangspunkt für diese neue Ära von LLMs dar.
Schlussfolgerung
BitNet b1.58 stellt einen bedeutenden Durchbruch bei der Maximierung großer Sprachmodelle durch Quantisierung dar und bewahrt dabei die Leistung. Durch die Verwendung von ternären 1 Gewichten und 8-Bit-Aktivierungen kann es FP16 LLMs in Perplexität und Endaufgabenleistung bei deutlich geringerer Speichernutzung, Latenz und Energieverbrauch erreichen.
Die 1,58-Bit-Architektur etabliert eine neue Pareto-Front für LLMs, bei der größere Modelle zu einem Bruchteil der Kosten ausgeführt werden können. Es eröffnet neue Möglichkeiten wie die native Unterstützung längerer Kontexte, den Einsatz leistungsstarker LLMs auf Edge-Geräten und motiviert die Entwicklung kundenspezifischer Hardware für KI mit niedriger Bitzahl.
Microsofts Arbeit zeigt, dass aggressiv quantisierte LLMs nicht nur machbar sind, sondern tatsächlich ein überlegenes Skalierungsgesetz im Vergleich zu FP16-Modellen etablieren. Durch eine weitere gemeinsame Gestaltung von Architekturen, Hardware und Software haben 1-Bit-LLMs das Potenzial, den nächsten großen Schritt in kosteneffektive KI-Fähigkeiten von der Cloud bis zum Edge zu ermöglichen. BitNet b1.58 bietet einen beeindruckenden Ausgangspunkt für diese spannende neue Ära von ultramodernen und äußerst effizienten Sprachmodellen.