OpenVoice: ローカルとクラウド展開のためのインスタント音声クローニング
- Name
- Jennie Rose
Published on
音声合成技術の急速な進化の中でも、OpenVoiceは、さまざまなアプリケーションに対応する多機能のインスタント音声クローニング機能を提供する画期的な存在となっています。MyShellチームによって開発されたオープンソースのOpenVoiceは、短い音声クリップから話者の声を複製し、多言語で現実的でカスタマイズ可能な音声を生成することができます。
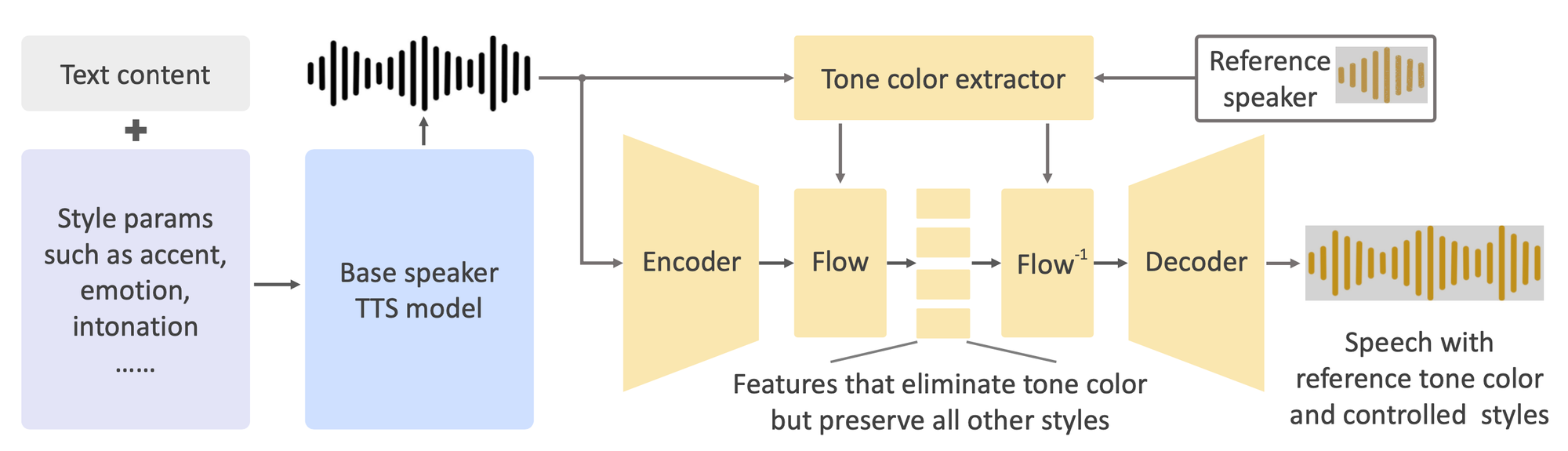
OpenVoiceの主な特徴
OpenVoiceは、他の音声クローニングソリューションとは異なる、印象的な特徴を搭載しています。
-
正確な音色クローニング: OpenVoiceは、参照話者の音色を正確にクローニングすることができ、生成された音声が元の声に近づくようにします。この機能は、オーディオブックのナレーションやパーソナライズされた仮想アシスタントなど、高度な真正性が求められるアプリケーションに特に役立ちます。
-
柔軟な音声スタイル制御: OpenVoiceの特筆すべき特徴の1つは、さまざまな音声スタイルパラメーターに対して細かな制御を提供できることです。ユーザーは感情、アクセント、リズム、一時停止、声の抑揚などの属性を調整することができ、幅広い表現の可能性があります。この柔軟性により、ユーザーは生成された音声を特定の文脈や好みに合わせることができます。
-
ゼロショットクロスリンガル音声クローニング: OpenVoiceは、訓練データセットに存在しなかった言語で音声を生成するという驚くべきゼロショットクロスリンガル音声クローニングを実現しています。この機能により、ローカライズされたコンテンツの作成や、言語ごとの大量のトレーニングデータの必要性を伴わずに、グローバルなオーディエンスに届くという興奮が生まれます。
パフォーマンスのベンチマーク
OpenVoiceのパフォーマンスを評価するために、MyShellチームはさまざまなGPU構成について包括的なベンチマークを実施しました。その結果、他のテキスト読み上げAPIと比較して、OpenVoiceの効率とコスト効果は非常に優れていることが示されています。
| GPU | 1秒あたりの単語数 | 1ドルあたりの単語数 |
|---|---|---|
| RTX 2070 | 132.7 | 66万 |
| RTX 3080 Ti | 230.4 | 45.3万 |
ベンチマークでは、RTX 2070 GPUが1ドルあたりに驚異的な66万単語を処理できることが明らかになり、大規模な音声クローニングプロジェクトに非常にコスト効果の高いオプションとなっています。一方、RTX 3080 Tiは最も高い処理速度を実現し、約230.4単語/秒を処理することができるため、素早いターンアラウンド時間を重視するアプリケーションに適しています。
これらのベンチマークは、シングルスレッドの操作に焦点を当てていますが、RTX 3080 TiのようなよりパワフルなGPUにおけるマルチスレッドの可能性は、パフォーマンスをさらに向上させ、コストとのバランスを狭めることができるでしょう。
OpenVoiceのローカルでの実行
OpenVoiceの重要な利点の1つは、ローカルでの実行が可能であることです。これにより、クラウドベースのAPIに完全に依存することなく、ユーザーはより大きな制御、プライバシー、およびコスト削減を実現することができます。以下に、ローカルマシンでOpenVoiceを設定して実行するための手順を説明します。
-
事前準備: 互換性のあるGPU(CUDAサポートを備えたNVIDIA GPU)と、Python、PyTorch、CUDA toolkitなどの必要な依存関係がインストールされていることを確認してください。
-
リポジトリのクローン: 以下のコマンドを使用して、公式のGitHubページからOpenVoiceリポジトリをクローンします。
git clone https://github.com/myshell-ai/OpenVoice.git -
依存関係のインストール: クローンしたリポジトリディレクトリに移動し、次のコマンドを使用して必要なPythonパッケージをインストールします。
cd OpenVoice pip install -r requirements.txt -
モデルの準備: 事前学習済みモデルのチェックポイントをダウンロードし、リポジトリ内の指定されたディレクトリに配置します。チェックポイントの取得に関する具体的な手順は、OpenVoiceのドキュメントに記載されています。
-
設定の構成: 設定ファイル(
config.jsonまたはconfig.yaml)を編集して、入力オーディオ形式、出力ディレクトリ、音声スタイルパラメーターなどの設定を指定します。 -
音声クローニングの実行: メインスクリプトを実行して、ローカルマシンで音声クローニングを実行します。参照音声クリップのパスとターゲットテキストを引数として指定します。
python main.py --reference_audio path/to/reference.wav --text "Hello, this is a test." -
結果の評価: 生成された音声は指定された出力ディレクトリに保存されます。合成されたオーディオを再生して、品質、自然さ、および参照音声との類似性を評価します。望む結果を得るために、設定を微調整し、異なる音声スタイルパラメーターで実験してみてください。
OpenVoiceをローカルで実行することで、外部のAPIに頼らずにインスタント音声クローニングの力を活用することができ、レイテンシを低減し、データのプライバシーを確保することができます。このローカル展開オプションは、厳密なセキュリティ要件を持つアプリケーションや、音声合成パイプラインを完全に制御したいユーザーに特に有益です。
結論
OpenVoiceは、声の合成の分野において重要なマイルストーンを代表し、インスタントでの声のクローニングのための多目的かつ利便性の高いソリューションを提供しています。正確な音色のクローニング、柔軟な声のスタイル制御、およびゼロショットの言語間能力により、OpenVoiceはユーザーが複数の言語でリアルで表現豊かな音声を作成することを可能にします。
印象的なパフォーマンスベンチマークは、OpenVoiceの費用対効果と効率を示しており、オーディオブックのナレーションや個人用仮想アシスタントから地域特化のコンテンツ作成まで、さまざまなアプリケーションにおいて魅力的な選択肢となっています。
さらに、OpenVoiceをローカルで実行できる能力により、ユーザーはクラウドベースのAPIに完全に依存することなく、より大きな制御、プライバシー、およびコストの節約を享受することができます。
オープンソースコミュニティがOpenVoiceの開発と改良に貢献し続けることで、声の合成の分野ではさらなる進歩と革新が期待されます。その多目的性、利便性、および印象的な機能により、OpenVoiceは私たちの声のコンテンツの相互作用や作成方法を革新し、クリエイターや開発者、ビジネスにとってもエキサイティングな可能性を広げています。
