2023年のベスト10ベクトルデータベース:完全なレビュー

ベクトルデータベースは、もはやデータサイエンティストやデータベース管理者の間でのみ議論されていたニッチなトピックではありません。2023年に入るにつれて、画像、音声、テキストなどの複雑なデータ型を扱う人々にとって重要なテーマとなってきました。しかし、ベクトルデータベースとは具体的にどのようなものなのでしょうか?なぜそれほど注目されているのでしょうか?
この記事では、ベクトルデータベースを徹底的に解明し、その利点と欠点を分析し、彼らを取り巻くハイプを明らかにします。また、2023年のトップ9のベクトルデータベースに焦点を当て、オープンソースのオプションに特別な注目を注ぎます。では、さっそく始めましょう!
最新のLLMリーダーボードで最新のLLMニュースを知りたいですか?
ベクトルデータベースとは?
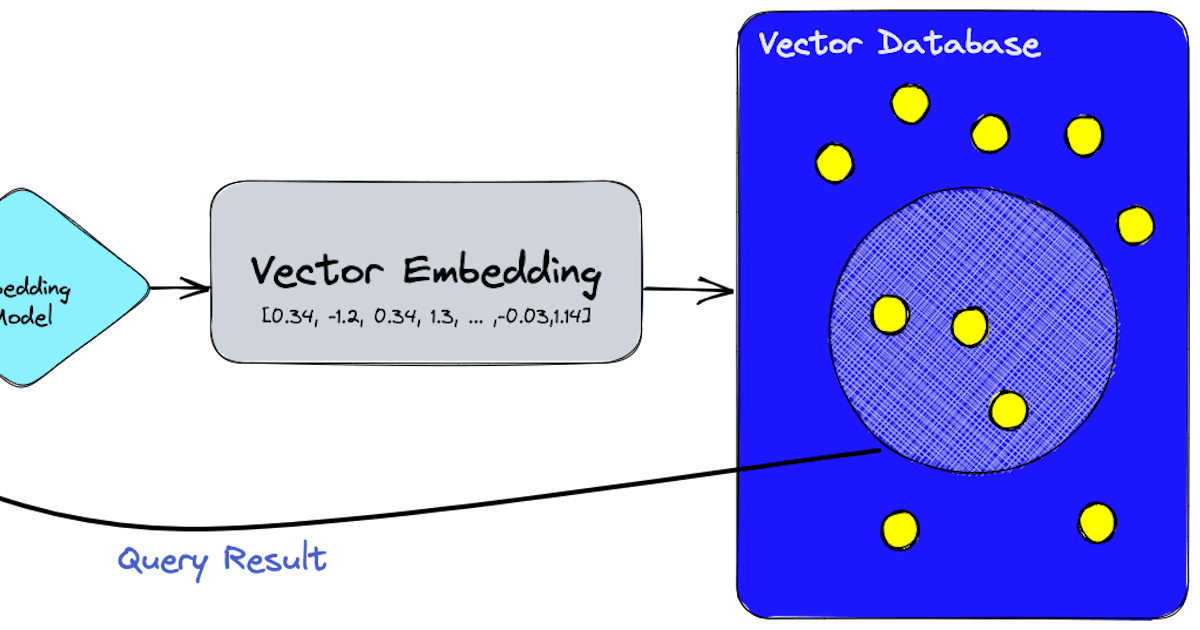
ベクトルデータベースは、従来のデータベースが扱いにくい複雑なデータ型を処理するために設計された特殊なデータベースです。データをテーブルに格納する従来の関係データベースとは異なり、ベクトルデータベースは数学的ベクトルを使用してデータを表現します。これにより、画像、音声ファイル、テキストのような高次元データを効率的に管理し、検索することができます。
ベクトルデータベースは、k-NN(k最近傍)などのアルゴリズムを使用して高次元データを検索します。また、量子化やパーティショニングなどの技術も使用して、検索パフォーマンスを最適化しています。以下は、ベクトルデータベース内の類似画像を検索するためのサンプルプロンプトです:
SELECT * FROM images WHERE VECTOR_SEARCH(image_vector, target_vector) < 0.2;このサンプルプロンプトでは、VECTOR_SEARCHはimage_vectorとtarget_vectorの類似度を計算する関数です。< 0.2は類似度の閾値を指定しています。
ベクトルデータベースの異なる点は何ですか?
-
高次元データの取り扱い: 従来のデータベースは高次元データの取り扱いに適していません。ベクトルデータベースは数学的ベクトルを使用することで、複雑なデータ型を扱いやすくしています。
-
高速検索機能: ベクトルデータベースの特徴の一つは、高速な類似度検索が可能なことです。たとえば、画像を持っている場合、ベクトルデータベースは各エントリをスキャンすることなく、データベース内の類似画像を素早く見つけることができます。
-
スケーラビリティ: データが増えるにつれて、パフォーマンス劣化なしでスケーリングできるデータベースの必要性が重要になります。ベクトルデータベースはスケーラビリティを考慮して構築されており、大量のデータを効率的に処理できます。
ベクトルデータベースのレビュー:期待に応えるか?
新興技術のように、ベクトルデータベースも相当なハイプに囲まれています。多くの人々がベクトルデータベースがデータベースの風景を10年前に変えたNoSQLのムーブメントになぞらえて次の大きな進化となると主張しています。しかし、これらの主張のどれだけが真実であり、何に注意すべきでしょうか?
ベクトルデータベースの辛い真実:適応すべきですか?
ハイプは完全に根拠がないわけではありません。特に複雑な高次元データを扱う場合、ベクトルデータベースは従来のデータベースにはない独自の機能を提供します。しかし、重要なのは本質的な機能を提供することに重点を置いているベクトルデータベースと、マーケティングに重点を置いているベクトルデータベースとを区別することです。
ベクトルデータベースを選ぶ際に注意すべきポイント:
-
過大広告と低品質: 一部のベクトルデータベースは月を約束しますが、高可用性、バックアップシステム、ジオスペーシャルや日付時刻などの高度なデータ型などの重要な機能を提供できません。
-
複雑さ: ベクトルデータベースは強力ですが、セットアップや管理が複雑なことがあります。対応するための技術的な専門知識を持っているか、トレーニングに投資する覚悟が必要です。
-
コスト: 特許データベースの場合、隠れたコストに注意が必要です。ライセンス料が積み上がり、専用のハードウェアにも投資する必要があるかもしれません。
これらのポイントに注意することで、ハイプを見極め、より情報を持った意思決定をすることができます。常にマーケティングのキャッチフレーズを超えて、データベースの実際の機能と制限を深く探求することを忘れないでください。
ベクトルデータベースの利点と欠点
ベクトルデータベースは、画像、音声、テキストなどの複雑なデータ型を扱う能力によって注目を集めています。しかし、その利点と制限の両方を理解することが重要です。
ベクトルデータベースの利点:
-
効率的な類似度検索: ベクトルデータベースは、レコメンデーションシステム、画像認識、自然言語処理などに不可欠な高次元空間の最近傍を見つける能力に優れています。
-
スケーラビリティ: 多くのベクトルデータベースは大規模なデータを処理するために設計されており、一部は水平スケーリングのための分散アーキテクチャを提供しています。
-
柔軟性: 異なる距離指標やインデックスアルゴリズムのサポートにより、ベクトルデータベースは特定のユースケースに高い適応性を持つことができます。
-
リソースの消費: 高速な検索はコンピュータリソースの消費を伴うことがあります。最適なパフォーマンスを得るためには、専用のハードウェアが必要な場合もあります。
ベクトルデータベースの欠点:
- 複雑さ: アルゴリズムの選択肢や設定の多さから、ベクトルデータベースのセットアップや保守は難しい場合があります。
- コスト: オープンソースのオプションもありますが、商用のベクトルデータベースは特に大規模な展開には高価です。
2023年に考慮すべきトップ10のベクトルデータベース
2023年のトップオープンソースベクトルデータベース
1. Faiss
- 初期価格: 無料(オープンソース)
- 評価: 4.7/5
- 長所:
- CUDAを介した優れたGPUアクセラレーション
- 数十億のベクトルをサポート
- IVFADC、PQ、およびHNSWなどの幅広いアルゴリズムオプションをサポート
- 短所:
- ベクトル量子化の専門知識が必要
- シングルノード展開に制限がある
技術的詳細: Faiss (opens in a new tab)では、Inverted File Segmenter(IVF)やScalar Quantizer(SQ)などのインデックス技術を組み合わせて、効率的な類似性検索を実現しています。また、バッチクエリ処理や複数のGPU間での並列処理もサポートしています。このライブラリはL2距離と内積類似性の両方に最適化されており、異なるユースケースに対応しています。
Faiss Vector Database GitHub: https://github.com/facebookresearch/faiss (opens in a new tab)

2. Annoy(Approximate Nearest Neighbors Oh Yeah)
- 初期価格: 無料(オープンソース)
- 評価: 4.5/5
- 長所:
- ベクトル空間の分割に木の森を利用
- 大規模データのためのメモリマップドファイルサポート
- クエリの漸近的な計算量は(O(\log N))
- 短所:
- Angular、Euclidean、Manhattan、Hammingの距離尺度に限定される
- 分散コンピューティングのネイティブサポートがない
技術的詳細: Annoy Vector Database (opens in a new tab)は、各ベクトルに対してバイナリツリーを構築し、空間を半空間に分割します。その後、ツリーは効率的な最近傍探索に使用されます。また、マルチスレッドのビルド時間のサポートやインデックスのディスクへの保存、メモリマップドへの後続の利用も可能で、大規模な類似性検索に適しています。
Annoy Vector Database GitHub: https://github.com/spotify/annoy (opens in a new tab)
3. NMSLIB(Non-Metric Space Library)
- 初期価格: 無料(オープンソース)
- 評価: 4.6/5
- 長所:
- Cosine、Jaccard、Levenshteinなどの多様な距離尺度をサポート
- 効率的な検索のためにHierarchical Navigable Small World(HNSW)グラフを利用
- 密なデータベクトルと疎なデータベクトルの両方に最適化
- 短所:
- 多くのアルゴリズムオプションによる急激な学習曲線
- 限られたコミュニティのサポートとドキュメンテーション
技術的詳細: NMSLIB Vector Database (opens in a new tab)は、VPツリーやSWグラフ、HNSWなどの高度なアルゴリズムをインデックス作成に使用しています。また、近似最近傍探索(ANN)検索もサポートしており、クエリのパフォーマンスと精度のバランスを実現しています。このライブラリは低遅延、高スループットのパフォーマンスに最適化されており、リアルタイムアプリケーションに適しています。
NMSLIB Vector Database GitHub: https://github.com/nmslib/nmslib (opens in a new tab)
商用ベクトルデータベース:期待に応える価値はあるか?
4. Milvus
- 初期価格: 無料(オープンソース)
- 評価: 4.2/5
- 長所:
- スケーラビリティ: サブセカンドのレイテンシで最大1000億のベクトルを処理可能。
- 距離尺度: Euclidean、Cosine、Jaccardなどの距離尺度をサポート。IVF_FLAT、IVF_PQ、HNSWなどのインデックスタイプもサポート。
- 短所:
- データ型: ジオスペーシャルおよび日付型のサポートなし。
- バックアップ: 組み込みのバックアップシステムがない。
- 認証: 一貫性のないセキュリティ機能。
- メタデータの保存にMySQLやSQLiteなどの追加のコンポーネントが必要
- トランザクションのサポートが限定的で、ACID準拠のアプリケーションには適さない
Milvusの利点: Milvusはクラウドネイティブ環境向けに設計されており、水平スケーリングをサポートしています。効率的なデータの取得のために、ツリーベースのインデックスとハッシュベースのインデックスを組み合わせたハイブリッドインデックスシステムを採用しています。システムはさらにベクトルのプルーニングやクエリのフィルタリングをサポートし、より複雑な検索条件に対応します。
Milvusの欠点: Milvusはオープンソースでスケーラブルなのですが、制約もあります。ジオスペーシャルや日付など、高度なデータ型のサポートがありません。これはGISや時系列解析のアプリケーションにとって重要な欠点です。組み込みのバックアップシステムがないことも重大な問題です。OAuthやLDAPなどのセキュリティ機能の実装の一貫性も心配材料です。

5. Pinecone
- 初期価格: 月額$30から
- 評価: 3.9/5
- 長所:
- 完全に管理されたサービス
- 組み込みのデータバージョニングとロールバック機能
- マルチテナンシーサポート
- 短所:
- コスト: データの規模に応じてコストが急速に上昇し、データサイズが指数関数的に増加する可能性があります。
- 機能の制約: 結合、トランザクション、高度なインデックスのサポートがありません。
- ドキュメンテーション: 技術的なドキュメンテーションが乏しい。
- 管理された性質による限定されたカスタマイズ
Pineconeの利点: Pineconeは密なベクトルと疎なベクトルの両方に最適化された専有のベクトルインデックスアルゴリズムを採用しています。スケーラビリティのために分散、シャーディングアーキテクチャを使用し、簡単な統合のためにRESTful APIを提供しています。ただし、ソースコードへのアクセス権限がないため、機能の拡張やカスタマイズを希望するユーザーにとっては制約となるかもしれません。
Pineconeの欠点: Pineconeの商用性は大規模データセットに対して高いコストがかかります。複雑なデータ操作には欠かせない結合やトランザクションのサポートがありません。技術的なドキュメンテーションが十分でないという点は、製品がマーケティングの期待に応えられない可能性を示唆しています。

6. Zilliz
- 初期価格: カスタムプライシング
- 評価: 3.7/5
- 長所:
- REST API: 既存のアプリケーションとの簡単な統合が可能です。
- 属性検索: 基本的な属性検索操作がサポートされています。
- クラウドベース: オペレーションのオーバーヘッドなしで拡張性があります。
- デメリット:
- コスト: データサイズに応じた指数関数的な価格設定です。
- 機能の制約: 結合、トランザクション、高度なインデックスがありません。
- ドキュメント: 技術的なドキュメントが乏しいです。
- ジオスペーシャルや日時などの高度なデータ型の欠如。
Zillizの利点: Zillizは、IVF_SQ8やNSGを含むさまざまなインデックスアルゴリズムを使用し、高速なクエリ処理のためのGPUアクセラレーションをサポートしています。また、SQLに似たクエリ言語も提供しており、より複雑な検索条件を可能にします。ただし、高可用性機能の透明性の欠如は、ミッションクリティカルなアプリケーションには適しているか疑問があります。
Zillizのデメリット: Zillizは結合やトランザクションなどの重要な機能が欠けており、本格的なアプリケーションには信頼性がありません。データのレプリケーションや自動フェイルオーバーといった高可用性機能の欠如はリスクです。バックアップシステムは不十分であり、データ復旧に追加のリソースが必要です。

ベクトルデータベースの評価方法
ベクトルデータベースを評価する際には、以下の技術的な側面を考慮してください:
- 機能セット: 結合、トランザクション、高度なデータ型をサポートしていますか?
- 拡張性: 大規模なデータを効率的に処理できますか?
- コスト: 提供されている機能に応じた価格設定はどうですか?
- コミュニティのサポート: アクティブなコミュニティのサポートや詳細なドキュメンテーションはありますか?
- ベンチマーク: クエリパーセカンド(QPS)、レイテンシ、スループットなどのパフォーマンスベンチマークを使用して比較してください。
詳細については、このGitHubリポジトリ (opens in a new tab)で提供されているツールをベクトルデータベースのベンチマークとして実行できます。
2023年のベストなオープンソースのベクトルデータベースの代替手段
7. Qdrant:コミュニティの選択肢
- 開始価格: 無料(オープンソース)
- 評価: 4.5/5
メリット:
- ローカルとクラウドベース: 両方の展開オプションを提供し、柔軟性を提供します。
- インメモリモード: コンテナを起動せずにテストが可能です。
- 移行に対応: 他のツールからの多くの移行経験があります。
デメリット:
- ドキュメント: より包括的なガイドがあるとよいでしょう。
- コミュニティの規模: 他のオープンソースのオプションに比べて、コミュニティの規模が小さいです。
- 機能セット: まだ成長中で、一部の高度な機能が不足している可能性があります。
技術的な詳細: Qdrant (opens in a new tab)はローカルとクラウドベースの両方のオプションを提供し、柔軟な選択肢となっています。ただし、コミュニティが少なく、より包括的なドキュメンテーションが必要とされています。注目を集めている一方で、機能セットはまだ成長中で、一部の高度なオプションが不足しているかもしれません。
Qdrantリンク: https://qdrant.tech/ (opens in a new tab)

8. Cassandra/AstraDB:スケーラビリティの王者
開始価格: 無料のティアが利用可能 評価: 4.3/5
メリット:
- スケーラビリティ: 大量のスループットを処理できることで知られています。
- ローカルとクラウドベース: 両方の展開オプションが利用可能です。
- 業界での評価: 数年間業界での地位を保っています。
デメリット:
- 複雑さ: 新規ユーザーには険しい学習曲線があります。
- コスト: 無料ティアには制限があり、価格が上昇する可能性があります。
- ベクトルサポート: 元々はベクトルデータ用に設計されていないため、一部の機能が不足しているかもしれません。
技術的な詳細: Apache Cassandra (opens in a new tab)/DataStax AstraDB (opens in a new tab)はスケーラビリティに優れていますが、学習曲線が険しいです。無料ティアを提供していますが、制限にすぐに達してしまい、コストが上昇する可能性があります。また、元々ベクトルデータ用に設計されていないため、一部の特殊な機能が不足している場合があります。
Apache Cassandra: https://cassandra.apache.org (opens in a new tab) DataStax AstraDB: https://www.datastax.com/products/datastax-astra (opens in a new tab)

9. MyScale DB: Pineconeの代替としてのSQLのパワーハウス
開始価格: 寛大な無料ティア 評価: 4.1/5
メリット:
- SQLサポート: 全てのデータ操作に完全かつ拡張されたSQLサポートを提供します。
- 高速: クラウドネイティブのOLAPデータベースアーキテクチャによる高速な操作性。
- 構造化データとベクトル化データ: 単一のデータベースで両方を管理します。
デメリット:
- 新参者: 比較的新しい製品であり、コミュニティのサポートが不足しているかもしれません。
- ドキュメント: より技術的なガイドがあるとよいでしょう。
- 複雑性: 全ユーザーに適していない、SQLの知識が必要です。
技術的な詳細: MyScale DB (opens in a new tab)は寛大な無料ティアと完全なSQLサポートを提供し、SQLに精通している方には強力な選択肢です。ただし、比較的新しい製品であるため、充実したコミュニティサポートが欠けている可能性があり、より技術的なドキュメンテーションが必要とされています。
MyScale DB: https://myscale.com (opens in a new tab)
10. SPTAG (Space Partition Tree and Graph)
- 開始価格: 無料(オープンソース)
- 評価: 4.3/5
- メリット:
- Microsoftによって開発され、信頼性が保証されています。
- 高速なk-NN検索機能
- 数十億のベクトルを持つ大規模データベースに最適化されています。
- デメリット:
- コミュニティのサポートが限られています。
- 他のオープンソースのオプションに比べてドキュメンテーションが十分でないです。 技術的な詳細:SPTAG (opens in a new tab)は、KDツリーやボールツリーを使用してインデックスを作成し、高速なk-NN検索を可能にします。大規模なデータベースに最適化されており、効率的に数十億のベクトルを扱うことができます。このアルゴリズムは、マルチスレッドの検索とバッチクエリ処理もサポートしています。
SPTAG GitHub: https://github.com/microsoft/SPTAG (opens in a new tab)
よくある質問
メインのベクトルデータベースは何ですか?
2023年時点での主要なベクトルデータベースには、Faiss、Annoy、NMSLIB、Milvus、Pinecone、Zilliz、Elasticsearch、Weaviate、Jina、SPTAGなどがあります。
フリーのベクトルデータベースはありますか?
はい、Faiss、Annoy、NMSLIB、Milvus、Weaviate、Jina、SPTAGなど、いくつかの無料のオープンソースのベクトルデータベースがあります。
Pineconeは最高のベクトルDBですか?
Pineconeは完全に管理されたサービスを提供し、使いやすいですが、「最高」とは具体的なニーズによります。オープンソースではなく、大規模な展開にはコストがかかる場合もあります。
ベクトルデータベースの選び方は?
ベクトルデータベースの選び方は、扱っているデータの種類、プロジェクトのスケール、予算など、さまざまな要素に依存します。FaissやAnnoyなどのオープンソースオプションは、より制御とカスタマイズが必要な場合に優れています。一方、Pineconeのようなマネージドサービスは使いやすさが重視される場合に適しています。
結論
ベクトルデータベースは、複雑な高次元データを扱うための重要なツールです。類似性検索の効率化やスケーラビリティなど、多くの利点がありますが、それぞれの制約もあります。FaissやAnnoyなどのオープンソースオプションは優れたパフォーマンスと柔軟性を提供しますが、学習曲線が急な場合もあります。一方、Pineconeのような商用オプションは使いやすさがありますが、高額な場合もあります。したがって、自分のニーズに最も合ったベクトルデータベースを慎重に選ぶことが重要です。
最新のLLMニュースを知りたいですか?最新のLLMリーダーボードをチェックしてください!
