LLaVA-Med: 생체 의학 이미징에서의 다음 큰 도약

의료 이미징의 세계는 패러다임 전환을 목격하고 있습니다. 건강 관련 전문가들이 의료 검사를 해석하는 데에 오직 예리한 시력과 몇 년간의 경험에만 의존하던 시절은 지나갔습니다. LLaVA-Med가 등장했습니다. 유명한 LLaVA 모델의 특별한 변종 중 하나인 LLaVA-Med는 생체 의학 분야에 특화된 디자인입니다. 이 강력한 도구는 또 하나의 기술적인 조각이 아니라, 진단과 치료 계획의 미래를 대표합니다. X선, MRI 또는 복잡한 3D 이미지 등 어떤 의료 이미지를 보더라도, LLaVA-Med는 전통적인 실천 방식과 첨단 AI 기술 사이의 간극을 줄이는 비교할 수 없는 통찰력을 제공합니다.
손끝에서 의료 이미지 또는 텍스트에 대한 철저한 분석을 제공할 수 있는 조수가 있다고 상상해보세요. 바로 LLaVA-Med입니다. 정확성과 다모달 기능을 결합한 이 도구는 전 세계의 의료 전문가들에게 부족할 수 없는 동반자가 될 것입니다. 어떤 이유에서든지 작성된 참고 문헌과 의료 이미지를 해석하는 것이 이 도구의 특징입니다.
최신 LLM 뉴스를 알고 싶으신가요? 최신 LLM 리더보드를 확인하세요!
LLaVA-Med란 무엇인가요?
LLaVA-Med는 생체 의학 분야에 특화된 고유의 LLaVA 모델 변형입니다. 의료 전문가들에게는 귀중한 도구로써 실제 의료 이미지와 텍스트를 해석하고 분석하는 능력을 제공합니다. X선, MRI 또는 복잡한 3D 이미지를 살펴보더라도, LLaVA-Med는 진단과 치료 계획에 도움이 되는 자세한 통찰력을 제공합니다.
Microsoft가 오픈 소스 #LLaVA를 세밀하게 조정하여 LLaVA-Med를 만들었습니다. 이 비전-언어 모델은 생체 의학 이미지를 해석할 수 있습니다. 이 모델을 귀사의 연구에서 학습시켜 정확하고 귀사의 언어와 톤에 맞는 텍스트를 생성할 수도 있습니다. pic.twitter.com/rnSOWITTLB
— Paulo Kuriki, MD (@kuriki) October 8, 2023
LLaVA-Med의 특징
-
의료 데이터에 대한 세밀한 조정: 일반적인 목적을 가진 LLaVA 모델과는 달리 LLaVA-Med는 의학 저널, 임상 기록 및 다양한 의료 이미지로 구성된 전문 데이터셋에서 학습했습니다.
-
높은 정확성: LLaVA-Med는 의료 이미지 해석에서 다른 의료 이미징 소프트웨어보다 뛰어난 정확성을 자랑합니다.
-
다모달 기능: LLaVA-Med는 텍스트와 이미지 모두를 분석할 수 있으므로, 종종 글로 기록된 메모와 의료 이미지를 함께 담고 있는 환자 기록 해석에 이상적입니다.
LLaVA-Med의 평가: 그 정확성은 어떤가요?
제공된 표의 정보를 텍스트로 통합하겠습니다.
1. LLaVA-Med의 시각적인 생체 의학 해석 능력:
광범위한 LLaVA 모델에 근거한 LLaVA-Med는 시각적 생체 의학 데이터를 해석하는 능력에 독특하게 초점을 맞춥니다.
-
평가용 벤치마크 데이터세트: LLaVA-Med와 다른 모델은 시각적 질문 응답 능력을 테스트하는 VQA-RAD, SLAKE, PathVQA와 같은 특정 벤치마크와 함께 다양한 데이터세트에서 평가됩니다. 이러한 벤치마크는 모델이 방사선학, 병리학 등에서 시각적 질문에 대한 능력을 평가합니다.
-
지도형 세밀 조정 결과: 다른 방법을 사용하여 지도형 세밀 조정 실험에서 얻은 결과들을 표에 보여줍니다:
| 방법 | VQA-RAD (참조) | VQA-RAD (오픈) | VQA-RAD (마감) | SLAKE (참조) | SLAKE (오픈) | SLAKE (마감) | PathVQA (참조) | PathVQA (오픈) | PathVQA (마감) |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA | 50.00 | 65.07 | 78.18 | 63.22 | 7.74 | 63.20 | |||
| LLaVA-Med (LLaVA) | 61.52 | 84.19 | 83.08 | 85.34 | 37.95 | 91.21 | |||
| LLaVA-Med (Vicuna) | 64.39 | 81.98 | 84.71 | 83.17 | 38.87 | 91.65 | |||
| LLaVA-Med (BioMed) | 64.75 | 83.09 | 87.11 | 86.78 | 39.60 | 91.09 |
지표 설명:
-
방법: 평가 중인 모델의 특정 버전 또는 접근 방식을 나타냅니다. 이는 LLaVA와 LLaVA-Med의 다양한 변형 및 출처를 포함합니다.
-
VQA-RAD (참조, 오픈, 마감): 방사선학에서 시각적 질문에 대한 지표입니다. '참조'는 참조 점수를 의미하고, '오픈'은 오픈형 질문 점수를 의미하며, '마감'은 폐쇄형 질문 점수입니다.
-
SLAKE (참조, 오픈, 마감): SLAKE 벤치마크에 대한 지표입니다. '참조'는 참조 점수를 의미하고, '오픈'은 오픈형 질문 점수를 의미하며, '마감'은 폐쇄형 질문 점수입니다.
-
PathVQA (참조, 개방형, 폐쇄형): 병리학 시각 질문 응답에 관련된 지표입니다. '참조'는 참고 점수를 나타내며, '개방형'은 개방형 질문 점수를 나타내고, '폐쇄형'은 폐쇄형 질문 점수를 나타냅니다.
참고: 연구 소스 (opens in a new tab)
LLaVA-Med의 다양한 방법으로 유도된 결과를 비교해보면, 모델이 시각적인 생체 의학적 해석에서 뛰어난 성능을 보여준다는 것이 분명합니다. 특히 VQA-RAD와 SLAKE와 같은 벤치마크와 비교 평가 시에 이러한 능력을 강조합니다. 이러한 능력은 시각 데이터를 기반으로 한 의료 전문가들이 더욱 사실에 근거한 결정을 내릴 수 있도록 돕는 잠재력을 나타냅니다.
2. LLaVA-Med의 지시에 따른 능력:
LLaVA 모델로부터 파생된 LLaVA-Med의 전문성은 생체 의학적 세부 사항에 대한 특별한 강조로 인해 두드러지게 나타납니다.
-
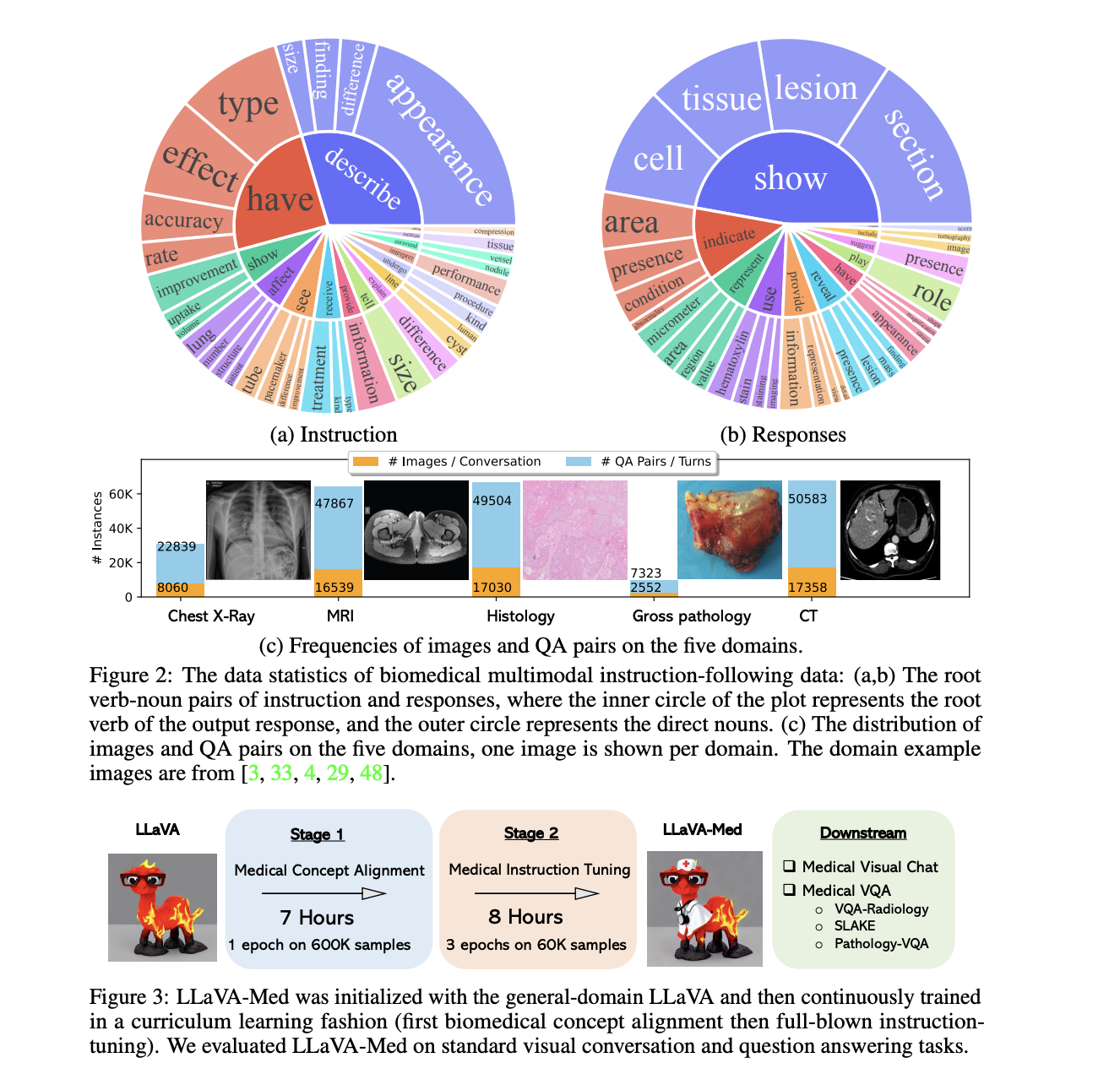
모델 개선을 위한 데이터셋: LLaVA-Med의 개선은 생체 의학적 다중 모달 지시어 데이터셋을 활용했습니다. 다양한 현실 세계의 생체 의학적 맥락을 포괄하는 이 데이터셋은 LLaVA-Med의 의료 지식 표출 및 이해 능력을 향상시킵니다.
-
이중 단계 적응에 대한 통찰:
- 단계 1 (생체 의학적 개념 통합): 이 기초적인 단계는 매우 중요합니다. 이 단계는 LLaVA의 포괄적인 지식을 독립적인 생체 의학적 개념과 통합하는 데 초점이 있었습니다. 이 단계는 후속 개선이 의료의 복잡성과 일치하도록 보장했습니다.
- 단계 2 (종합적인 지시어 조정): 이 중요한 단계에서 모델은 생체 의학적 지시어에 대한 강력한 훈련을 받아 의료적 맥락을 직관적으로 이해하고 다룰 수 있는 능력을 강화했습니다.
LLaVA 대 LLaVA-Med의 비교 성능:
| 모델 이터레이션 | 대화 (%) | 설명 (%) | 흉부 X-Rays (%) | MRI (%) | 조직 검사 (%) | 총계 (%) |
|---|---|---|---|---|---|---|
| LLaVA | 39.4 | 26.2 | 41.6 | 33.4 | 38.4 | 36.1 |
| LLaVA-Med 단계 1 | 22.6 | 25.2 | 25.8 | 19.0 | 24.8 | 23.3 |
| LLaVA-Med 단계 2 | 52.4 | 49.1 | 58.0 | 50.8 | 53.3 | 53.8 |
지표 설명:
-
모델 이터레이션: 검토되는 모델의 특정 이터레이션 또는 단계를 지정합니다. 이는 전반적인 LLaVA, LLaVA-Med의 주요 단계 이후, 및 보조 단계 이후를 포함합니다.
-
대화 (%): 모델의 문맥 대화 유지 및 관련 응답 제공 능력을 강조하는 지표입니다.
-
설명 (%): 의학 시각 자료를 상세히 설명하는 모델의 능력을 나타내는 지표입니다. 전달된 세부 사항이 정확한지 확인합니다.
-
흉부 X-Rays (%): 임상 진단에 꼭 필요한 흉부 X-선의 해석에 LLaVA-Med의 정확도를 평가합니다.
-
MRI (%): 자기공명 영상 결과를 분석하고 설명하는 모델의 능력을 측정합니다. 자기공명영상은 의료 진단 및 치료 결정에 중요한 정보를 제공합니다.
-
조직 검사 (%): 미세 조직 연구를 검토하는 모델의 효능을 반영합니다. 세포 이상을 정확히 파악하는 데 필수적입니다.
-
총계 (%): 다양한 범주에서 모델의 성능을 종합적으로 나타내는 점수입니다.
참고: 연구 소스 (opens in a new tab)
3. LLaVA-Med 비주얼 챗봇, 간단히 설명하기:
LLaVA-Med는 단순히 좋은 말 능력뿐만 아니라 그림도 잘 이해합니다.
-
여러 가지 잘하는 것: LLaVA-Med는 다양한 의료 이미지에 대해 많은 지식을 가지고 있습니다. X-선부터 자기공명영상(MRI) 및 심지질이미지까지 사진을 볼 수 있습니다.
-
많은 데이터: 왜 그렇게 잘하는 걸까요? 많은 사진과 텍스트를 보고 학습했습니다. 그래서 X-선, 체부 검사, 심지질 사진과 같은 것들을 알고 있습니다.
-
실제 세계에서의 활용: 수백 개의 X-선 사진을 검토하는 의사를 생각해보세요. LLaVA-Med는 이러한 사진을 빠르게 확인하여 문제를 지적하고 의사의 업무를 더욱 쉽게 만들어 줄 수 있습니다.
-
GPT-4와의 비교: GPT-4는 말 책임이 큽니다. 그러나 의료 사진을 이해하고 이에 대해 이야기할 때 LLaVA-Med가 더 잘 수행합니다. 의료 사진을 확인하고 자세히 설명할 수 있습니다.
-
완벽하지는 않습니다: LLaVA-Med도 가끔 한계가 있습니다. 때로는 사진이 그가 알고 있는 것과 너무 다른 경우 혼란을 겪을 수 있습니다. 그러나 더 많은 사진을 보면서 학습하고 성장할 수 있습니다.
LLaVA-Med 설치 방법: 단계별로
LLaVA-Med를 설치하고 실행하려면 다양한 단계가 필요합니다. 일반적인 LLaVA 모델보다 더 많은 단계가 필요합니다. 다음은 설치 방법입니다:
단계 1: LLaVA-Med 저장소 가져오기
클론하기 쉽게:
LLaVA-Med 저장소를 클론하여 시작합니다. 터미널을 열고 다음을 입력합니다:
git clone https://github.com/microsoft/LLaVA-Med.git이 명령은 마이크로소프트의 저장소에서 필요한 파일을 직접 복사하여 컴퓨터로 가져옵니다.
단계 2: LLaVA-Med 디렉토리로 이동하기
필수 내비게이션:
저장소를 클론한 후에는 작업 디렉토리를 변경해야 합니다. 다음을 실행합니다:
cd LLaVA-Med이 명령을 실행하면 LLaVA-Med의 디렉토리로 이동하여 다음 단계로 진행할 수 있게 됩니다.
단계 3: 기반 설치하기 - 패키지 설치하기
의존성에 기반한 기반
복잡한 소프트웨어는 모두 종속성을 갖고 있습니다. LLaVA-Med도 예외는 아닙니다. 다음 명령을 사용하여 정상적으로 작동하기 위해 필요한 모든 것을 설치할 수 있습니다.
pip install -r requirements.txt기억하세요, 이것은 단순히 패키지를 설치하는 것뿐만 아니라, LLaVA-Med가 능력을 발휘할 수 있는 이상적인 환경을 구성하는 것입니다.
단계 4: LLaVA-Med와 상호 작용하기
마법을 목격하기 위해 샘플 프롬프트 실행:
액션을 준비하셨나요? 다음과 같이 LLaVA-Med 모델을 Python 스크립트에 통합해보세요.
from LLaVAMed import LLaVAMed모델을 실행하세요.
model = LLaVAMed()샘플 의료 텍스트 분석에 뛰어봅시다.
text_output = model.analyze_medical_text("폐렴의 증상을 설명하십시오.")
print(text_output)의료 이미지 분석에 관심이 있는 분들을 위해:
image_output = model.analyze_medical_image("경로/대상/xray.jpg")
print(image_output)이러한 명령을 실행하면 LLaVA-Med의 분석 능력이 드러납니다. 예를 들어, 의료 텍스트 분석은 폐렴의 증상, 원인 요소 및 잠재적 치료를 밝혀낼 수 있습니다. 반면, 이미지 분석은 엑스레이에서의 어떠한 차이점이나 이상을 지적할 수 있습니다. LLaVA-Med GitHub 소스 코드 (opens in a new tab)를 확인할 수 있습니다.
결론
의료 이미징에서의 인공지능은 정확성과 효율성 측면에서 매우 큰 잠재력을 보여주지만, 인간 의사를 완전히 대체할 수 있는 단계에까지는 아직 도달하지 못했습니다. 이 기술은 진단을 지원하는 강력한 도구로서 작용하지만, 가장 신뢰할 수 있고 종합적인 의료를 제공하기 위해서는 의료 전문가의 감독과 경험이 필요합니다. 따라서, 최고 품질의 의료를 제공하기 위해 AI와 인간의 전문 지식이 공존할 수 있는 협력적인 환경을 조성하는 데 집중해야합니다.
최신 LLM 뉴스를 알고 싶나요? 최신 LLM 리더보드를 확인하세요!
