Groq AI가 LLM 쿼리를 10배 더 빠르게 만드는 방법

Groq는 생성적 AI 솔루션 회사로, 혁신적인 Language Processing Unit (LPU) 추론 엔진을 통해 대규모 언어 모델 (LLM) 추론의 풍경을 재정의하고 있습니다. 이 특별히 설계된 가속기는 기존 CPU 및 GPU 아키텍처의 제한을 극복하고, LLM 처리에서 비할 데 없는 속도와 효율성을 제공합니다.
최신 LLM 뉴스를 알고 싶나요? 최신 LLM 리더보드를 확인해보세요!

LPU 아키텍처: 깊이 파고들기
Groq의 LPU 아키텍처의 핵심은 순차적인 성능에 중점을 둔 단일 코어 설계에 있습니다. 이 접근 방식은 LPU가 뛰어난 연산 밀도를 달성할 수 있도록 하며, 단일 칩에서 1 PetaFLOP/s의 최고 성능을 제공합니다. LPU의 독특한 아키텍처는 220 MB의 온칩 SRAM을 통합하여 외부 메모리 병목 현상도 제거하며, 충격적인 1.5 TB/s의 메모리 대역폭을 제공합니다.
LPU의 동기 네트워킹 기능을 통해 대규모 배포에서 매끈한 확장성을 실현할 수 있습니다. Groq의 기술은 LLM 추론에 필요한 대량의 데이터 전송을 효율적으로 처리할 수 있는 단방향 대역폭이 LPU당 1.6 TB/s인 것이 특징입니다. 또한 LPU는 FP32에서 INT4까지 다양한 정밀도 수준을 지원하여 낮은 정밀도 설정에서도 높은 정확도를 제공합니다.
Groq의 성능 측정
Groq의 LPU 추론 엔진은 다양한 벤치마크에서 꾸준히 업계 거물들을 능가하고 있습니다. Meta AI의 Llama-2 70B 모델에서 실시한 내부 테스트에서 Groq는 사용자 당 1 초당 300개의 토큰을 달성했습니다. 이는 기존 GPU 기반 시스템의 성능을 능가하여 LLM 추론 속도에서 큰 도약을 의미합니다.
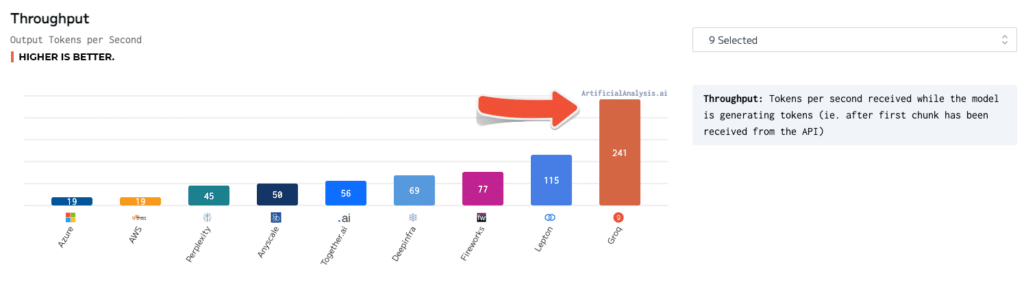
독립적인 벤치마크로도 Groq의 우수성을 검증하였습니다. ArtificialAnalysis.ai에서 실시한 테스트에서 Groq의 Llama 2 Chat (70B) API는 초당 241개의 토큰 처리량을 달성하여 다른 호스팅 제공자의 속도보다 2배 이상 빨랐습니다. Groq는 대기 시간 대 처리량, 총 응답 시간, 처리량 변동성과 같은 주요 성능 지표에서도 뛰어난 성과를 보였습니다.
이러한 숫자를 감안할 때, 사용자가 AI 기반 챗봇과 상호 작용하는 상황을 생각해보세요. Groq의 LPU 추론 엔진을 사용하면 챗봇이 1 초당 300개의 토큰을 생성하여 매우 빠른 대화를 가능하게 합니다. 반면 GPU 기반 시스템은 1 초당 50-100개의 토큰만 처리할 수 있어 지연이 느껴지고 사용자 경험이 떨어질 수 있습니다.
Groq 대 다른 AI 기술들

NVIDIA의 GPU와 비교했을 때, Groq의 LPU는 고속 LLM 추론에 중요한 INT8 성능에서 명확한 우위를 보입니다. Llama-2 70B 모델을 기준으로 한 LPU와 NVIDIA의 A100 GPU 비교 벤치마크에서, LPU는 초당 300개의 토큰 처리량으로 A100의 85개의 토큰 처리량보다 3.5배 빨랐습니다.
Groq의 기술은 ChatGPT 및 Google의 Gemini와 같은 다른 AI 모델에 비해 독보적인 성능을 보입니다. 이러한 모델에 대한 구체적인 성능 수치는 공개되어 있지 않지만, Groq의 속도와 효율성은 실제 응용 프로그램에서 그들을 능가할 수 있는 잠재력을 갖고 있음을 시사합니다.
Groq AI 사용 방법
Groq는 LPU 기술의 배포와 활용을 지원하기 위해 포괄적인 도구 및 서비스 패키지를 제공합니다. Groq Compiler를 포함한 GroqWare 스위트는 모델을 빠르게 실행할 수 있는 푸시 버튼 경험을 제공합니다. 다음은 Groq Compiler를 사용하여 모델을 컴파일하고 실행하는 예시입니다:
# 모델 컴파일
groq compile model.onnx -o model.groq
# LPU에서 모델 실행
groq run model.groq -i input.bin -o output.bin더 많은 사용자 정의를 원하는 경우, Groq는 Groq 아키텍처에 직접 손으로 코드를 작성할 수 있도록 하여 맞춤형 응용 프로그램 개발과 최대 성능 최적화를 가능하게 합니다. 다음은 간단한 행렬 곱셈을 위한 Groq 어셈블리의 손코딩 예시입니다:
; Groq LPU에서 행렬 곱셈
; 행렬 A와 B가 메모리에 로드되어 있는 것으로 가정합니다.
; 행렬 차원 로드
ld r0, [n]
ld r1, [m]
ld r2, [k]
; 결과 행렬 C 초기화
mov r3, 0
; 행렬 A의 행의 외부 루프
mov r4, 0
loop_i:
; 행렬 B의 열의 내부 루프
mov r5, 0
loop_j:
; 내적 누적
mov r6, 0
mov r7, 0
loop_k:
ld r8, [A + r4 * m + r7]
ld r9, [B + r7 * k + r5]
mul r10, r8, r9
add r6, r6, r10
add r7, r7, 1
cmp r7, r2
jlt loop_k
; 결과를 C에 저장
st [C + r4 * k + r5], r6
add r5, r5, 1
cmp r5, r2
jlt loop_j
add r4, r4, 1
cmp r4, r0
jlt loop_i개발자와 연구원은 실시간 추론 기능에 접근할 수 있는 Groq API를 통해 Groq의 강력한 기술을 활용할 수도 있습니다. 다음은 Llama-2 70B 모델을 사용하여 텍스트를 생성하는 Groq API의 예시입니다:
import groq
# Groq 클라이언트 초기화
client = groq.Client(api_key="your_api_key")
# 모델 및 매개변수 설정
model = "llama-2-70b"
prompt = "한때 멀고 먼 곳에서..."
max_tokens = 100
# 텍스트 생성
response = client.generate(model=model, prompt=prompt, max_tokens=max_tokens)
# 생성된 텍스트 출력
print(response.text)잠재적인 응용 및 영향
Groq의 LPU 추론 엔진이 가능하게 한 거의 즉각적인 응답 시간은 다양한 산업 분야에서 새로운 가능성을 여는 중입니다. 금융 분야에서는 Groq의 기술을 실시간 사기 탐지와 위험 평가에 활용할 수 있습니다. 거대한 양의 거래 데이터를 처리하고 밀리초 단위로 이상 현상을 식별함으로써 금융 기관은 사기 행위를 방지하고 고객 자산을 보호할 수 있습니다.
의료 분야에서는 Groq의 LPU가 의료 데이터의 실시간 분석을 가능하게 하여 환자 치료를 혁신할 수 있습니다. 의료 이미지 처리부터 전자 건강 기록 분석까지, Groq의 기술은 의료 전문가들이 신속하고 정확한 진단을 내릴 수 있도록 지원하여 최종적으로는 환자 결과를 개선할 수 있습니다.
자율주행 차량도 Groq의 고속 추론 능력에서 큰 이점을 얻을 수 있습니다. 센서 데이터를 처리하고 순간적인 결정을 내리는 Groq 기반의 AI 시스템은 자율 주행 차량의 안전성과 신뢰성을 향상시킴으로써 스마트한 교통의 미래를 열어갈 수 있습니다.
결론
Groq의 LPU 추론 엔진은 AI 가속화 분야에서 큰 도약을 의미합니다. 혁신적인 아키텍처, 인상적인 벤치마크 및 포괄적인 도구 및 서비스 패키지를 통해 Groq는 개발자와 기관에게 대용량 언어 모델의 가능성의 경계를 넓히는 힘을 제공하고 있습니다.
실시간 AI 추론 수요가 계속해서 증가함에 따라 Groq는 AI 파워 솔루션의 다음 세대를 가능하게 하는 선도 역할을 할 준비가 되어 있습니다. 챗봇과 가상 어시스턴트에서 자율 시스템 등 다양한 응용 분야에서 Groq의 기술의 잠재력은 광범위하고 변혁적입니다.
AI 접근의 민주화와 혁신을 위한 헌신으로 Groq는 기술적인 풍경을 혁신하는데 그치지 않고 인공 지능과 상호작용하여 혜택을 누리는 미래를 형성하고 있습니다. AI 주도 시대의 경계에서 우리가 서있는 지금, Groq의 돌파적인 기술은 앞으로 몇 년 동안 무사히 진보와 발견을 위한 촉매제로 역할할 것입니다.
최신 LLM 소식을 알고 싶으세요? 최신 LLM 리더보드를 확인해보세요!