Best 10 Vector Databases 2023: A Complete Review

Vector databases are no longer a niche topic discussed only among data scientists and database administrators. As we step into 2023, they have become a focal point for anyone dealing with complex data types like images, audio, and text. But what exactly are vector databases, and why are they gaining so much attention?
In this article, we'll demystify vector databases, dissect their pros and cons, and unveil the hype surrounding them. We'll also give you an exclusive look at the top 9 vector databases of 2023, with a special focus on open-source options. So, let's dive in!
Want to learn the latest LLM News? Check out the latest LLM leaderboard!
What is a Vector Database?
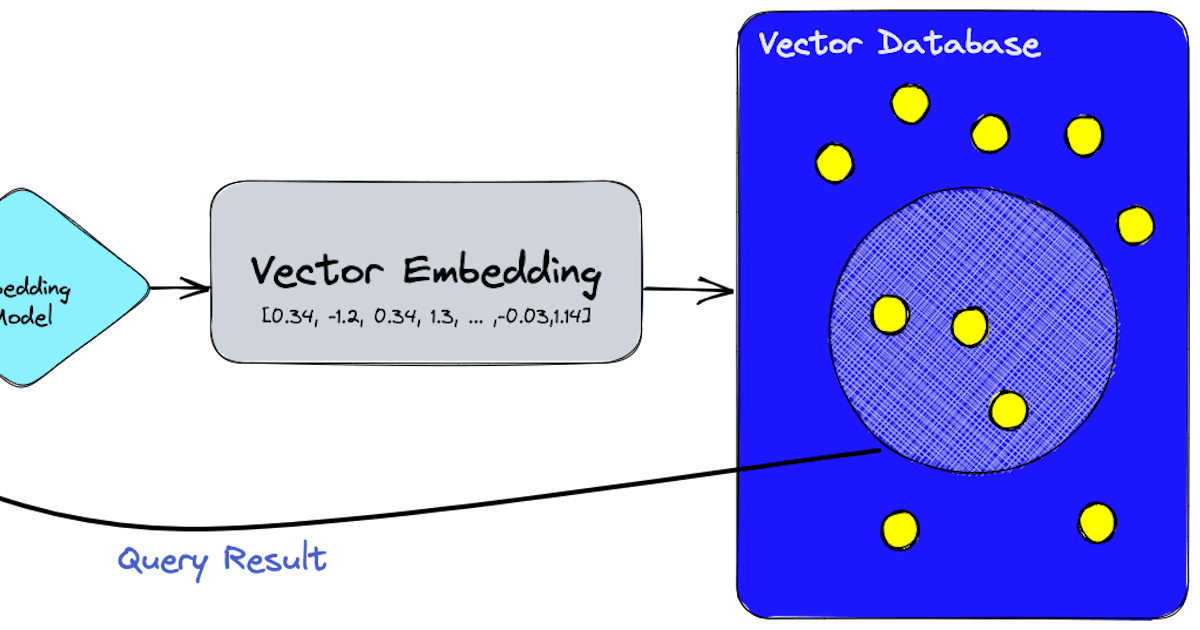
A vector database is a specialized type of database designed to handle complex data types that traditional databases struggle with. Unlike standard relational databases that store data in tables, vector databases use mathematical vectors to represent data. This allows them to efficiently manage and search through high-dimensional data like images, audio files, and textual content.
Vector databases use algorithms like k-NN (k-Nearest Neighbors) for searching through the high-dimensional data. They also employ techniques like quantization and partitioning to optimize search performance. Here's a sample prompt to search for similar images in a vector database:
SELECT * FROM images WHERE VECTOR_SEARCH(image_vector, target_vector) < 0.2;In this sample prompt, VECTOR_SEARCH is a function that calculates the similarity between image_vector and target_vector. The < 0.2 specifies the similarity threshold.
Why Vector Databases are Different?
-
High-Dimensional Data Handling: Traditional databases are not equipped to handle high-dimensional data. Vector databases fill this gap by using mathematical vectors for representation, making it easier to deal with complex data types.
-
Quick Search Capabilities: One of the standout features of vector databases is their ability to perform quick similarity searches. For example, if you have an image, a vector database can quickly find similar images in the database without having to scan each entry.
-
Scalability: As data grows, the need for databases that can scale without performance degradation becomes crucial. Vector databases are built with scalability in mind, allowing them to handle large volumes of data efficiently.
Vector Databases Review: Matching the Hype?
As with any emerging technology, vector databases have been surrounded by a considerable amount of hype. Many claim they are the next big thing in database technology, drawing parallels to the NoSQL movement that disrupted the database landscape a decade ago. But how much of this is true, and what should you be cautious about?
The Hard Truth of Vector Databases: Should You Adapt?
The hype isn't entirely unfounded. Vector databases do offer unique capabilities that traditional databases lack, especially when it comes to handling complex, high-dimensional data. However, it's essential to separate the wheat from the chaff. Not all vector databases live up to the hype, and some are more focused on marketing than on delivering robust features.
What to Watch Out For when choosing Vector Databases:
-
Overpromising and Underdelivering: Some vector databases promise the moon but fail to deliver on essential features like high availability, backup systems, and advanced data types like geospatial and datetime.
-
Complexity: While vector databases are powerful, they can also be complex to set up and manage. Make sure you have the technical expertise to handle them or be prepared to invest in training.
-
Costs: Be wary of hidden costs, especially with proprietary databases. Licensing fees can add up, and you may also need to invest in specialized hardware.
By being aware of these points, you can navigate the hype and make a more informed decision. Always remember to look beyond the marketing buzzwords and dig deep into the actual features and limitations of the database.
Advantages vs Disadvantages of Vector Databases
Vector databases have been gaining traction for their ability to handle complex data types like images, audio, and text. However, it's crucial to understand both their advantages and limitations.
Advantages of Vector Databases:
-
Efficient Similarity Search: Vector databases excel in finding the nearest neighbors in high-dimensional spaces, which is crucial for recommendation systems, image recognition, and natural language processing.
-
Scalability: Many vector databases are designed to handle large-scale data, with some even offering distributed architectures for horizontal scaling.
-
Flexibility: With support for various distance metrics and indexing algorithms, vector databases can be highly adaptable to specific use-cases.
-
Resource Intensive: High-speed search often comes at the cost of computational resources. Some databases require specialized hardware for optimal performance.
Disdvantages of Vector Databases:
-
Complexity: The plethora of algorithmic options and configurations can make vector databases challenging to set up and maintain.
-
Cost: While there are open-source options, commercial vector databases can be expensive, especially for large-scale deployments.
Top 10 Vector Databases to Consider in 202
Top Open-Source Vector Databases in 2023
1. Faiss
- Starting Price: Free (Open-Source)
- Rating: 4.7/5
- Pros:
- Exceptional GPU acceleration via CUDA
- Supports billions of vectors
- Extensive algorithmic options like IVFADC, PQ, and HNSW
- Cons:
- Requires expertise in vector quantization
- Limited to single-node deployments
Technical Details: Faiss (opens in a new tab) employs a variety of indexing techniques, including Inverted File Segmenter (IVF) and Scalar Quantizer (SQ) for efficient similarity searches. It also supports batch query processing and parallelization across multiple GPUs. The library is optimized for both L2 distance and inner product similarity, making it versatile for different use-cases.
Faiss Vector Database GitHub: https://github.com/facebookresearch/faiss (opens in a new tab)

2. Annoy (Approximate Nearest Neighbors Oh Yeah)
- Starting Price: Free (Open-Source)
- Rating: 4.5/5
- Pros:
- Utilizes forest-of-trees for partitioning vector space
- Memory-mapped file support for large-scale data
- Asymptotic complexity of queries is (O(\log N))
- Cons:
- Limited to Angular, Euclidean, Manhattan, and Hamming distance metrics
- No native support for distributed computing
Technical Details: Annoy Vector Database (opens in a new tab) builds a binary tree for each vector, partitioning the space into half-spaces. The trees are then used for efficient nearest neighbor search. It also supports multi-threaded build times and allows for saving indexes to disk, which can be memory-mapped later for large-scale similarity searches.
Annoy Vector Database GitHub: https://github.com/spotify/annoy (opens in a new tab)
3. NMSLIB (Non-Metric Space Library)
- Starting Price: Free (Open-Source)
- Rating: 4.6/5
- Pros:
- Supports a plethora of distance metrics like Cosine, Jaccard, and Levenshtein
- Employs Hierarchical Navigable Small World (HNSW) graphs for efficient search
- Optimized for both dense and sparse data vectors
- Cons:
- Steep learning curve due to extensive algorithmic options
- Limited community support and documentation
Technical Details: NMSLIB Vector Database (opens in a new tab) uses advanced algorithms like VP-trees, SW-graph, and HNSW for indexing. It also supports Approximate Nearest Neighbor (ANN) search, allowing for a balance between query performance and accuracy. The library is optimized for low-latency, high-throughput performance, making it suitable for real-time applications.
NMSLIB Vector Database GitHub: https://github.com/nmslib/nmslib (opens in a new tab)
Commercial Vector Databases: Worth the Hype?
4. Milvus
- Starting Price: Free (Open-Source)
- Rating: 4.2/5
- Pros:
- Scalability: Handles up to 100 billion vectors with sub-second latency.
- Distance Metrics: Supports Euclidean, Cosine, and Jaccard metrics. Supports index types like IVF_FLAT, IVF_PQ, and HNSW.
- Cons:
- Data Types: No support for geospatial and datetime types.
- Backup: No built-in backup system.
- Authentication: Inconsistent security features.
- Requires additional components like MySQL or SQLite for metadata storage
- Limited transactional support, not suitable for ACID-compliant applications
Advantages of Milvus: Milvus is designed for cloud-native environments and supports horizontal scaling. It employs a hybrid index system, combining tree-based and hash-based indexing methods for efficient data retrieval. The system also supports vector pruning and query filtering for more complex search conditions.
Disadvantages of Milvus: Milvus may be open-source and scalable, but it has limitations. It doesn't support advanced data types like geospatial and datetime. This is a significant gap for applications in GIS and time-series analysis. There's also no built-in backup system, which is a critical flaw. The inconsistent implementation of security features like OAuth and LDAP is another concern.

5. Pinecone
- Starting Price: Starts at $30/month
- Rating: 3.9/5
- Pros:
- Fully-managed service
- Built-in data versioning and rollback features
- Supports multi-tenancy
- Cons:
- Cost: Cost can escalate quickly for larger deployments, which can be exponential with data size.
- Limited Features: No joins, transactions, or advanced indexing.
- Documentation: Sparse technical documentation.
- Limited customization due to managed nature
Advantages of Pinecone: Pinecone employs a proprietary vector indexing algorithm that is optimized for both dense and sparse vectors. It uses a distributed, sharded architecture for scalability and offers RESTful APIs for easy integration. However, the lack of source code access could be a limitation for those who wish to extend or customize its functionalities.
Disadvantages of Pinecone: Pinecone's commercial nature comes at a high cost, especially for large datasets. It lacks support for joins and transactions, which are essential for complex data operations. The sparse technical documentation is a red flag, suggesting the product may not live up to its marketing hype.

6. Zilliz
- Starting Price: Custom Pricing
- Rating: 3.7/5
- Pros:
- REST API: Easy integration with existing applications.
- Attribute Search: Basic attribute search operations supported.
- Cloud-Based: Scalability without operational overhead.
- Cons:
- Cost: Exponential pricing with data size.
- Limited Features: No joins, transactions, or advanced indexing.
- Documentation: Sparse technical documentation.
- Lack of advanced data types like geospatial and datetime.
Advantages of Zilliz: Zilliz uses a variety of indexing algorithms, including IVF_SQ8 and NSG, and supports GPU acceleration for faster query processing. It also offers a SQL-like query language, allowing for more complex search conditions. However, the lack of transparency in its high availability features raises questions about its suitability for mission-critical applications.
Disadvantages of Zilliz: Zilliz lacks essential features like joins and transactions, making it unreliable for serious applications. The absence of high availability features, such as data replication and automatic failover, is a risk. The backup system is inadequate, requiring additional resources for data recovery.

How to Evaluate Vector Databases
When evaluating vector databases, consider the following technical aspects:
- Feature Set: Does it support joins, transactions, and advanced data types?
- Scalability: Can it handle large-scale data efficiently?
- Cost: How does the pricing scale with the features offered?
- Community Support: Is there active community support and extensive documentation?
- Benchmarking: Use performance benchmarks like query per second (QPS), latency, and throughput for comparison.
For more details, you can run tools provided by this GitHub repo (opens in a new tab) as the benchmark for Vector Databases.
Best Open-Source Vector Databases Aleternatives in 2023
7. Qdrant: The Community's Choice
- Starting Price: Free (Open Source)
- Rating: 4.5/5
Pros:
- Local and Cloud-Based: Offers both deployment options, giving you flexibility.
- In-Memory Mode: Allows for testing without spinning up a container.
- Migration-Friendly: Experiencing a lot of migrations from other tools.
Cons:
- Documentation: Could benefit from more comprehensive guides.
- Community Size: Smaller community compared to other open-source options.
- Feature Set: Still growing and may lack some advanced features.
Technical Details: Qdrant (opens in a new tab) offers both local and cloud-based options, making it a flexible choice. However, it has a smaller community and could benefit from more comprehensive documentation. While it's gaining traction, the feature set is still growing and may lack some advanced options.
Qdrant Link: https://qdrant.tech/ (opens in a new tab)

8. Cassandra/AstraDB: The Scalability King
Starting Price: Free Tier Available Rating: 4.3/5
Pros:
- Scalability: Known for handling massive throughput without falling over.
- Local and Cloud-Based: Both deployment options are available.
- Industry Recognition: Held its position in the industry for years.
Cons:
- Complexity: Steeper learning curve for new users.
- Cost: Free tier has limitations, and pricing can escalate.
- Vector Support: Not originally designed for vector data, so some features may be lacking.
Technical Details: Apache Cassandra (opens in a new tab)/DataStax AstraDB (opens in a new tab) is excellent for scalability but comes with a steep learning curve. While it offers a free tier, the limitations can quickly be reached, leading to escalating costs. It's also not originally designed for vector data, so it may lack some specialized features.
Apache Cassandra: https://cassandra.apache.org (opens in a new tab) DataStax AstraDB: https://www.datastax.com/products/datastax-astra (opens in a new tab)

9. MyScale DB: The SQL Powerhouse as the Pinecone Alternative
Starting Price: Generous Free Tier Rating: 4.1/5
Pros:
- SQL Support: Complete and extended SQL support for all data operations.
- Speed: Cloud-native OLAP database architecture for fast operations.
- Structured and Vectorized Data: Manages both in a single database.
Cons:
- Newcomer: Relatively new and may lack community support.
- Documentation: Could benefit from more technical guides.
- Complexity: SQL knowledge is a must, which may not suit all users.
Technical Details: MyScale DB (opens in a new tab) offers a generous free tier and complete SQL support, making it a strong choice for those familiar with SQL. However, being a relatively new product, it may lack extensive community support and could benefit from more technical documentation.
MyScale DB: https://myscale.com (opens in a new tab)
10. SPTAG (Space Partition Tree and Graph)
- Starting Price: Free (Open-Source)
- Rating: 4.3/5
- Pros:
- Developed by Microsoft, ensuring a level of reliability
- High-speed k-NN search capabilities
- Optimized for large-scale databases with billions of vectors
- Cons:
- Limited community support
- Documentation is not as extensive as other open-source options
Technical Details: SPTAG (opens in a new tab) uses KD-trees and Ball trees for indexing, enabling high-speed k-NN searches. It's optimized for large-scale databases and can handle billions of vectors efficiently. The algorithm also supports multi-threaded search and batch query processing.
SPTAG GitHub: https://github.com/microsoft/SPTAG (opens in a new tab)
FAQs
What are the main vector databases?
The main vector databases as of 2023 include Faiss, Annoy, NMSLIB, Milvus, Pinecone, Zilliz, Elasticsearch, Weaviate, Jina, and SPTAG.
Is there any free vector database?
Yes, there are several free, open-source vector databases available, such as Faiss, Annoy, NMSLIB, Milvus, Weaviate, Jina, and SPTAG.
Is Pinecone the best vector DB?
While Pinecone offers a fully-managed service and is easy to use, whether it's the "best" depends on your specific needs. It's not open-source and can be costly for larger deployments.
How do I choose a vector database?
Choosing a vector database depends on various factors like the type of data you're working with, the scale of your project, and your budget. Open-source options like Faiss and Annoy are excellent for those who want more control and customization, while managed services like Pinecone may be more suitable for those looking for ease of use.
Conclusion
Vector databases are an essential tool for handling complex, high-dimensional data. While they offer numerous advantages like efficient similarity search and scalability, they also come with their own set of limitations. Open-source options like Faiss and Annoy provide excellent performance and flexibility but may require a steep learning curve. On the other hand, commercial options like Pinecone offer ease of use but can be costly. Therefore, it's crucial to weigh the pros and cons carefully to choose the vector database that best suits your needs.
Want to learn the latest LLM News? Check out the latest LLM leaderboard!
