LlamaIndex vs LangChain: Comparing Powerful LLM Application Frameworks
- Name
- Lynn Mikami
Published on
Introduction
In the world of natural language processing (NLP) and large language models (LLMs), developers are constantly seeking powerful tools to build cutting-edge applications. Two prominent frameworks have emerged as frontrunners in this domain: LlamaIndex and LangChain. While both aim to simplify the integration of LLMs into custom applications, they differ in their approach and focus. In this article, we'll dive deep into the key distinctions between LlamaIndex and LangChain, helping you make an informed decision when choosing a framework for your projects.

Part 1. What is LlamaIndex?
LlamaIndex is a powerful data framework that enables you to easily connect your own data to LLMs. It provides flexible data connectors to ingest data from a variety of sources like APIs, databases, PDFs and more. This private data is then indexed into optimized representations that LLMs can access and interpret on a large scale, without needing to retrain the underlying model.
LlamaIndex empowers LLMs with a "memory" of your private data that they can leverage to provide informed, contextual responses. Whether you want to build a chatbot over your company's documentation, a personalized resume analysis tool, or an AI assistant that can answer questions about a specific knowledge domain, LlamaIndex makes it possible with just a few lines of code.
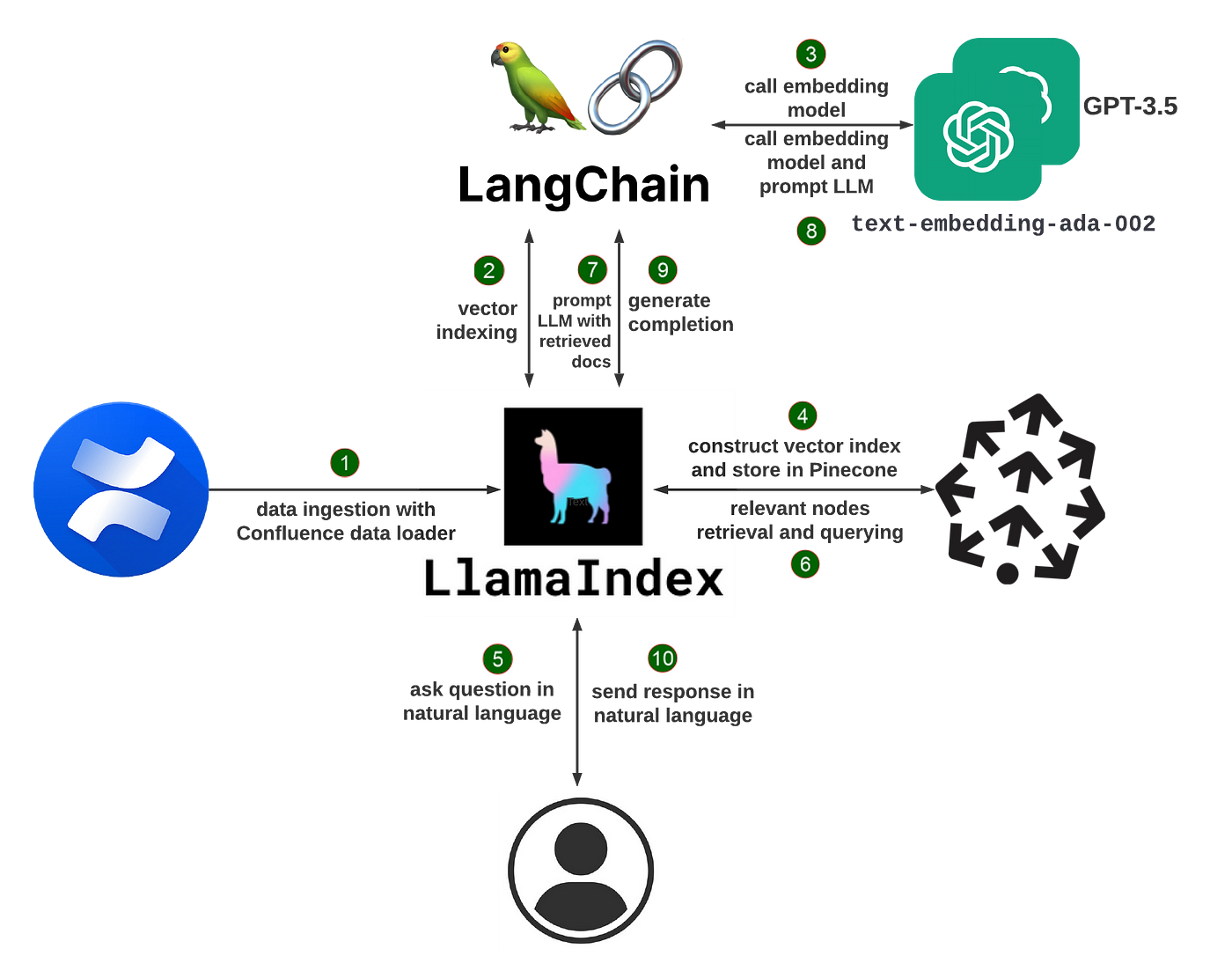
How LlamaIndex Works
At its core, LlamaIndex uses a technique called retrieval augmented generation (RAG). A typical RAG system has two key stages:
-
Indexing Stage: During indexing, your private data is efficiently converted into a searchable vector index. LlamaIndex can process unstructured text documents, structured database records, knowledge graphs, and more. The data is transformed into numerical embeddings that capture its semantic meaning, allowing for fast similarity searches later on.
-
Query Stage: When a user queries the system, the most relevant chunks of information are retrieved from the vector index based on the query's semantic similarity. These snippets, along with the original query, are passed to the LLM which generates a final response. By dynamically pulling in pertinent context, the LLM can output higher quality, more factual answers than it could with just its base knowledge.
LlamaIndex abstracts away much of the complexity of building a RAG system. It offers both high-level APIs that allow you to get started with just a few lines of code, as well as low-level building blocks for fine-grained customization of the data pipeline.
Building a Resume Chatbot with LlamaIndex
To illustrate LlamaIndex's capabilities, let's walk through building a chatbot that can answer questions about your resume.
First, install the necessary packages:
pip install llama-index openai pypdfNext, load your resume PDF and build an index:
from llama_index import TreeIndex, SimpleDirectoryReader
resume = SimpleDirectoryReader("path/to/resume").load_data()
index = TreeIndex.from_documents(resume)Now you can query the index using natural language:
query_engine = index.as_query_engine()
response = query_engine.query("What is the job title?")
print(response)The query engine will search the resume index and return the most relevant snippet as a response, e.g. "The job title is Software Engineer."
You can also engage in a back-and-forth conversation:
chat_engine = index.as_chat_engine()
response = chat_engine.chat("What did this person do in their last role?")
print(response)
follow_up = chat_engine.chat("What programming languages did they use?")
print(follow_up)The chat engine maintains conversational context, allowing you to ask follow-up questions without explicitly restating the subject.
To avoid rebuilding the index every time, you can persist it to disk:
index.storage_context.persist()And load it back later:
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)Beyond Chatbots: LlamaIndex Use Cases
Chatbots are just one of the many applications you can build with LlamaIndex. Some other examples include:
- Q&A over long documents: Ingest documents like manuals, legal contracts, or research papers and ask questions about their content
- Personalized recommendations: Build indices over product catalogs or content libraries and provide recommendations based on user queries
- Data-driven agents: Create AI assistants that can access and take actions on databases, APIs, and other tools to complete complex tasks
- Knowledge-base construction: Automatically extract structured data like entities and relationships from unstructured text to build knowledge graphs
LlamaIndex provides a flexible toolkit to build all kinds of LLM-powered apps. You can mix and match data loaders, indices, query engines, agents, and more to create custom pipelines for your use case.
Getting Started with LlamaIndex
To start building with LlamaIndex, first install the package:
pip install llama-indexYou'll also need an OpenAI API key to access the default underlying models. Set this as an environment variable:
import os
os.environ["OPENAI_API_KEY"] = "your_api_key_here"From there, you can start ingesting data and building indices! The LlamaIndex docs provide detailed guides and examples for common use cases.
As you dive deeper, you can explore the Llama Hub - a collection of community-contributed data loaders, indices, query engines, and more. You can use these plugins out of the box or as a starting point for your own custom components.
What is LangChain?
LangChain is a powerful framework for developing applications powered by language models. It enables you to easily connect your own data to LLMs and build data-aware language model applications. LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.
With LangChain, you can load data from various sources like documents, databases, APIs, and knowledge bases. This private data is then made accessible to LLMs during inference time, allowing them to leverage that context to provide informed, relevant responses. Whether you want to build a chatbot over your company's documentation, a data analysis tool, or an AI assistant that interacts with your databases and APIs, LangChain makes it possible.
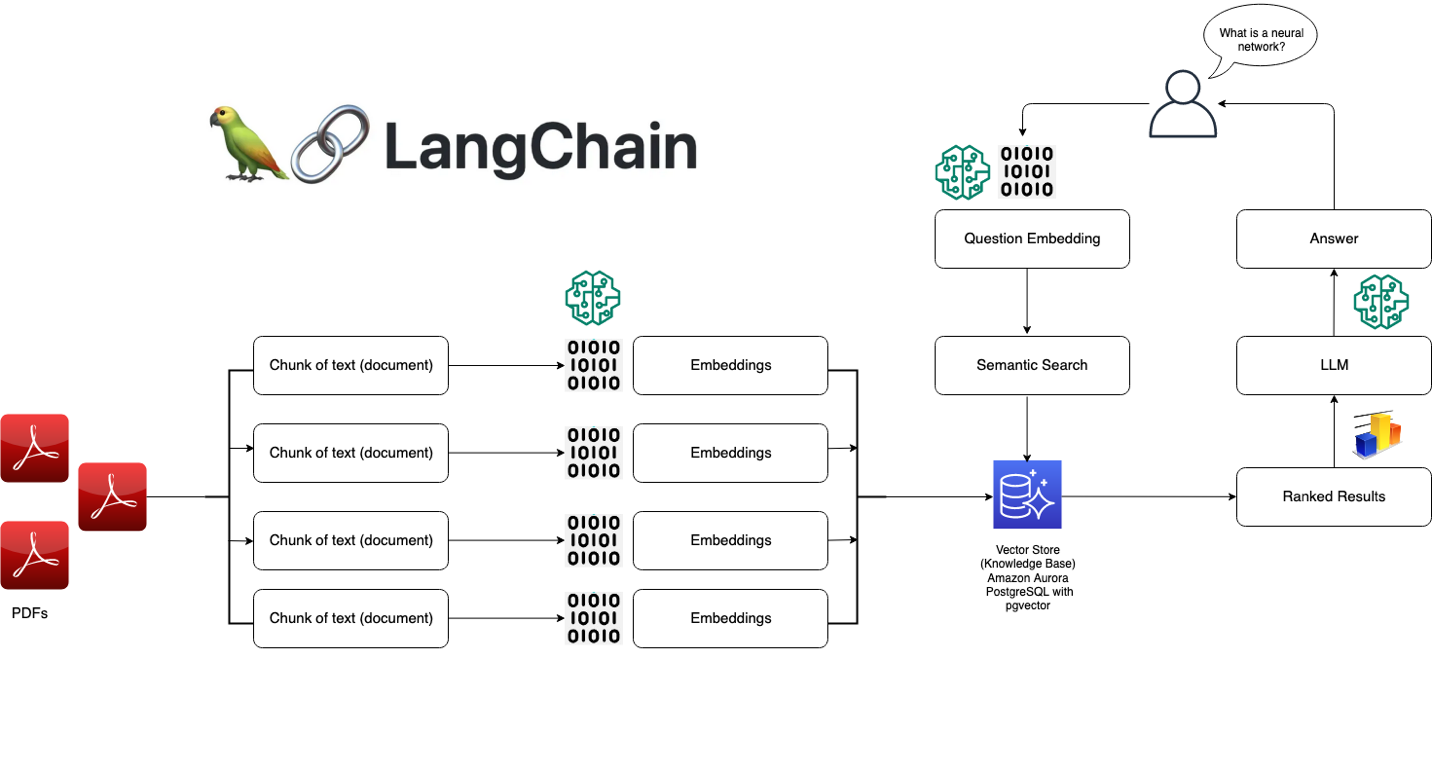
How LangChain Works
At its core, LangChain is designed around a few key concepts:
-
Prompts: Prompts are the instructions you give to the language model to steer its output. LangChain provides a standard interface for constructing and working with prompts.
-
Models: LangChain provides a standard interface for working with different LLMs and an easy way to swap between them. It supports models like OpenAI's GPT-3, Anthropic's Claude, Cohere's models, and more.
-
Indexes: Indexes refer to the way textual data is stored and made accessible to the language model. LangChain provides several indexing techniques optimized for LLMs, such as in-memory vectorstores and embeddings.
-
Chains: Chains are sequences of calls to LLMs and other tools, with the output of one step being the input to the next. LangChain provides a standard interface for chains and lots of reusable components.
-
Agents: Agents use an LLM to determine which actions to take and in what order. LangChain provides a selection of agents that can leverage tools to accomplish tasks.
With these building blocks, you can create all kinds of powerful language model applications. LangChain abstracts away much of the complexity, allowing you to focus on the high-level logic of your application.
Building a Question Answering System with LangChain
To illustrate LangChain's capabilities, let's walk through building a simple question answering system over a set of documents.
First, install the necessary packages:
pip install langchain openai faiss-cpuNext, load your data and create an index:
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
loader = TextLoader('path/to/document.txt')
index = VectorstoreIndexCreator().from_loaders([loader])Now you can query the index using natural language:
query = "What is the main topic of this document?"
result = index.query(query)
print(result)The query will search the document and return the most relevant snippet as a response.
You can also have a conversation with the data using a ConversationalRetrievalChain:
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(temperature=0)
qa = ConversationalRetrievalChain.from_llm(model,retriever=index.vectorstore.as_retriever())
chat_history = []
while True:
query = input("Human: ")
result = qa({"question": query, "chat_history": chat_history})
chat_history.append((query, result['answer']))
print(f"Assistant: {result['answer']}")This allows for a back-and-forth conversation where the model has access to the relevant context from the documents.
Beyond Q&A: LangChain Use Cases
Question answering is just one of the many applications you can build with LangChain. Some other examples include:
- Chatbots: Create conversational agents that can engage in freeform dialogue while leveraging private data
- Data analysis: Connect LLMs to SQL databases, pandas dataframes, and data visualization libraries for interactive data exploration
- Agents: Develop AI agents that can use tools like web browsers, APIs, and calculators to accomplish open-ended tasks
- App generation: Automatically generate entire applications from natural language specifications
LangChain provides a flexible set of components that can be combined in countless ways to create powerful language model applications. You can use the built-in chains and agents or create your own custom pipelines.
Getting Started with LangChain
To start building with LangChain, first install the package:
pip install langchainYou'll also need to set up any necessary API keys for the models and tools you want to use. For example, to use OpenAI's models:
import os
os.environ["OPENAI_API_KEY"] = "your_api_key_here"From there, you can start loading in data, creating chains, and building your application! The LangChain docs provide detailed guides and examples for various use cases.
As you dive deeper, you can explore the growing ecosystem of LangChain integrations and extensions. The community has built connectors to countless data sources, tools, and frameworks, making it easy to incorporate LLMs into any workflow.
Best Use Cases of LlamaIndex vs LangChain
LlamaIndex:
- Building search engines and information retrieval systems
- Creating knowledge bases and FAQ bots
- Analyzing and summarizing large document collections
- Enabling conversational search and question-answering
LangChain:
- Developing chatbots and conversational agents
- Building custom NLP pipelines and workflows
- Integrating LLMs with external data sources and APIs
- Experimenting with different prompts, memory, and agent configurations
LlamaIndex vs LangChain: Choosing the Right Framework
When deciding between LlamaIndex and LangChain, consider the following factors:
-
Project requirements: If your application primarily focuses on search and retrieval, LlamaIndex might be a better fit. For more diverse NLP tasks and custom workflows, LangChain offers greater flexibility.
-
Ease of use: LlamaIndex provides a more streamlined and beginner-friendly interface, while LangChain requires a deeper understanding of NLP concepts and components.
-
Customization: LangChain's modular architecture allows for extensive customization and fine-tuning, whereas LlamaIndex offers a more opinionated approach optimized for search and retrieval.
-
Ecosystem and community: Both frameworks have active communities and growing ecosystems. Consider exploring their documentation, examples, and community resources to gauge the level of support and resources available.
Conclusion
LlamaIndex and LangChain are powerful frameworks for building LLM-powered applications, each with its own strengths and focus areas. LlamaIndex excels in search and retrieval tasks, offering streamlined data indexing and querying capabilities. On the other hand, LangChain takes a modular approach, providing a flexible set of tools and components for building diverse NLP applications.
When choosing between the two, consider your project requirements, ease of use, customization needs, and the support offered by their respective communities. Regardless of your choice, both LlamaIndex and LangChain empower developers to harness the potential of large language models and create innovative NLP applications.
As you embark on your LLM application development journey, don't hesitate to explore both frameworks, experiment with their features, and leverage their strengths to build powerful and engaging natural language experiences.