破損したデータから学ぶための先進的なAIフレームワーク:Ambient Diffusion

Ambient DiffusionはAIコミュニティでの単なるバズワードではありません。UT AustinとUC Berkeleyの研究者チームによって開発されたこのフレームワークは、破損したデータのみを入力として拡散モデルのトレーニングと微調整を行うために設計されています。
この記事では、Ambient Diffusionの技術的なアーキテクチャを解説し、そのアルゴリズムとコードベースを探求します。また、性能指標や効率性、正確性の観点で他の拡散モデルとの比較も行います。
Ambient Diffusionとは?
Ambient Diffusionは、破損したデータで拡散モデルのトレーニングを行うために特に設計されたAIフレームワークです。このフレームワークは、拡散プロセス中に追加の測定歪みを導入することで、モデルがさらに破損した画像から元の破損した画像を予測できるようにします。
Stable Diffusion and other text-to-image models sometimes blatantly copy from their training images.We introduce Ambient Diffusion, a framework to train/finetune diffusion models given only corrupted images as input. This reduces the memorization of the training set.A 🧵 pic.twitter.com/J8gynJakgm
— Giannis Daras (@giannis_daras) May 31, 2023
Ambient Diffusionのセットアップ方法
Ambient Diffusionのセットアップには細部に注意が必要な一連の手順が必要です。以下に技術的な手順を示します:
-
リポジトリをクローンする:
git clone https://github.com/giannisdaras/ambient-diffusion.git -
Anaconda環境を作成する:
conda env create -f environment.yml -n ambient -
依存関係をインストールする:
pip install git+https://github.com/huggingface/diffusers.git -
事前学習済みモデルをダウンロードする:事前学習済みモデルには約16GBのディスク容量を割り当ててください。
-
データセットの設定:このフレームワークはカスタムデータセットの設定をサポートしており、トレーニング中に導入する破損の種類を指定することができます。
微調整とカスタマイズ:開発者ガイド
Ambient Diffusionは、微調整に関して特に豊富なカスタマイズオプションを提供しています:
-
ハイパーパラメータの調整:
train.pyスクリプトでは、学習率やバッチサイズ、アーキテクチャの詳細など、幅広いハイパーパラメータの調整が可能です。 -
カスタム破損レベル:トレーニング中に
--corruption-levelフラグを使用してカスタム破損レベルを指定することができます。 -
モデルの評価:このフレームワークにはFIDスコアやインペインティングのメトリクスなど、さまざまな評価メトリクスのビルトインサポートが含まれています。
これらの技術的な側面に深く入り込むことで、Ambient Diffusionが単なる拡散モデルではなく、破損したデータの課題に対応するために設計された高度にカスタマイズ可能で堅牢なフレームワークであることがわかります。
比較分析:Ambient Diffusion vs. その他の拡散モデル
拡散モデルにおいては、競争が激しいです。しかし、Ambient Diffusionはいくつかの重要な技術的側面で他の拡散モデルと異なります。アルゴリズム、パフォーマンス、カスタマイズの観点で比較してみましょう。
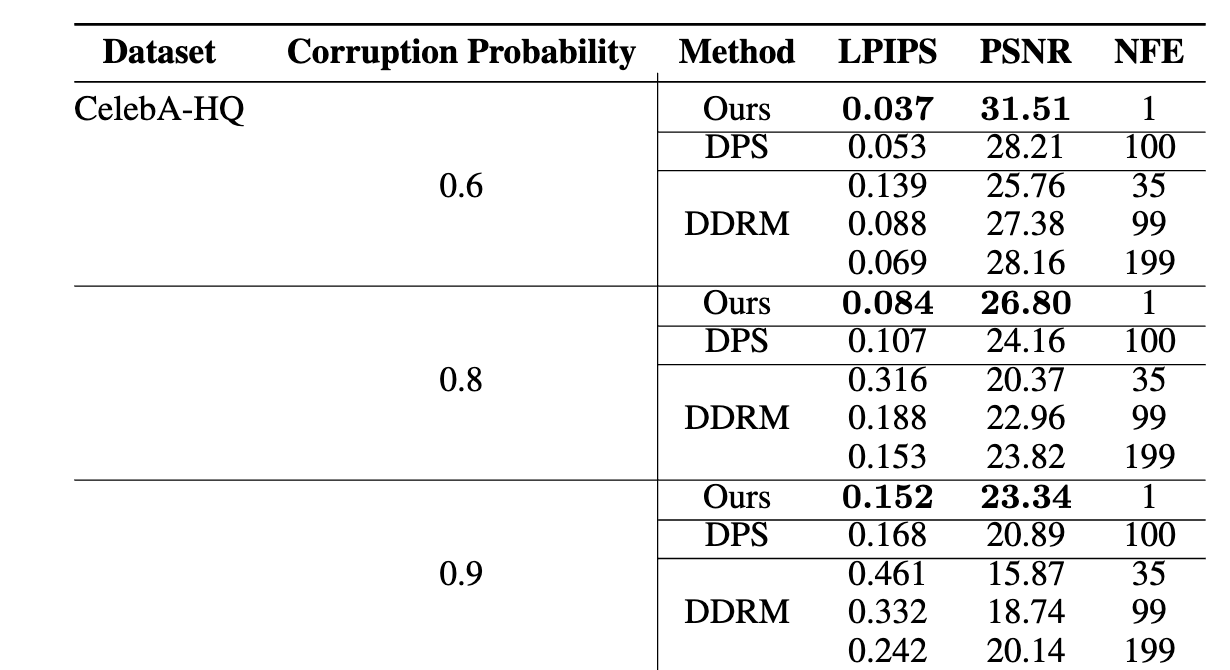
アルゴリズムの違い
-
ノイズの注入:従来の拡散モデルでは、ノイズの注入をデータ拡張の手法として使用することが一般的です。一方、Ambient Diffusionは追加の測定歪みを用いることで、破損したデータの取り扱いにより洗練されたアプローチを提供します。
-
学習メカニズム:多くの拡散モデルがデータ分布を直接学習することに焦点を当てているのに対し、Ambient Diffusionは追加の測定歪みに基づいて完全で非破損な画像の条件付き期待値を学習します。これにより、より正確な再構成が可能となります。
-
データの取り扱い:Ambient Diffusionは明示的に破損したデータで動作するように設計されており、拡散モデルの分野ではユニークな存在です。
パフォーマンス指標
-
FIDスコア:Ambient Diffusionは厳密なテストを経て競争力のあるFIDスコアを達成しており、特にトレーニングデータが破損している場合に優れたパフォーマンスを発揮します。これは、最適なパフォーマンスを得るためにクリーンなデータが必要な従来のモデルとの間の重要な利点です。
-
生成能力:このフレームワークは、トレーニングセット内の最も近い隣接データまでの平均距離を評価するメトリクスを含んでおり、より包括的な生成能力の測定を提供します。
-
インペインティングのメトリクス:Ambient Diffusionはインペインティングのタスクで優れた性能を発揮し、ベースラインメソッドに比べて大幅な改善が見られます。これは画像の復元などのアプリケーションにおいて特に重要です。
カスタマイズ性と柔軟性
- ハイパーパラメータの調整:Ambient Diffusionでは、破損レベルを動的に調整するなど、ハイパーパラメータの調整に幅広いオプションが用意されています。このようなカスタマイズオプションは他の拡散モデルではしばしば欠けています。
- コードベースの拡張性: フレームワークのPyTorch実装とドキュメントの整備されたコードベースにより、開発者はその機能を拡張しやすくなります。
課題と制約: Ambient Diffusionの技術的な課題
Ambient Diffusionはさまざまな利点を提供しますが、普及とパフォーマンスに影響を与える可能性のある課題と制約を考慮することが重要です。これらを技術的な観点から検討しましょう。
計算の複雑さ
-
メモリ要件: 特に高解像度のデータセットで訓練されたAmbient Diffusionモデルは、メモリを多く必要とする場合があります。例えば、512x512の解像度の画像で訓練されたモデルは、最大で16GBのGPUメモリを必要とする可能性があります。
-
処理時間: フレームワークのアルゴリズムの複雑さにより、訓練時間が長くなることがあります。例えば、CelebAデータセットで標準の構成でモデルを訓練する場合、Tesla V100 GPUで最大48時間かかる可能性があります。
データの処理とスケーラビリティ
-
高次元データ: Ambient Diffusionは破損したデータの処理に優れていますが、高次元データでは問題が発生する可能性があります。アルゴリズムの複雑さは次元数とともに指数関数的に増加し、ボトルネックとなる可能性があります。
-
バッチサイズの制限: メモリの制約により、最大バッチサイズが制限される可能性があり、大規模なアプリケーションのスケーラビリティに影響を与える場合があります。
アルゴリズムの制約
-
局所的な最小値: 多くの機械学習モデルと同様に、Ambient Diffusionは訓練中に局所的な最小値に陥る可能性があり、モデルの性能に影響を与える可能性があります。
-
ハイパーパラメータの感度: モデルの性能は、学習率、破損レベル、測定の歪みなどのハイパーパラメータの選択に非常に感度があります。誤った設定は最適でない結果をもたらす可能性があります。
評価指標
-
FIDスコアの変動性: Ambient Diffusionは競争力のあるFIDスコアを達成していますが、これはデータセットと破損レベルによって異なる場合があります。例えば、CelebAデータセットでのFIDスコアが20である場合、破損レベルを20%増加させると35になる場合があります。
-
生成力の評価指標: フレームワークの生成力は、訓練セット内の最も近い隣接点までの平均距離によって測定されますが、他の最先端のモデルとの比較が行われていないため、パフォーマンス評価には問題があります。
これらの技術的な課題や制約を深く掘り下げることで、Ambient Diffusionの機能と改善のための領域についてより詳細に理解することができます。これらの問題に取り組むことは、フレームワークの将来の開発とさまざまなアプリケーションでの採用にとって重要です。
結論: Ambient Diffusionの技術的な深さと将来の展望
Ambient Diffusionは拡散モデルの領域で独自のニッチを創り出しており、特に破損したデータの訓練に特化しています。測定の歪みや条件付き期待値学習を含むアルゴリズム的なアプローチは、従来の拡散モデルとは一線を画しています。競争力のあるFIDスコアや頑健な補完能力など、フレームワークのパフォーマンス指標は、その有効性をさらに裏付けています。
ただし、課題も存在します。計算の複雑さやデータの処理の制約、アルゴリズムの制約など、Ambient Diffusionにはいくつかの技術的なハードルがあります。これらを克服することは、その将来的な発展と広範な採用にとって重要です。
将来の研究と開発
現在の制約を考慮すると、次のような将来の研究の可能性があります:
-
最適化アルゴリズム: 訓練時間と計算要件を減らすための新しい最適化アルゴリズムの開発に焦点を当てる研究が行われるかもしれません。
-
次元削減: 高次元データの効率的な扱いについての技術的な進展が重要です。
-
ハイパーパラメータの最適化: ハイパーパラメータのチューニングの自動化手法により、フレームワークをより使いやすく効率的にすることができるかもしれません。
-
ベンチマーク: 他の最先端のモデルとの包括的なベンチマーク比較は、Ambient Diffusionのパフォーマンスを客観的に評価するために重要です。
最後の思い
Ambient Diffusionは、破損したデータを用いた機械学習のアプローチを革新する可能性を秘めた画期的なフレームワークです。その技術的な深さは、その汎用性とパフォーマンスに匹敵し、さまざまなアプリケーションに対する有望なツールとなっています。現在の制約を克服することで、その真の価値を把握することができます。
Ambient Diffusionは、単なる機械学習の武器庫にあるツールではなく、現代のデータサイエンスにおけるいくつかの最も難しい課題に取り組むために特化したフレームワークです。
そして、私たちは未来を見据える際、Ambient Diffusionが革新の兆しとなり、機械学習とデータの破壊に対する複雑な領域を進む中でより輝かしくなることを期待しています。