LlamaIndex vs LangChain: 強力なLLMアプリケーションフレームワークの比較
- Name
- Lynn Mikami
Published on
はじめに
自然言語処理(NLP)および大規模言語モデル(LLM)の世界では、開発者は常に最新のアプリケーションを構築するための強力なツールを求めています。このドメインで2つの主要なフレームワークが台頭しています:LlamaIndexとLangChain。両方のフレームワークは、LLMをカスタムアプリケーションに統合することを簡素化することを目指していますが、アプローチと焦点は異なります。この記事では、LlamaIndexとLangChainの主な違いについて詳しく説明し、プロジェクトに最適なフレームワークを選択する際の判断材料を提供します。

パート1. LlamaIndexとは何か?
LlamaIndexは、独自のデータをLLMに簡単に接続できる強力なデータフレームワークです。API、データベース、PDFなど、さまざまなソースからデータを取り込むための柔軟なデータコネクタを提供します。この非公開のデータは最適化された表現にインデックス化され、LLMが大規模にアクセスし解釈できるようになります。これにより、基礎となるモデルを再トレーニングする必要なく、LLMはあなたの非公開データの「メモリ」を活用して情報を提供できます。
LlamaIndexは、LLMによるコンテキストを考慮した的確な応答を提供するために、会社のドキュメントに対するチャットボット、個人向けの履歴書分析ツール、特定の知識領域に関する質問に答えるAIアシスタントなど、さまざまなアプリケーションを少ないコードで構築することが可能になります。
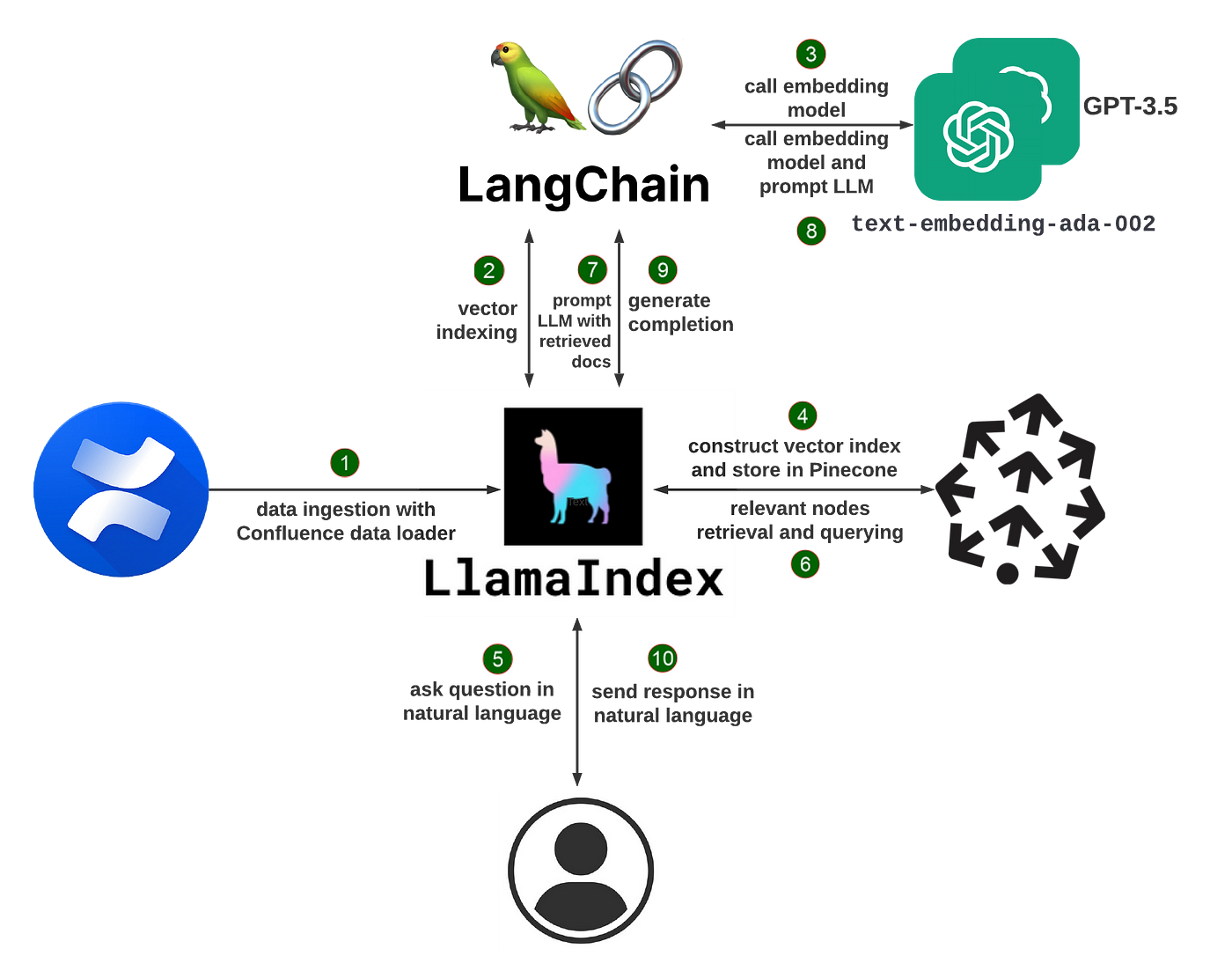
LlamaIndexの動作原理
LlamaIndexは、リトリーバル拡張生成(RAG)と呼ばれる技術を使用しています。典型的なRAGシステムには2つの主要なステージがあります:
-
インデックス化ステージ:インデックス化では、非公開データが検索可能なベクトルインデックスに効率的に変換されます。LlamaIndexは、非構造化テキストドキュメント、構造化データベースレコード、知識グラフなどを処理できます。データは、セマンティックな意味を捉える数値埋め込みに変換され、後で高速な類似性検索が可能になります。
-
クエリステージ:ユーザーがシステムにクエリを発行すると、クエリのセマンティックな類似性に基づいて、ベクトルインデックスから最も関連性の高い情報が取得されます。これらのスニペットおよび元のクエリは、LLMに渡され、最終的な応答が生成されます。関連するコンテキストを動的に取得することで、LLMはベースの知識だけでは提供できないより高品質な、より事実に基づいた回答を出力することができます。
LlamaIndexは、RAGシステムの構築の複雑さの多くを抽象化しています。数行のコードで始めるための高レベルなAPIと、データパイプラインの細かいカスタマイズのための低レベルなビルディングブロックの両方を提供しています。
LlamaIndexを使用した履歴書チャットボットの構築
LlamaIndexの機能を説明するために、履歴書に関する質問に答えるチャットボットの構築手順を説明します。
まず、必要なパッケージをインストールします:
pip install llama-index openai pypdf次に、履歴書のPDFをロードしてインデックスを構築します:
from llama_index import TreeIndex, SimpleDirectoryReader
resume = SimpleDirectoryReader("path/to/resume").load_data()
index = TreeIndex.from_documents(resume)これで自然言語を使用してインデックスをクエリできます:
query_engine = index.as_query_engine()
response = query_engine.query("何の仕事ですか?")
print(response)クエリエンジンは、履歴書のインデックスを検索し、関連性の高いスニペットを応答として返します。例:「仕事のタイトルはソフトウェアエンジニアです。」
また、対話形式で会話を行うこともできます:
chat_engine = index.as_chat_engine()
response = chat_engine.chat("この人は前職で何をしましたか?")
print(response)
follow_up = chat_engine.chat("どのプログラミング言語を使用しましたか?")
print(follow_up)チャットエンジンは対話コンテキストを維持し、対象を明示的に再述することなく追加の質問をすることができます。
インデックスを毎回再構築するのを避けるために、ディスクに保存することもできます:
index.storage_context.persist()後でそれをロードすることもできます:
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)チャットボット以外のLlamaIndexのユースケース
チャットボットは、LlamaIndexで構築できる多くのアプリケーションのうちの一つです。他の例には以下のようなものがあります:
- 長文のQ&A:マニュアル、法的契約、研究論文などのドキュメントを取り込み、内容に関する質問をする
- 個別の推奨:製品カタログやコンテンツライブラリに対してインデックスを構築し、ユーザーのクエリに基づいて推奨を提供する
- データ駆動型エージェント:データベース、API、その他のツールにアクセスし、複雑なタスクを完了するためのAIアシスタントを作成する
- 知識ベースの構築:非構造化テキストからエンティティや関係などの構造化データを自動的に抽出して知識グラフを構築する
LlamaIndexは、さまざまな種類のLLMを活用したアプリケーションを構築するための柔軟なツールキットを提供しています。データローダー、インデックス、クエリエンジン、エージェントなどの要素を組み合わせて、ユースケースに合わせたカスタムパイプラインを作成することができます。
LlamaIndexの使い方
LlamaIndexでビルドを開始するには、まずパッケージをインストールします:
pip install llama-indexまた、デフォルトの基礎となるモデルにアクセスするためにOpenAIのAPIキーが必要です。これを環境変数として設定します:
import osos.environ["OPENAI_API_KEY"] = "ここにあなたのAPIキーを入力する"
それから、データを組織することやインデックスを構築することができます!LlamaIndexのドキュメントは、一般的なユースケースのための詳細なガイドと例を提供しています。
さらに掘り下げると、コミュニティによって貢献されたデータローダーやインデックス、クエリエンジンなどの機能がまとめられたLlama Hubを探索することができます。これらのプラグインをそのまま使用するか、カスタムコンポーネントの出発点として利用することができます。
### LangChainとは何ですか?
LangChainは、言語モデルに基づくアプリケーションを開発するためのパワフルなフレームワークです。LangChainを使用すると、自分自身のデータをLLMsと接続し、データに対応した言語モデルアプリケーションを簡単に構築することができます。LangChainは、チェーンに対する標準インタフェース、他のツールとの多くの統合、および一般的なアプリケーションに対するエンドツーエンドのチェーンを提供します。
LangChainを使用すると、ドキュメント、データベース、API、ナレッジベースなどさまざまなソースからデータを読み込むことができます。このプライベートデータは推論時にLLMsにアクセス可能になり、それに基づいたコンテキストを活用して情報提供を行うことができます。自社のドキュメンテーション上でチャットボットを構築したり、データ分析ツールやデータベースやAPIと対話するAIアシスタントを構築したりする場合、LangChainを使用することができます。
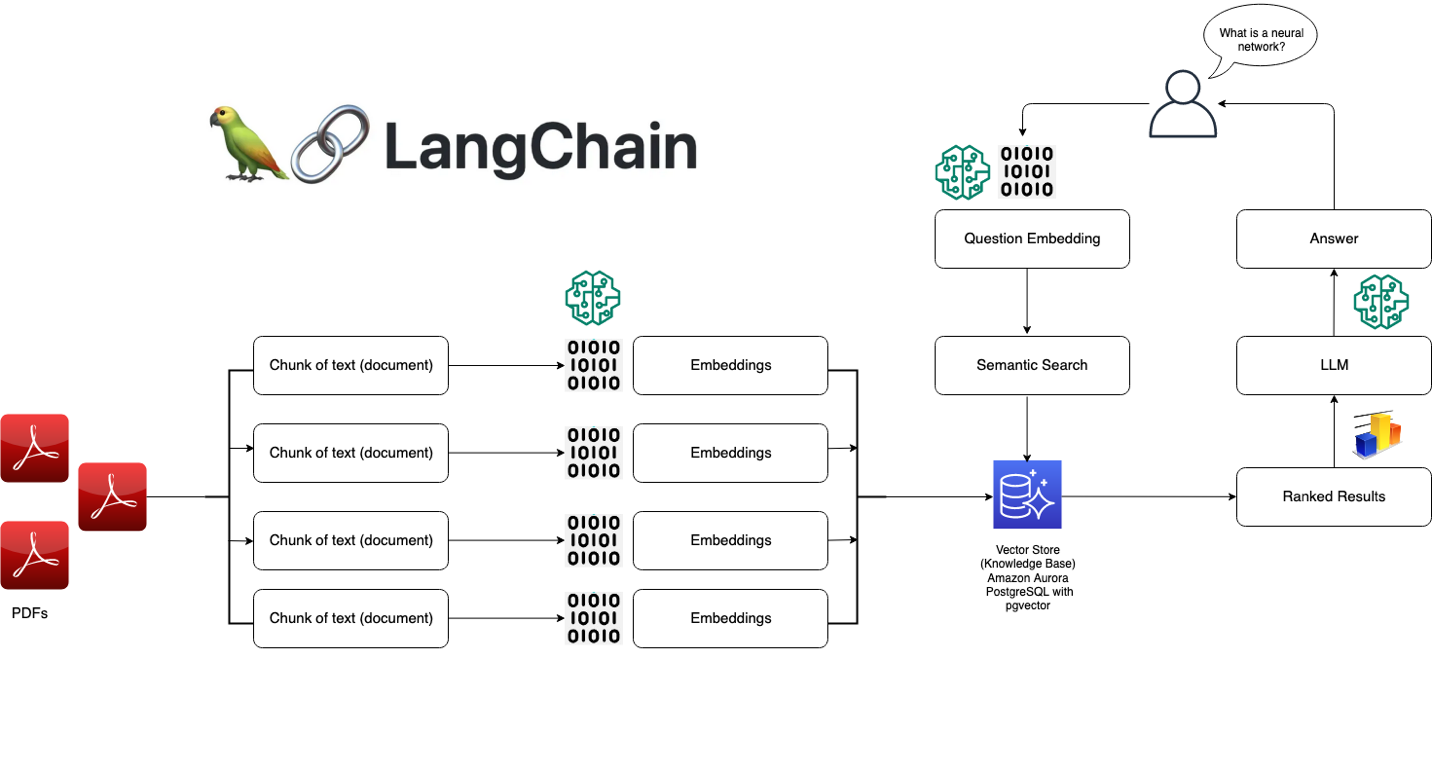
### LangChainの動作方法
LangChainは、いくつかのキーコンセプトを中心に設計されています。
1. プロンプト: プロンプトは、言語モデルに出力を誘導するための指示です。LangChainは、プロンプトの作成と操作のための標準インタフェースを提供します。
2. モデル: LangChainは、異なるLLMsとの作業に対する標準インタフェースを提供し、簡単に切り替える方法も提供しています。OpenAIのGPT-3、AnthropicのClaude、Cohereのモデルなど、さまざまなモデルをサポートしています。
3. インデックス: インデックスは、テキストデータが格納され、言語モデルにアクセス可能になる方法を指します。LangChainは、LLMsに最適化されたいくつかのインデックス技術を提供しています。
4. チェーン: チェーンは、LLMsや他のツールへの呼び出しのシーケンスであり、1つのステップの出力が次のステップの入力となります。LangChainは、チェーンと多くの再利用可能なコンポーネントに対する標準インタフェースを提供します。
5. エージェント: エージェントは、LLMを使用してどのアクションを実行し、どの順序で実行するかを決定します。LangChainには、タスクを達成するためにツールを活用できるエージェントの選択肢があります。
これらの要素を活用して、さまざまなパワフルな言語モデルアプリケーションを作成することができます。LangChainは、複雑さの多くを抽象化し、アプリケーションの高レベルのロジックに集中することができます。
### LangChainを使用して質問応答システムを構築する
LangChainの機能を説明するために、ドキュメント群に対する簡単な質問応答システムの構築手順を見ていきましょう。
まず、必要なパッケージをインストールしてください:
pip install langchain openai faiss-cpu
次に、データを読み込んでインデックスを作成します:
```python
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
loader = TextLoader('path/to/document.txt')
index = VectorstoreIndexCreator().from_loaders([loader])これで、自然言語を使用してインデックスをクエリすることができます:
query = "このドキュメントの主要なトピックは何ですか?"
result = index.query(query)
print(result)このクエリはドキュメントを検索し、最も関連性の高いスニペットを返します。
また、ConversationalRetrievalChainを使用してデータと対話を行うこともできます:
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(temperature=0)
qa = ConversationalRetrievalChain.from_llm(model,retriever=index.vectorstore.as_retriever())
chat_history = []
while True:
query = input("人間: ")
result = qa({"question": query, "chat_history": chat_history})
chat_history.append((query, result['answer']))
print(f"アシスタント: {result['answer']}")これにより、関連書類からのコンテキストをモデルが利用できる対話型の会話が行われます。
Q&Aを超えて:LangChainのユースケース
質問応答は、LangChainで構築できる多くのアプリケーションの一例に過ぎません。他の例には、以下のようなものがあります:
- チャットボット:プライベートデータを活用しながら、自由な対話を行うことができる会話エージェントを作成する
- データ分析:LLMsをSQLデータベース、pandasデータフレーム、データ可視化ライブラリに接続して、対話型データ探索を行う
- エージェント:ウェブブラウザ、API、計算機などのツールを活用して、開放的なタスクを達成できるAIエージェントを開発する
- アプリ生成:自然言語の仕様からアプリケーション全体を自動生成する
LangChainは、パワフルな言語モデルアプリケーションを作成するための柔軟なコンポーネントを提供しています。組み込みのチェーンとエージェントを使用するか、独自のカスタムパイプラインを作成することができます。
LangChainでの始め方
LangChainを使って開発を始めるには、まずパッケージをインストールしてください:
pip install langchainまた、使用するモデルやツールのために必要なAPIキーを設定する必要があります。例えば、OpenAIのモデルを使用する場合は以下のように設定します:
import os
os.environ["OPENAI_API_KEY"] = "ここにあなたのAPIキーを入力する"それから、データを読み込み、チェーンを作成し、アプリケーションを構築することができます!LangChainのドキュメントは、さまざまなユースケースに対する詳細なガイドと例を提供しています。
さらに掘り下げると、LangChainの統合や拡張の成長するエコシステムを探索することもできます。コミュニティは、無数のデータソース、ツール、フレームワークに対する接続子を構築しており、LLMsをワークフローに組み込むのが簡単になります。
LlamaIndex vs LangChainの主なユースケース
LlamaIndex:
- 検索エンジンや情報検索システムの構築
- 知識ベースやFAQボットの作成
- 大規模なドキュメントコレクションの分析と要約
- 会話型検索や質問応答の実現
LangChain:
- チャットボットや対話エージェントの開発
- カスタムのNLPパイプラインやワークフローの構築
- 外部データソースやAPIとのLLMの統合
- 異なるプロンプト、メモリ、エージェントの設定を試す
LlamaIndexとLangChainの比較: 正しいフレームワークの選択
LlamaIndexとLangChainの選択には以下の要素を考慮してください:
-
プロジェクトの要件: 検索と取得に主眼を置く場合は、LlamaIndexの方が適しています。多様なNLPタスクとカスタムワークフローには、LangChainの方が柔軟性があります。
-
使用の容易さ: LlamaIndexはより簡略化された初心者向けインターフェースを提供しますが、LangChainはNLPの概念とコンポーネントの深い理解が必要です。
-
カスタマイズ: LangChainのモジュラーアーキテクチャは、多様なカスタマイズや微調整を可能にしますが、LlamaIndexは検索と取得に最適化された意見主張の強いアプローチを提供します。
-
生態系とコミュニティ: 両方のフレームワークには、アクティブなコミュニティと成長中の生態系があります。サポートとリソースのレベルを把握するために、ドキュメント、例、コミュニティのリソースを探索することを検討してください。
結論
LlamaIndexとLangChainは、それぞれ独自の強みと焦点を持つ、LLMを活用したアプリケーションのパワフルなフレームワークです。LlamaIndexは検索と取得のタスクで優れた性能を発揮し、データのインデックス作成とクエリ機能を効率的に提供します。一方、LangChainはモジュラーなアプローチを採用しており、多様なNLPアプリケーションのための柔軟なツールセットとコンポーネントを提供します。
選択する際には、プロジェクトの要件、使用の容易さ、カスタマイズのニーズ、およびそれぞれのコミュニティが提供するサポートを考慮してください。どちらを選んでも、LlamaIndexとLangChainの両方は開発者に大規模な言語モデルの可能性を活用し、革新的なNLPアプリケーションを作成する力を与えてくれます。
LLMアプリケーション開発の旅に乗り出す際には、両方のフレームワークを探索し、その特徴を実験し、パワフルかつ魅力的な自然言語体験を構築するために彼らの強みを活用することを躊躇しないでください。