Recuperação Aprimorada por Geração (RAG): Explicado Detalhadamente
- Name
- Jennie Rose
Published on
Se você está navegando na complexa paisagem dos Modelos de Aprendizado de Linguagem (LLMs), não pode deixar de considerar o RAG, abreviação de Recuperação Aprimorada por Geração. Essa técnica é um divisor de águas, oferecendo uma abordagem refinada para o aprendizado de máquina e processamento de linguagem natural. Este guia tem como objetivo ser seu recurso definitivo para entender e implementar o RAG em LLMs.
Desde cientistas de dados até novatos em aprendizado de máquina, dominar o RAG pode ser sua arma secreta. Abordaremos sua arquitetura, sua integração aos LLMs, sua comparação com o ajuste fino e sua aplicação em plataformas como langChain. Então, vamos começar!
O que é o RAG?
Definição do RAG
Recuperação Aprimorada por Geração (RAG) é um modelo avançado de aprendizado de máquina que combina as capacidades de dois tipos distintos de modelos: um recuperador e um gerador. Em essência, o recuperador examina um conjunto de dados em busca de informações relevantes, que então são utilizadas pelo gerador para construir uma resposta detalhada e coerente.
- Recuperador: Utiliza algoritmos como BM25 ou Recuperador Denso para analisar um corpus e encontrar documentos relevantes.
- Gerador: Geralmente é um modelo baseado em transformers, como BERT, GPT-2 ou GPT-3, que gera texto semelhante ao humano com base nos documentos recuperados.
Como o RAG Funciona: Uma Visão Técnica Detalhada
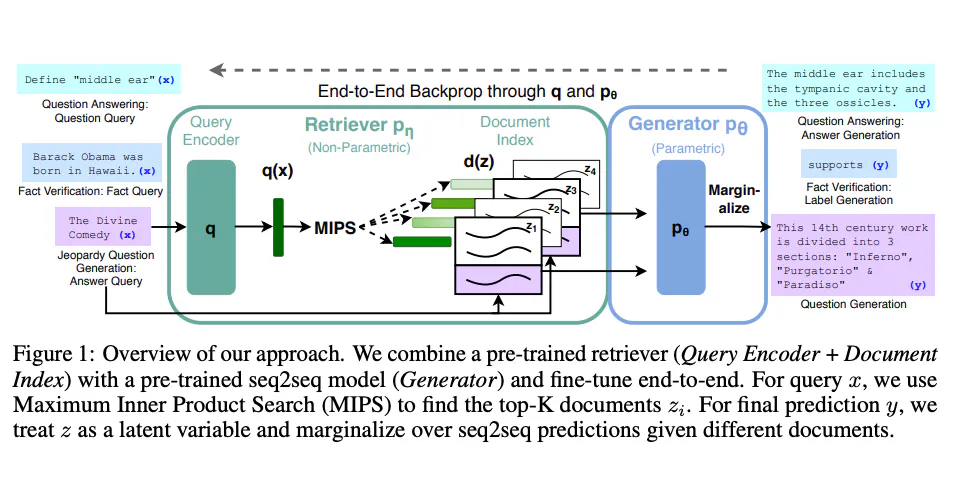
O modelo RAG opera em um processo de duas etapas:
- Etapa de Recuperação: Dada uma consulta, o recuperador examina o corpus e recupera os
Ndocumentos mais relevantes. Isso é frequentemente feito usando uma métrica de similaridade, como similaridade de cosseno.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
vetorizador = TfidfVectorizer()
matriz_tfidf = vetorizador.fit_transform(corpus)
vetor_consulta = vetorizador.transform([consulta])
pontuacoes_similaridade = cosine_similarity(vetor_consulta, matriz_tfidf)- Etapa de Geração: O gerador usa esses
Ndocumentos e a consulta original para gerar uma resposta coerente.
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base")
recuperador = RagRetriever.from_pretrained("facebook/rag-token-base", index_name="exact", use_dummy_dataset=True)
modelo = RagTokenForGeneration.from_pretrained("facebook/rag-token-base", recuperador=recuperador)
ids_entrada = tokenizer(consulta, return_tensors="pt").input_ids
resultados = modelo.generate(ids_entrada)
gerado = tokenizer.decode(resultados[0], skip_special_tokens=True)Ao combinar essas duas etapas, o RAG pode responder a consultas complexas com respostas detalhadas e contextualmente relevantes.
Como Usar o RAG para LLMs
Configurando o RAG para LLMs
Para implementar o RAG em LLMs, você precisará:
- Um corpus: Isso pode ser na forma de um banco de dados SQL, Elasticsearch ou um simples arquivo JSON.
- Um framework de aprendizado de máquina: TensorFlow ou PyTorch são comumente usados.
- Recursos computacionais: CPU/GPU adequados para treinamento e inferência.
Etapas para Implementar o RAG em LLMs
Aqui está um guia passo a passo para implementar o RAG em seu LLM:
- Preparação dos Dados: Seu corpus precisa estar em um formato pesquisável. Se estiver usando o Elasticsearch, certifique-se de indexar seus dados.
curl -X PUT "localhost:9200/meu_indice"-
Seleção do Modelo: Escolha seus modelos de recuperador e gerador. Você pode usar modelos pré-treinados ou treinar os seus próprios.
-
Treinamento: Treine os modelos de recuperador e gerador. Isso é frequentemente feito separadamente.
recuperador.train()
gerador.train()- Integração: Combine o recuperador e o gerador treinados em um único modelo RAG.
modelo_rag = ModeloRag(recuperador, gerador)- Teste: Valide o desempenho do modelo usando várias métricas como BLEU para qualidade da geração de texto e recall@k para precisão da recuperação.
Ao seguir essas etapas, você terá um modelo RAG robusto que pode ser integrado a vários LLMs para obter um desempenho superior.
Funções de Utilidade no RAG para LLMs
Para avaliar seu modelo RAG, você pode usar funções de utilidade como get_retrieval_score(), que avaliam o desempenho do recuperador. Essa função normalmente usa métricas como Precision@k ou NDCG para avaliação.
from sklearn.metrics import ndcg_score
ndcg = ndcg_score(valores_reais, pontuacoes)Essa função pode ser inestimável para aprimorar o desempenho do recuperador, garantindo que ele recupere os documentos mais relevantes do corpus.
RAG vs Ajuste Fino
O que Distingue o RAG e o Ajuste Fino?
Embora tanto o RAG quanto o ajuste fino visem aprimorar o desempenho dos Modelos de Aprendizado de Linguagem (LLMs), eles abordam a tarefa de maneiras diferentes. O ajuste fino modifica um modelo pré-treinado existente para se adaptar melhor a uma tarefa ou conjunto de dados específico. O RAG, por outro lado, combina mecanismos de recuperação e geração para responder a consultas complexas.
- Ajuste Fino: Envolve a ajuste dos pesos de um modelo pré-treinado durante a fase de treinamento em um conjunto de dados específico.
- RAG: Combina um recuperador e um gerador para buscar informações relevantes em um corpus e depois gerar uma resposta coerente.
Comparação Técnica: RAG vs Ajuste Fino
- Carga Computacional:
- RAG: Requer mais recursos computacionais, pois envolve dois modelos separados.
- Ajuste Fino: Geralmente menos intensivo computacionalmente.
- Flexibilidade:
- RAG: Altamente flexível, pode se adaptar a vários tipos de consultas.
- Fine-Tuning: Limitado à tarefa específica para a qual foi ajustado.
- Requisitos de Dados:
- RAG: Requer um corpus grande e bem estruturado para recuperação.
- Fine-Tuning: Necessita de um conjunto de dados específico da tarefa para treinamento.
- Complexidade de Implementação:
- RAG: Mais complexo devido à integração de dois modelos.
- Fine-Tuning: Relativamente simples.
Código de Exemplo: RAG vs Fine-Tuning
Para RAG:
# Usando a biblioteca Transformers da Hugging Face
from transformers import RagModel
rag_model = RagModel.from_pretrained("facebook/rag-token-nq")Para Fine-Tuning:
# Ajustando um modelo BERT usando PyTorch
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
model.train()Ao entender essas diferenças, você pode fazer uma escolha informada sobre qual abordagem se adequa melhor ao seu projeto de LLM.
Como Usar RAG para Aplicações de LLM
Incorporando RAG em LLMs Existentes
Se você já possui um LLM e deseja incorporar o RAG, siga estas etapas:
-
Identifique o Caso de Uso: Determine o que você deseja alcançar com o RAG - seja melhor resposta a perguntas, sumarização ou algo mais.
-
Alinhamento de Dados: Certifique-se de que seu corpus existente seja compatível com o recuperador que você planeja usar no RAG.
-
Integração de Modelos: Integre o modelo RAG à arquitetura existente do seu LLM.
# Exemplo usando PyTorch
class MyLLMWithRAG(nn.Module):
def __init__(self, my_llm, rag_model):
super(MyLLMWithRAG, self).__init__()
self.my_llm = my_llm
self.rag_model = rag_model- Testes e Validação: Execute testes para validar que o modelo RAG está melhorando o desempenho do seu LLM.
Armadilhas Comuns e Como Evitá-las
- Corpus Inadequado: Verifique se o seu corpus é grande e diversificado o suficiente para o recuperador encontrar documentos relevantes.
- Modelos Incompatíveis: O recuperador e o gerador devem ser compatíveis em termos de tipos e dimensões de dados.
Ao integrar cuidadosamente o RAG em suas aplicações de LLM, você pode aprimorar significativamente suas capacidades e desempenho.
Como Usar RAG com langChain
O que é langChain?
langChain é uma plataforma descentralizada para modelos de linguagem. Ela permite a integração de vários modelos de aprendizado de máquina, incluindo RAG, para oferecer serviços aprimorados de processamento de linguagem natural.
Etapas para Implementar o RAG no langChain
-
Instalação: Instale o SDK do langChain e configure seu ambiente de desenvolvimento.
-
Upload do Modelo: Faça o upload do seu modelo RAG pré-treinado para a plataforma langChain.
langChain upload --model my_rag_model- Integração da API: Use a API do langChain para integrar o modelo RAG em seu aplicativo.
from langChain import RagService
rag_service = RagService(api_key="sua_chave_de_api")- Execução de Consultas: Execute consultas por meio da plataforma langChain, que utilizará seu modelo RAG para gerar respostas.
response = rag_service.query("Qual é o significado da vida?")Ao seguir essas etapas, você pode integrar o RAG ao langChain de forma transparente, aproveitando a arquitetura descentralizada da plataforma para um desempenho e escalabilidade aprimorados.
Conclusão
RAG é uma ferramenta poderosa que pode elevar significativamente as capacidades dos Modelos de Aprendizado de Linguagem. Seja para integrá-lo a LLMs existentes, compará-lo com métodos de ajuste fino ou até mesmo usá-lo em plataformas descentralizadas como langChain, entender o RAG pode lhe dar uma vantagem distinta. Com seus mecanismos duplos de recuperação e geração, o RAG oferece uma abordagem refinada para consultas complexas, tornando-o um recurso inestimável no campo da aprendizado de máquina e processamento de linguagem natural.
Perguntas Frequentes
O que é RAG em LLM?
RAG, ou Retrieval-Augmented Generation, é uma técnica que combina um recuperador e um gerador para responder a consultas complexas em Modelos de Aprendizado de Linguagem.
Qual é a diferença entre rag e LLM?
RAG é uma técnica específica usada para aprimorar as capacidades de LLMs. Não é um modelo independente, mas sim um componente que pode ser integrado a LLMs existentes.
Como avaliar um rag LLM?
As métricas de avaliação, como BLEU para qualidade de geração de texto e recall@k para precisão de recuperação, são comumente utilizadas.
O que é rag vs fine-tuning?
RAG combina mecanismos de recuperação e geração, enquanto o fine-tuning envolve a modificação de um modelo existente para se adaptar a uma tarefa específica.
Quais são os benefícios do rag LLM?
RAG permite respostas mais refinadas e contextualmente relevantes, o que o torna altamente eficaz para consultas complexas.
